Part 1
Part 1 of this project involves morphing your face to someone else's. For this, I chose my first computer science professor at Berkeley, John Denero. These are the two pictures I started with. My linkedin head shot and a random picture of professor Denero I found on line (don't tell him).


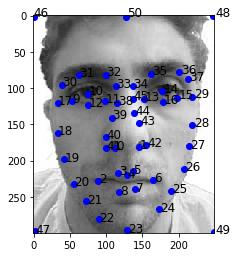
The first step of this process is defining correspondences, or points that are analogous in the two pictures. For example, my eye to his eye and my nose to his nose ect. I wrote a script that allowed me to do this manually. Very simply, I just went back and forth clicked points that were similar. Example below:
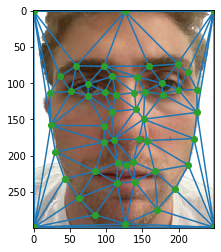
Once the points are defined, we use the Delaunay algorithm to generate a series of triangles that mask the face. We average the location of all the points and run the algorithm. The algorithm, by the way, just connects series of 3 points while trying to maximize the angle of the most narrow angle. In effect, trying to make all the triangles as close to equilateral as possible.
The idea of the merge is to silmotanously change the shape and the color of the images. The shape is changed by finding corrosponding triangles between the original image and the average we just calculated, then using an affine transformation to subtly change from the original shape to the new shape. An affine is defined below:
In geometry, an affine transformation, or an affinity (from the Latin, affinis, "connected with") is an automorphism of an affine space. More specifically, it is a function mapping an affine space onto itself that preserves the dimension of any affine subspaces (meaning that it sends points to points, lines to lines, planes to planes, and so on) and also preserves the ratio of the lengths of parallel line segments. Consequently, sets of parallel affine subspaces remain parallel after an affine transformation. An affine transformation does not necessarily preserve angles between lines or distances between points, though it does preserve ratios of distances between points lying on a straight line.
Once we transform all of this we can make this midway picture.

Now, all that's left to do is modify all the steps above by an alpha coefficient which controls what percent of transition the image is through. We generate a bunch of images and string them together in a gif.









