Project 4: Classification and Segmentation¶
Overview¶
In this project I was tasked with creating 2 Deep Nets. In part 1, I created and trained a convolutional neural network to classify various articles of clothing from the FashionMNIST dataset. In part 2, I created and trained a convolutional neural network for the semantic segmentation of the mini-Facade dataset.
Part 1: Image Classification¶
Part 1 can be compartmentalized into 2 components
- Dataloading
- CNN Architecture, Training, and Performance
- Network Filter Visualization
FashionMNIST Dataset¶
As stated in the overview, I used the FashionMNIST dataset. Here are the label and descriptions of the dataset.
| Label | Description |
|---|---|
| 0 | T-shirt/Top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle Boot |
There are a total of 10 classes with each image in the dataset being of dimension 28 x 28. Here is a nice view of some of the images in the dataset. Every three rows of the picture below represents one class.

Here is a sample of four images and their respective labels
CNN Architecture and Performance¶
My CNN architecture was as follows
- Conv layer: 32 channels with 2x2 kernel
- ReLU
- MaxPool: 2x2 window
- Conv layer: 32 channels with 5x5 kernel
- ReLU
- MaxPool: 2x2 window
- Fully-Connected Layer: 120 dimension output
- Fully-Connected Layer: 10 dimension output
For my loss function I used Cross Entropy. I used Adam with a learning rate of 0.01 and 0 weight-decay momentum. For training, validation, and testing I used a batchsize of 4. I trained for a total of 5 epochs. As stated in the spec, I at first attempted to use Adam as my optimizer but I obtained much worse results in comparison to the results that I received when using SGD.
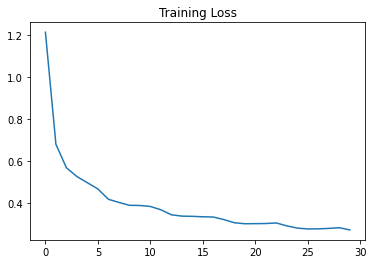
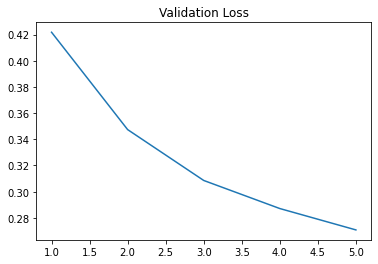
Here are the training and validation loss curves of my network
 |  |
Here is the final per-class accuracy of my net
- Accuracy of 0 : 87 %
- Accuracy of 1 : 97 %
- Accuracy of 2 : 86 %
- Accuracy of 3 : 91 %
- Accuracy of 4 : 78 %
- Accuracy of 5 : 98 %
- Accuracy of 6 : 74 %
- Accuracy of 7 : 97 %
- Accuracy of 8 : 97 %
- Accuracy of 9 : 95 %
The overall accuracy of my classifier was 90.44% on the test set. The hardest pictures for my net to classify are t-shirts, pullovers, coats, shirts. To be completely honest, even I had some difficulty in differentiating between these articles of clothing!
For each class, here are two photos that my classifier labeled correctly and two photos that my classifier labeled incorrectly

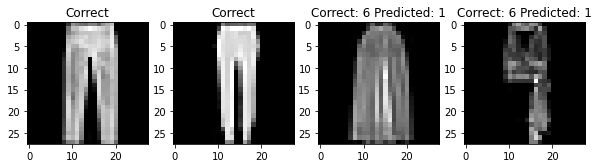

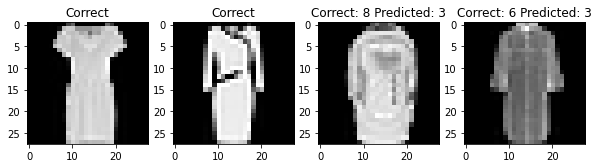
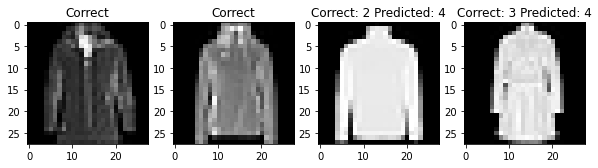
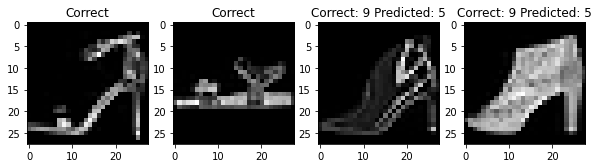
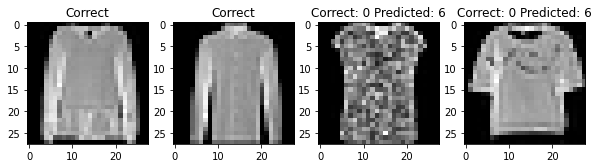
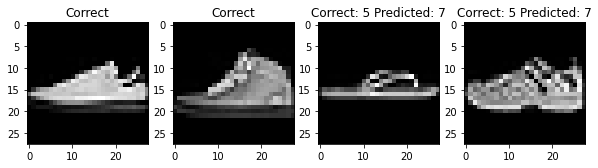

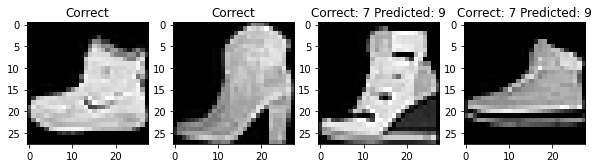
Filter Visualization¶
Here are what the filters look like from the first convolutional layer
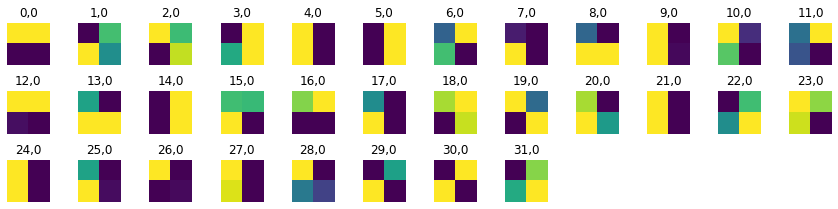
Here are what the filters look like from the second convolutional layer

Part 2: Image Segmentation¶
Task¶
Create and train an CNN to segment a building into 5 different classes
| Class | Color | Pixel Value |
|---|---|---|
| Facade | Blue | 1 |
| Pillar | Green | 2 |
| Window | Orange | 3 |
| Balcony | Red | 4 |
Here is an example of an image and its segmented form
 |  |
CNN Architecture¶
For this part of the project, I designed my CNN using the U-net architecture proposed here: https://arxiv.org/abs/1505.04597
The U-Net is composed of 2 components. In the contraction portion of the net, we reduce the dimensions of the image. In the expansion phase of the net, we increase the dimensions of the image.
- Contraction
- Conv Layer: 32 channel out, 3x3 kernel, padding=1
- ReLU
- Batch Norm
- Conv Later: 64 channel out, 3x3 kernel, padding=2
- ReLU
- Batch Norm
- MaxPool: 2x2 window
- Conv Layer: 128 channel out, 3x3 kernel
- ReLU
- Batch Norm
- Expansion
- Conv Transpose: 64 channel out, 2x2 kernel, stride=2, padding=1
- Conv Layer: 32 channel out, 3x3 kernel, padding=2
- ReLU
- Batch Norm
- Conv Layer: 5 channel out, 3x3 kernel, padding=2,
- ReLU
- Batch Norm
My CNN doubles the number of channels between each convolutional layer to increase the number of features that my net can perceive. In this, I go from $\text{Image Start: }3 \rightarrow 32 \rightarrow 64 \rightarrow 128 \rightarrow 32 \rightarrow \text{Num Classes: } 5$. I use the ReLU as my nonlinearity. I use batch normalization after each conv-relu pass in order to reduce overfitting (it increases the independence between netowrk layers) and expedite the training process. I add padding as needed to ensure that image dimensions align as the image is passed through the net.
CNN Performance¶
Here are the training and validation loss curves
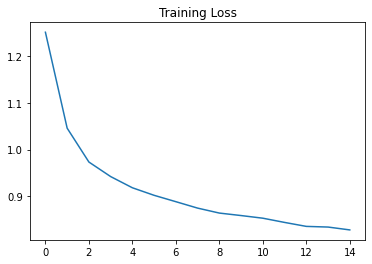 | 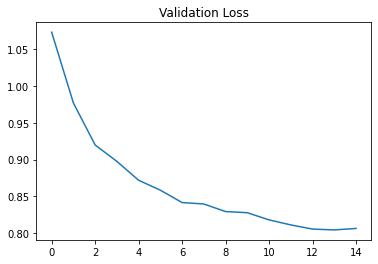 |
Here are the AP scores of my CNN
- AP = 0.5956991094463625
- AP = 0.7540532301608894
- AP = 0.1280414026312353
- AP = 0.7732066608260174
- AP = 0.3552330444870263
- Average AP: 0.5212466895103062
Sample CNN Produced Segmentations¶
| |  |
 | 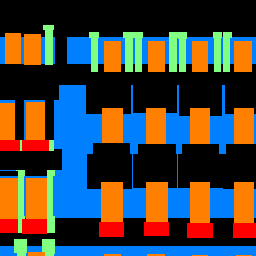 | 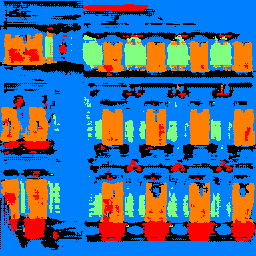 |