Below is a plot of the training and validation accuracy per epoch.
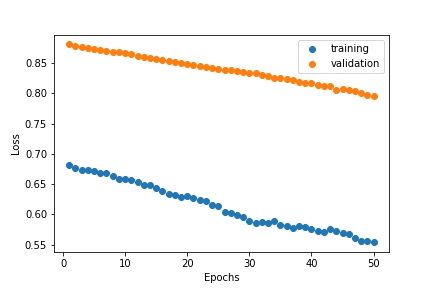
Training and Validation Loss
Below is the average precision of my network calculated on the testing set:
Average AP: 0.51897080071
| Class |
Average Precision |
| others |
0.6416514332595568 |
| facade |
0.7211610511400426 |
| pillar |
0.0618453133363771 |
| window |
0.818657223990157 |
| balcony |
0.35153898182387 |
Here are some examples of my network's output from the testing set:

Input Image

Ground Truth

Network Output

Input Image
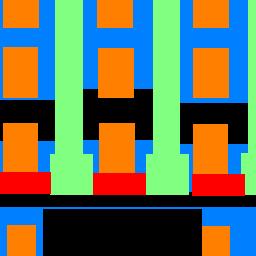
Ground Truth

Network Output

Input Image

Ground Truth

Network Output

Input Image

Network Output
The network generally performs well when its identifying the facade and windows. It does not do as well with pillars and balconies.
This may be for a variety of reasons; for one, every training image had facade & windows while only a smaller subset had balconies, and and even smaller subset had pillars.
Additionally, windows have straighter edges & are much easier to visually identify. Therefore, it is expected that the network perform well in segmenting windows. However,
balconies and pillars are harder to identify because their shapes are not standardized.
The last image & network output pair is a picture I took of the Royal Palace in Madrid, Spain that I cropped to (256, 256, 3) to run through the network.
The network does not do well in identifying the pillars on the palace, and instead classifies it as part of the facade. It recognizes some of the balcony on the middle and top floors, but not very clearly.
The network could perhaps not be performing as well because of the large amount of sky present in the picture, which was not present in many of the training images.
 Fashion MNIST Training Set Sample Images
Fashion MNIST Training Set Sample Images
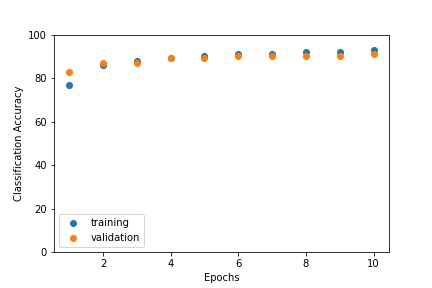 Training and Validation Accuracy
Training and Validation Accuracy










































 Original Image
Original Image
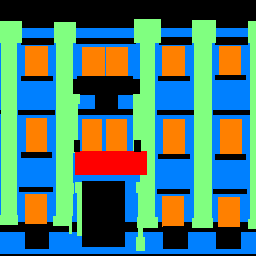 Segmentation
Segmentation