Object Snapshot: A Video Special Effect via Instance Segmentation
CS294-24 Final Project
Introduction
In recent years, with the increasing availability of mobile devices, more and more people have the the ability to make their own videos with the built-in cameras on their phones. The exploding popularity of video sharing platforms, such as TikTok and Instagram, creates the needs for everyone, not just professionals, to edit their videos and potentially add special effects. Since it is hard to create the effects in professional video editing software, there is an increasing need for simplified video editing tools for amateurs.
We present Object Snapshot, a tool that automates the creation of a particular kind of video special effect, which selects a few keyframes, creates a snapshot of an object at a keyframe, and applies effects to several frames before the keyframe. The users do not need to have any knowledge of video editing software and are able to input only a few parameters to make such effect, greatly simplifying the potentially tedious creation process.
Motivation
Here is a video that motivated me to do this project. It has millions of clicks, and I think it is pretty cool. I want to create some videos like that. This video shows the effect of object snapshot but is done via professional video editing software [1].
System Design
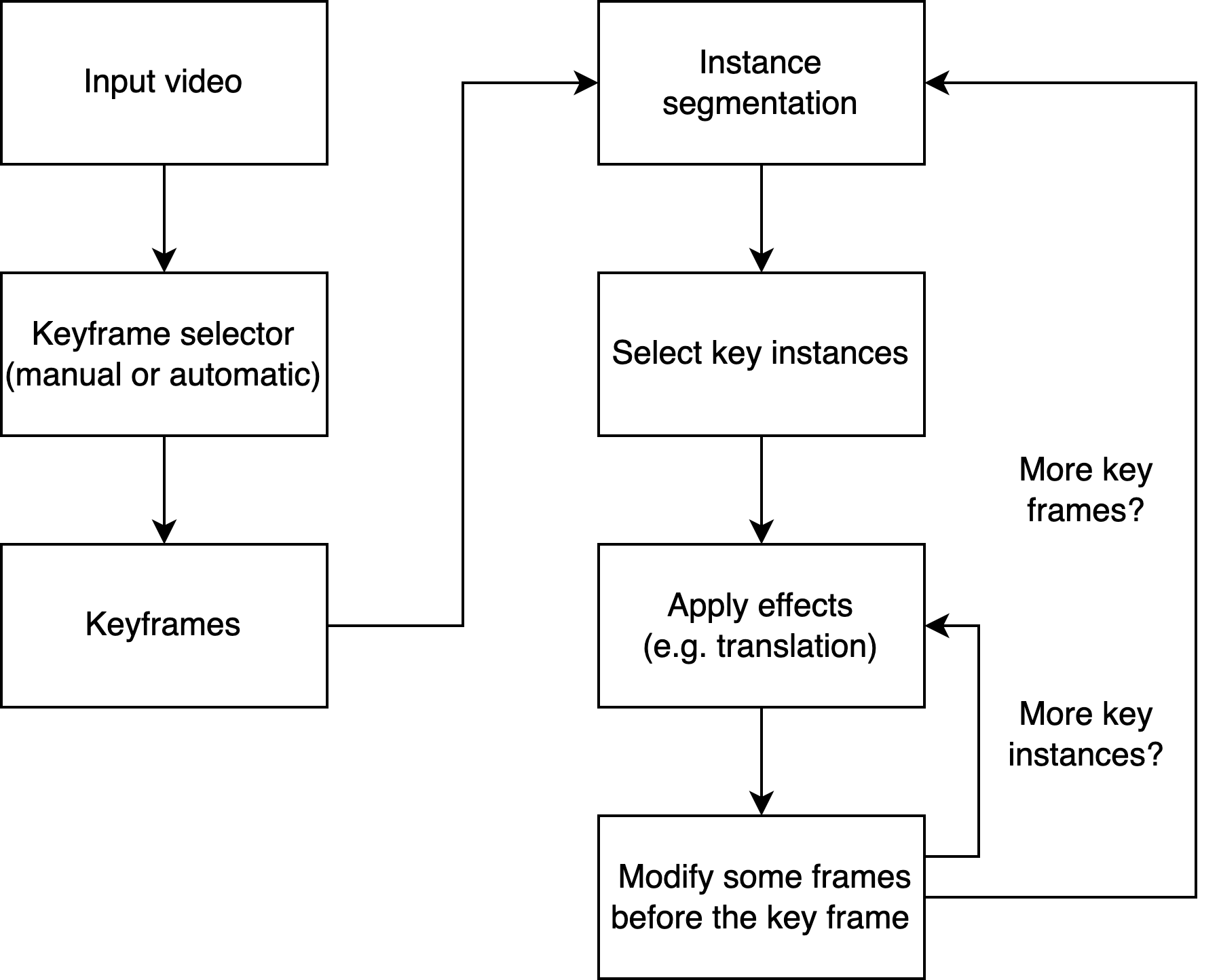
 |  |
|---|---|
 |  |
We designed a system that programmatically applies the snapshot effect to videos. The first image shows the processing pipeline of the system, and the second image shows an example of an image being processed.
Overview
As pipeline shows, the users need to input a video first. And they will input a bunch of parameters, such as the keyframes. Then for each keyframe, the system does instance segmentation, and then the user will choose the key instance to manipulate. The user will choose which effects to be applied, such as translation, as well as the corresponding parameters, such as the starting point and duration of the translation. Then the system will apply them to this instance. Finally, some frames before the keyframe will be modified accordingly. And the system repeats this process for each key instance and for each keyframe.
Alternatively, the system can automatically choose the keyframes, the key instances, the effects to be applied as well as their parameters.
There are three key components of the system: keyframe selection, instance segmentation, and applying effects.
Keyframe Selection
The keyframes are those frames in which instance segmentation and subsequent operations are performed. The first figure is an example. The system supports manual selection and random selection. For manual selection, users can choose any frame to be a keyframe, but they usually choose frames that can create a dramatic effect. For example, if the video is showing someone is jumping into the air, it may be a good idea to choose the frame in which the subject is at the highest point of the jump.
Instance Segmentation
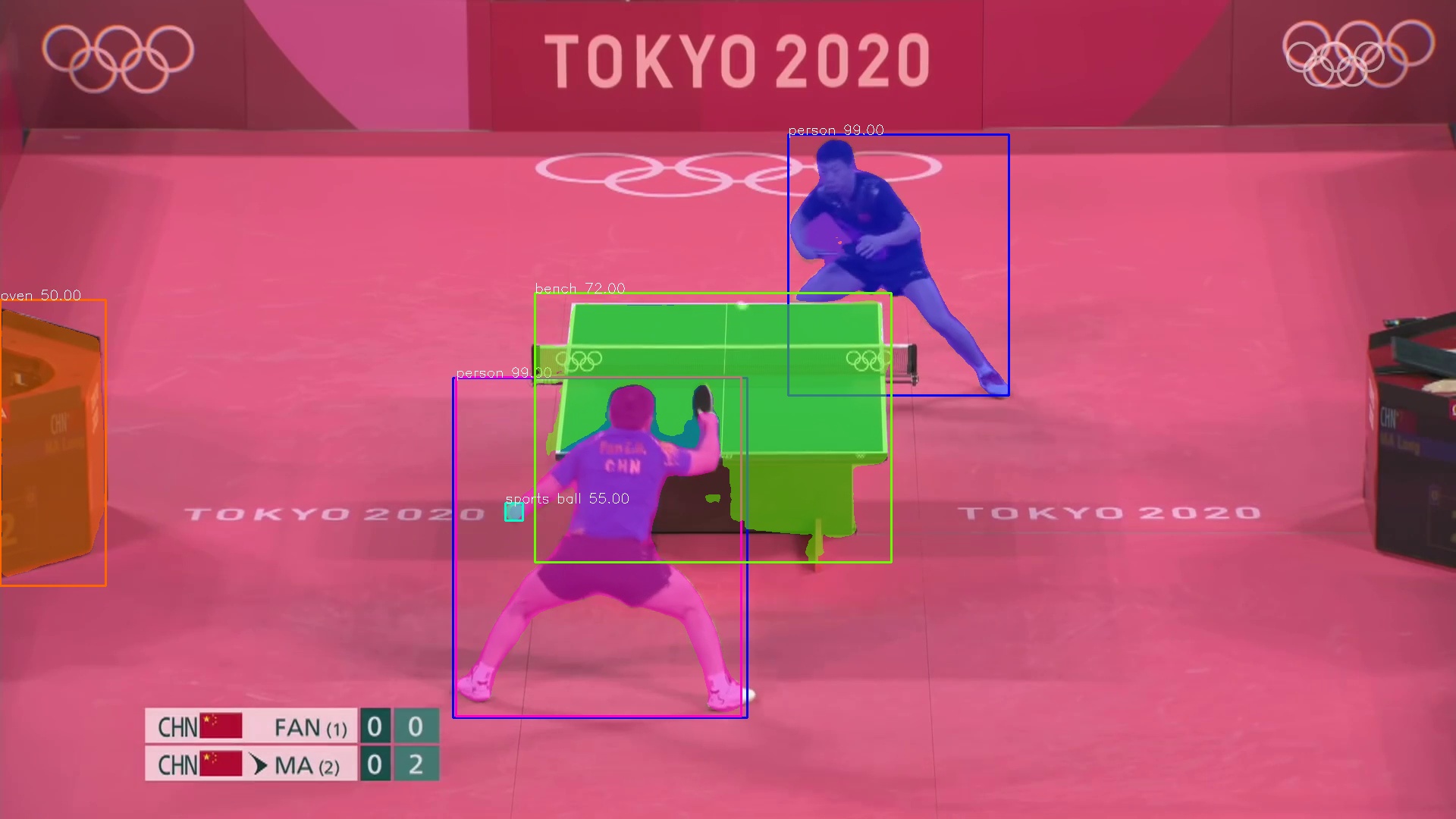
Instance segmentation is a classic type of task in computer vision. It aims to label each foreground pixel with object and instance, as shown in the second image. The state-of-the-art solution is to use the Mask R-CNN architecture with the PointRend module.
Mask R-CNN This neural network has two components. The first proposes regions in which an object may be found. The second finds bounding boxes and masks by doing classification on the pixels of the proposed regions [2]. Both components are connected to the backbone network. For this project, we use ResNet-50 as the backbone network [3].
PointRend It views instance segmentation as a rendering problem and uses various ideas (e.g. subdivision) from computer graphics to "render" label maps. It is a module that performs point-based segmentation predictions at adaptively selected locations based on an iterative subdivision algorithm [4].
PixelLib In the implementation of the system, we used PixelLib, a library that uses pre-trained Mask R-CNN + PointRend model to do image segmentation tasks and provides convenient APIs \cite{pixellib}. The system is able to get the bounding box and the mask of each instance, as shown in \cref{fig:frame_segmented}. Then it processes the information and gets a masked instance, as shown in the third image.
Applying Effects
The core idea of Object Snapshot is to find an object at frame
Here is a list of possible effects as well as use cases:
- Snapshot. A table tennis player moves around, and we take a snapshot whenever they change direction.
- Translation. A tennis ball bounces off the borders of the screen and goes to a racket.
- Rotation. A fork is rotating in the air, and a person manages to grab it.
- Scaling. A giant coffee cup gradually shrinks to normal size, and a person takes a sip of the coffee
- Warping. As an introduction to a video, a warped person gradually turns into a normal person.
- More...
Results
This shows some frames from a manually processed video. In this video, we applied two effects: snapshot and translation. It appears the athlete is trying to collect his duplicates. In the last two images, we applied a series of snapshots to create an afterimage effect [6].
This shows the result of processing the same video using random selection. The system has a few hyperparameters to determine the range of random numbers. It selects 50 keyframes randomly. For each instance in a keyframe, it randomly determines if effects should be applied. If so, it applies snapshot to a random number of frames before the keyframe. It turns out the result is very different from the manually processed video, but we think the resultant video is interesting as well [6].
This shows the result of processing a video captured by a non-static camera. It turns out the snapshot is applicable in this scenario. Note that taking snapshots of objects may not be ideal when the camera is moving really fast, such as in a video from a first-person view [7].
This shows a failed case of random selection. The camera moves too fast, and there are too many objects, resulting in messy video [8].
Discussion
Based on the results, we note a few common characteristics of applying object snapshots:
- The selection of keyframes is as much an art as science. It can be beneficial to choose keyframes that exhibit dramatic facial expression or change of motion. However, even most of the results from random selection do not follow this pattern, the final result is still satisfactory.
- While determining good keyframes is quite hard, it is relatively easy to outline some characteristics of bad keyframes. For example, it is preferable to have a single static camera or at least a slowly moving camera. Switching to another camera or a fast moving camera can make scenes messy.
Limitations and Future Work
Since we only had a limited amount of time to work on this project, there are many aspects that can be improved.
Keyframe selection The current system only supports manual selection and random selection. We hope the system can be smarter when selecting keyframes. One possibility is to use optical flow to detect the speed of change for the instances. The system will take a snapshot whenever they change direction.
Instance segmentation We currently use Mask R-CNN with PointRend for doing instance segmentation. Since we treat each frame independently, temporal continuity was not taken into consideration. We hope we can either use a different neural network or perform additional operations to track each instance.
Effects We only implemented snapshot and translation in this project. Although we are satisfied with the results, there are many more effects that can make videos more interesting, such as rotation, scaling, warping, etc. In addition to the shape, we can also change other properties of the object, such as the color, transparency, etc.
We also hope to add more options to random selection so that the result can have more interesting effects.
Conclusion
In this paper, we present a simplified video editing tool called Object Snapshot and show some sample results from manual inputs and automatic inputs. It performs well in applying this particular kind of special effect while requires much less work from the users than a traditional video editing software.
References
[1] 医生:放心这就是镇定剂 https://www.bilibili.com/video/BV1sg41157sA
[2] Mask R-CNN https://arxiv.org/pdf/1703.06870.pdf
[3] Deep Residual Learning for Image Recognition https://arxiv.org/abs/1512.03385
[4] PointRend: Image Segmentation as Rendering https://arxiv.org/pdf/1912.08193.pdf
[5] Simplifying Object Segmentation with PixelLib Library https://vixra.org/abs/2101.0122
[6] Ma Long 🇨🇳 vs Fan Zhendong 🇨🇳 | Men's Singles Table Tennis 🏓 Gold Medal Match | Tokyo Replays https://youtu.be/VTCDQYYKA9o
[7] Spider-Man Movie (2002) - Peter's New Powers Scene (2/10) | Movieclips https://youtu.be/zlwaUJzGqns
[8] Volleyball first person | Wing Spiker - Highlights | VC Fakel (POV) https://www.youtube.com/watch?v=prXYKIX9UTM