
|
|
Our method consists of two steps. Image alignment and Color Restoration. In an image alignemet phase, we try to align the three channels together. This is non trival since many images have a large offset between channels. We consider image alignment as finding solution of the following optimization problem $$\mathrm{argmin}_{x,y} \; \mathcal{L}(P_{+x,+y},Q)$$ where \(P,Q\) are images of dimension \( h \times w \), and \( P_{+x,+y} \) is the image \(P\) shifted by vector \( (x,y )\). We consider two losses, the SSD loss and NCC loss defined by $$SSD(P,Q)= ||P - Q || ^2 $$ $$NCC(P,Q)= - \frac{Cov(P,Q)}{\sqrt{Var(P) Var(Q)}} $$ A naive solution is to iterate through a the spcae \( [-15,+15]^2\), however this approcah failed to cater to the cases where the image has a larger offset in number of pixels due to high resolution. To address this issue, we implement a image pyramid search where we down scale the image by a factor of two until we reach a resolution no greater than 128. We then performs exhaustive search on each level. When images at a particular level becomes larger than \(512 \times 512 \), we perform a center crop for loss calculation to spped up the computation.
In our implementation, we use blue channel as the base image and try to align red and blue channel with it. We found that while NCC loss tends to have better results, it is marginally slower in runtime.
 Brightness R Brightness R |
 Brightness B Brightness B |
 Response Map R Response Map R |
 Response Map B Response Map B |
1.96% of the edges are in the actual image.
2.97% of the information (variance) are in the actual image.
For each image, we calculate these two metrics alongside one direction and perfom corresbounding crops from the two sides. An visualization is shown below. We perform auto-cropping on both axis.
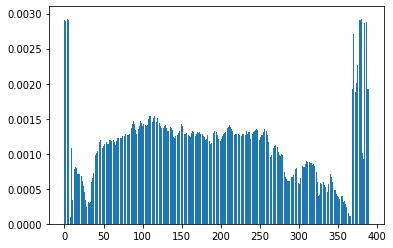 Distribution of Edges alongside X-Axis Distribution of Edges alongside X-Axis |
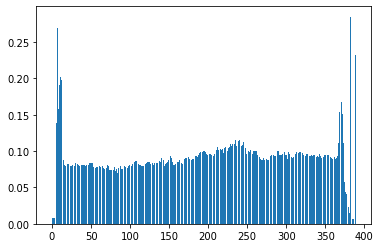 Distribution of Variance alongside X-Axis Distribution of Variance alongside X-Axis |
 |
 |
 |
| Baseline | + Filter | + AutoCrop |
We report the results of our algorithm as folloows
| Baseline | AutoCrop + Filter |
|---|---|
| melons.jpg | |
 R[-179, -13] G[-83, -10] R[-179, -13] G[-83, -10] |  R[-180, -13] G[-83, -10] R[-180, -13] G[-83, -10] |
| three_generations.jpg | |
 R[-105, -14] G[-49, -15] R[-105, -14] G[-49, -15] |  R[-108, -13] G[-50, -17] R[-108, -13] G[-50, -17] |
| train.jpg | |
 R[-86, -32] G[-42, -6] R[-86, -32] G[-42, -6] |  R[-86, -32] G[-42, -6] R[-86, -32] G[-42, -6] |
| cathedral.jpg | |
 R[-12, -3] G[-5, -2] R[-12, -3] G[-5, -2] |  R[-12, -3] G[-5, -2] R[-12, -3] G[-5, -2] |
| church.jpg | |
 R[-58, 4] G[-24, -4] R[-58, 4] G[-24, -4] |  R[-58, 4] G[-24, -4] R[-58, 4] G[-24, -4] |
| onion_church.jpg | |
 R[-108, -37] G[-50, -26] R[-108, -37] G[-50, -26] |  R[-108, -37] G[-49, -26] R[-108, -37] G[-49, -26] |
| harvesters.jpg | |
 R[-124, -15] G[-59, -18] R[-124, -15] G[-59, -18] |  R[-123, -15] G[-59, -18] R[-123, -15] G[-59, -18] |
| sculpture.jpg | |
 R[-140, 27] G[-33, 11] R[-140, 27] G[-33, 11] |  R[-140, 27] G[-33, 11] R[-140, 27] G[-33, 11] |
| lady.jpg | |
 R[-112, -9] G[-52, -7] R[-112, -9] G[-52, -7] |  R[-114, -11] G[-53, -7] R[-114, -11] G[-53, -7] |
| icon.jpg | |
| self_portrait.jpg | |
 R[-175, -37] G[-77, -29] R[-175, -37] G[-77, -29] |  R[-175, -37] G[-77, -29] R[-175, -37] G[-77, -29] |
| tobolsk.jpg | |
 R[-6, -3] G[-3, -3] R[-6, -3] G[-3, -3] |  R[-6, -3] G[-3, -3] R[-6, -3] G[-3, -3] |
| emir.jpg | |
 R[-86, 316] G[-48, -24] R[-86, 316] G[-48, -24] | R[-107, -41] G[-49, -23] |
| monastery.jpg | |
 R[-3, -2] G[3, -2] R[-3, -2] G[3, -2] |  R[-3, -2] G[3, -2] R[-3, -2] G[3, -2] |
Additional Examples :
| lugano.jpg | Piony.jpg | v_italli.jpg |
 R[-91, 28] G[-39, 15] R[-91, 28] G[-39, 15] |
 R[-105, 5] G[-51, -4] R[-105, 5] G[-51, -4] |
 R[-76, -36] G[-37, -21] R[-76, -36] G[-37, -21] |
Acknowledgements |