In this project, I implemented two CNNs. One was a image classification network using FashionMNIST, and the other was a semantic segmentation network using a facade dataset.
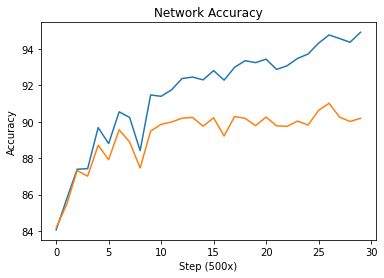
I used a pretty basic four layer CNN architecture for this part; this included two convolutional layers and two fully connected layers. I used cross entropy loss and an Adam optimizer. I found the optimal learning rate (0.002882) and weight decay (0) through random search.
| Class | Validation Accuracy | Testing Accuracy |
|---|---|---|
| T-Shirt/Top | 0.917 | 0.842 |
| Trouser | 0.994 | 0.976 |
| Pullover | 0.926 | 0.857 |
| Dress | 0.966 | 0.922 |
| Coat | 0.898 | 0.841 |
| Sandal | 0.989 | 0.968 |
| Shirt | 0.842 | 0.679 |
| Sneaker | 0.964 | 0.950 |
| Bag | 0.988 | 0.973 |
| Ankle Boot | 0.989 | 0.972 |
Shirt seemed to be the hardest to classify followed by T-Shirt/Top and Coat. I attribute this to because all the classes are tops so aesthetically they look similar.
Below are some images my network classified correctly and incorrectly.
| Class | Correctly Labelled Image 1 | Correctly Labelled Image 2 | Incorrectly Labelled Image 1 | Incorrectly Labelled Image 1 |
|---|---|---|---|---|
| T-Shirt/Top |

|

|

|

|
| Trouser |

|

|

|

|
| Pullover |

|

|

|

|
| Dress |

|

|

|

|
| Coat |

|

|

|

|
| Sandal |

|
|

|

|
| Shirt |

|

|

|

|
| Sneaker |

|

|

|

|
| Bag |

|

|

|

|
| Ankle Boot |

|

|

|

|
Here are the learned filters from the first convolutional layer.
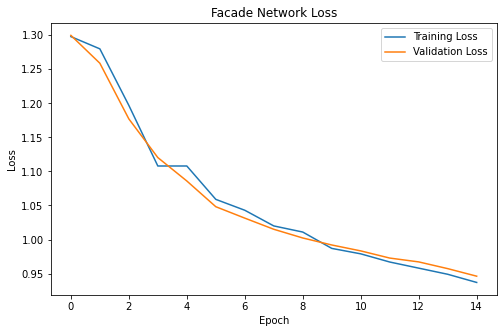
For my network, I grouped four convolutional layers with a final transposed convolution layer to upsample back to the original dimension.
Input -> (Conv ReLU Pool) x 4 -> ConvTranspose2d -> Conv -> Output
I used 64, 128, 128, and 64 filters for the convolutional layers, respectively, and used default hyperparameters (lr=1e-3, wd=1e-5) for the Adam optimizer and cross entropy loss.
I achieved an average precision of 0.5096 on the test set (0.5920, 0.7070, 0.1026, 0.6641, 0.4823).
Here is my result from a photo I took.
It seems to be very conservative with its non-facade labelling. It got ~70% of the windows. In hindsight, this photo was a poor choice because there isn't anything else other than the facade wall and windows. I was hoping my network would (incorrectly) label the awning under the top windows as balconies but it didn't.

