Given two images A and B both with people can we take a face from B and swap it on to a face from A? This task is known as face swapping in the literature and my project was to see if I could implement an approach that required minimal additional information and generalized to quite disparate pairs of images. At a high level my approach is to identify the key points of the faces in each image. Then warp and superimpose the face from image B onto image A. The resulting image would have clear artifacts. Some of which like the difference in lighting may be handled by classical techniques; however, more complex differences like the different poses of the face cannot. For this reason I employ a UNet to map the raw composition to a harmonized version. The losses are a discriminative one for realistic blending as well as regularization to ensure the spirit of the composition is maintained. After implementing this method I found a variety of papers that actually solved similar problems. I made some alterations to the details of my method as a result, and also compare the benefits of various approaches I surveyed.
Introduction
One of the reasons I chose to work on this project is it brings an a large spectrum of topics in this class as well as cutting edge research outside of it. The first part of the pipeline comes from project 5. We draw bounding boxes around the two faces we'd like to swap then run the model we trained in that project to identify the set of key points. From there we may apply what we worked on in Project 3 to warp one face into the geometry of another and super impose it. We may refer to the result as a composite image. However, we need to incorporate some sort of blending to avoid strong seam artifacts and make the swap believable. One approach is as we did in project 2. Using pyramids and classical multi resolution blending techniques. We show results for this later on, but a fundamental challenge here is that while it smooths out the edges created by superimposition it does not deal with the warping artifacts. In particular if there's a significant difference in geometry this approach will not take care of the weirdly shaped features. For example suppose in one image the person's mouth is open and the other it's closed. A classical solution can't really deal with this as it will simply stretch the closed mouth lips over the open mouth surface. Furthermore, even the smoothed edges are unrealistic as most people don't have that strong a skin tone gradient. I thought a GAN may be capable of lessening such issues. The U-Net generator which takes as input the raw composite image may synthesize areas of the image missing from the single perspective it has available. The U-Net architecture and it's skip connections allow the model to maintain the high frequency features of the original image but dig down into the broad semantic features as well and resolve any differences there. A discriminator would try to tell apart generated blendings versus real images. An obvious issue here is that the generator could just replace the swapped face with the original one if we don't constraint it otherwise. To prevent this we add regularization. Choice of regularization is tricky however. A simple L2 pixel loss would make it hard for the the generator to learn the geometric adjustments necessary. What I used was a combination of various ideas. One was outside of the face hull an L2 pixel loss. This encourages the generator to retain the context but heavily edit the face itself if need be. Another was to maintain a pretrained Resnet-18 embedding (L2 loss in the latent space). And finally to maintain the first and second moment color features.
Related Work
After implementing this idea I went back to do a literature review to see in case people had tackled similar problems. Indeed I was met with a number of papers in the last few years which surprisingly or perhaps unsurprisingly took very similar approaches to what I had implemented. I started with Image Harmonization, the idea of replacing a section of one image with the direct set of corresponding pixels from another image. Then altering the colors so that the implanted image is in harmony with its background. Similar to my idea this paper used a UNet architecture to synthesize the harmonized image with classical losses to regularize the output so it preserves the content of the original image. GP-GAN is one step closer to what I had in mind using a discriminator to produce an adversarial loss term. It also uses some of the classical loss terms to regularize the output. They made the observation that the GAN alone often produces blurry low resolution images. Thus motivated a second classical step of solving a Gaussian Poisson equation to get the gradients to line up with the original image while preserving the low frequency features of the GAN output. My concern is that the implanted image may need to fundamentally change to fit in the original image. And these classical constraints which enforce pixel-wise consistency seem to prevent that from happening effectively. Closest to my idea is FSGAN which was designed specifically for the idea I set to work on. Admittedly they take a far more involved and well thought approach then I did. For example, they separated the process into steps of segmentation, inpainting, and blending as opposed to trying to do all of these things implicitly in one network. They also used some classical regularization terms like the previous papers, but in addition we see some deep regularization methods. For example having the hidden layer activation of a neural network not stray too far from its original values.
Method

Our baseline method is depicted in above. We begin by selecting two images. One image is the base image containing the base face and the target image which contains the target face. In our example the top image is the base image and the bottom is the target image. For both faces we apply the model from Project 5 to identify key points and then perform a Delauney triangulation. Then we use the work from Project 3 to warp the target image triangles into the geometry of the base image. The raw composition entirely replaces the base image contents within the facial region with the warped target image. Of course this leaves some glaring artifacts along the edges and so the last step is blending. Our baseline is multi resolution blending which we implemented in Project 2, and you can see for this example that smooths out the edges. However, the face as a whole isn't entirely believable. There remains an unnatural gradient in skin color. Further this was actually an ideal example, with the two individuals having similar facial orientations. For example in the evaluation set (scroll to the bottom!) we can see that for 5 randomly selected images some other issues come up. In the 4th image the target face has mouth closed whereas the base image has it open. A classical warping solution will not be able to inpaint or imagine what the opened mouth may look like for the target face. In the 5th image the target image's face is partially occluded by their hand and as a result that artifact exists even in the blended result. Our approach must know to get rid of that hand and fill in the void.
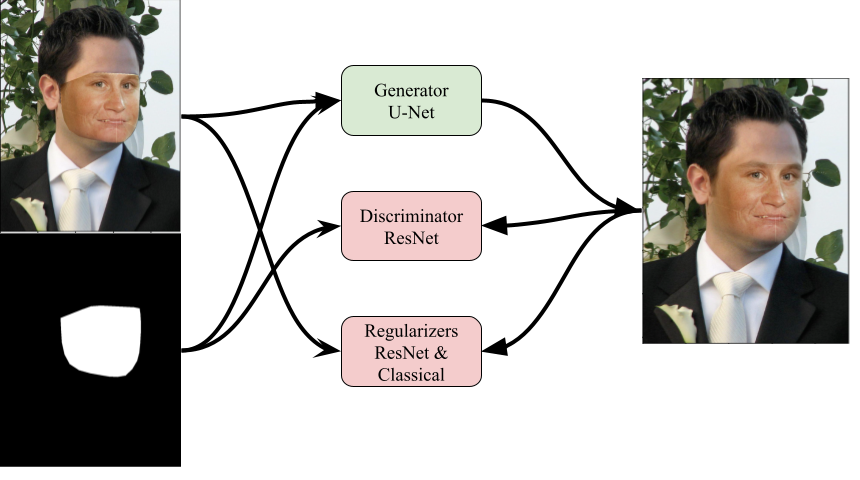
Our deep learning based approach is illustrated in above. We train a Generator based on the U-Net architecture and a Discriminator based on the ResNet architecture. We modify both to accept an additional 4th channel as input representing the mask of the face which should in theory make it easier for the generator to focus updates there and the discriminator to catch it when the generator doesn't. This 4th channel idea was inspired by \cite{tsai2017deep}. The standard adversarial loss is used to train the generator and the discriminator additionally gets to see real unaltered images. We additionally use a suite of regularization methods to ensure the output RGB image preserves as much of semantics as possible of the input image. First we included a basic pixel L2 loss. Initially I wanted to avoid this as it makes it challenging for the generator to make significant, but necessary for realism, changes to the input image. However, without this I found the generator had a hard time training and often would start doing bizarre things like adding another eye. The second regularization was first and second moment consistency loss of the three RGB channels. This alone ensures that we have to maintain something of the target face, in particular the skin tone. Lastly I used a latent space embedding loss. Using a pretrained Resnet18 model I enforced that the embedding of the output shouldn't differ significantly from that of the input.
Training
Training the actual GAN proved to be tricky as always. The discriminator definitely seemed to be having an easier time adapting to the generator than vice versa. To allow the generator enough time to train appropriately I would train only the generator until it's loss (adversarial + regularization) fell below a certain threshold. Then I would train only the discriminator until the adversarial loss falls below a certain threshold then go back to the generator. For both I used an Adam Optimizer, learning rate 3e-4 and batch size 20. I used Google Collab single GPU for all training. For data I used the ibug dataset that we used for project 5. Since that dataset has ground truth key points I went ahead and used those for purposes of preparing input images for the generator. I did this as opposed to predicting keypoints myself to avoid adding additional noise to the already tricky GAN training procedure. For this reason I don't expect the full pipeline to work for images where the key point detection is faulty as the generator is never exposed to these examples during training. I preprocessed 5000 random pairs of images into raw composites to provide a static dataset for the GAN to use. I did not provide the multi resolution blended version for the images since that process was too expensive to run for all 5000 images.
Evaluation

There's obviously no way to objectively evaluate model performance so we resort to qualitative evaluation. I randomly sampled 5 image pairs. For each I examined the raw composition (TOP). Then the classical blending solution (MIDDLE). Then the U-Net blending solution (BOTTOM). The results are shown in above. Given that face swapping is an entirely subjective task it's hard to draw a black and white judgement as to which is superior. In some ways which we discuss in the next section the classical blending procedure is more reliable, and in other ways the GAN approach provides upside.
Discussion
As a disclaimer much of the analysis below may be due to simply not training on enough data or enough iterations. I only had access to a single GPU during training. One thing the GAN seemed to consistently accomplish is making the original seam in the image disappear. In the classically blended results the gradient of skin tone while smoothed is still fairly apparent and renders the image obviously fake in most situations. The GAN accomplishes this generally by setting the skin tone for all visible skin to a constant value. Another thing the GAN is able to accomplish which the classical approach cannot is modifying the geometry of target face. For example in the bottom left example a number of features in the classical result have clear warp artifacts such as the side of the eye being pulled out. The GAN result leaves a fully realistic face in this case, but the question then becomes is it really maintaining the nature of the target face in the base image? Despite the regularization affects in some cases it seems to deviating pretty significantly from the target image. However the real issue is in synthesizing new facial features, in most images there is at least one mistake that stands out rendering the whole face somewhat alien. Ideally the discriminator loss eventually takes care of this, but from my observation typically training cycles would look as follows. Generator consistently makes a small set of mistakes. Discriminator learns to identify those and the generator then makes a new set of mistakes. But the discriminator, at least as I was training it, doesn't seem to remember the earlier mistakes and after a while the generator may make them again. Perhaps one solution would be to save some of the older generator images to avoid the discriminator over fitting to the latest version of the model. Or perhaps train the generator to perform well against an ensemble of the current discriminator and past versions of the model.
Conclusion & Future Work
To conclude, for reasons we pointed out earlier classical multi resolution blending remains insufficient if the goal of face swapping is to produce a single realistic image that retains some semantics of the target face and the context of the base image. I continue to believe GANs have the capacity to produce realistic face swaps and previous work seems to support this argument. I plan on looking more closely in what their architecture, data, and training process was which enabled them to have the success that they had in this regime. One of the concerns is how unstable these GANs seem to be during training. Future work probably is required to make the whole process more stable and less sensitive to minor parameter and setup modifications. Another open question is how to deal with the regularization terms. I don't believe that operations localized to pixels are sufficient since they hinder the larger geometrical changes that are necessary to make the swap more realistic. The fundamental challenge seems to be that you don't necessarily see all components of the target face that you need to overlay the base face with. Maybe it's easier if we're given multiple views of the target face so that we don't have to guess what's occluded and then maybe the job of deep learning can be purely to pick which components of which images to use for the ultimate overlay.