
What better time to explore my fashion sense than April Fools Day. Even better, let's have machine learning do it for us.
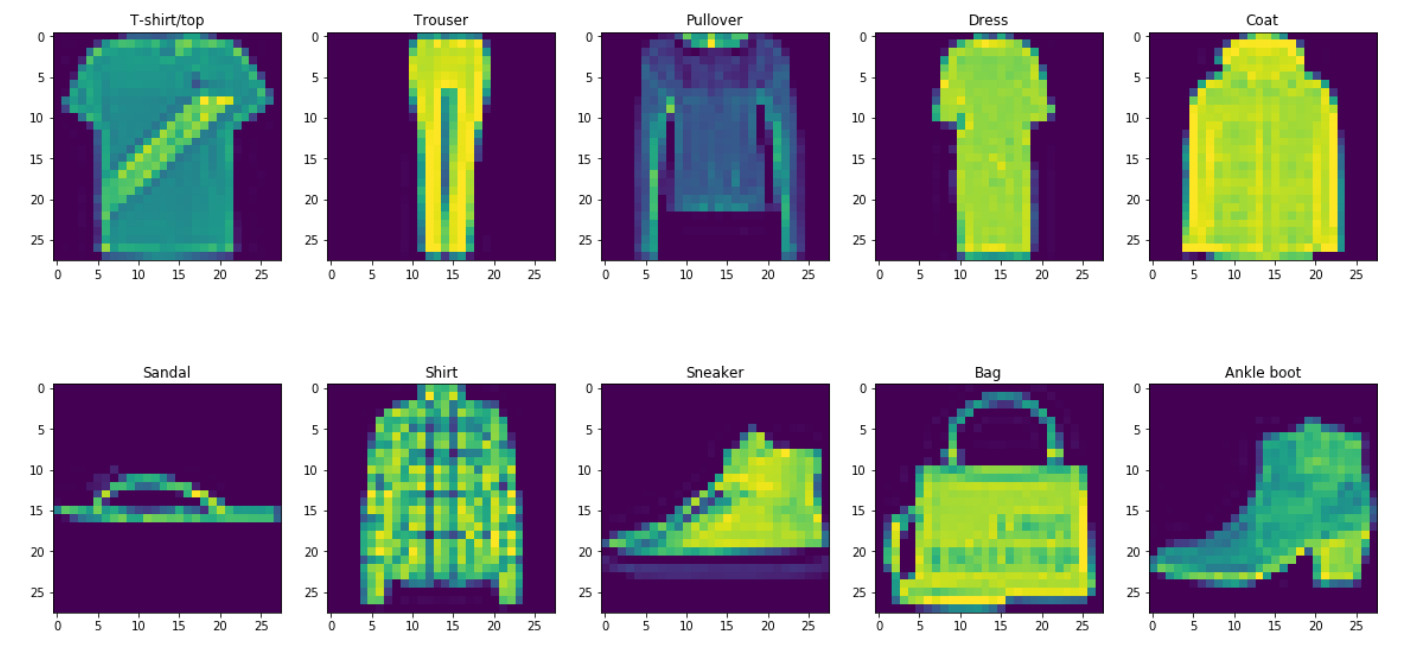
Classes in the Fashion MNIST dataset
Okay so now, let's train a simple model with two 32-channel convolutional layers with some activations and max pooling.
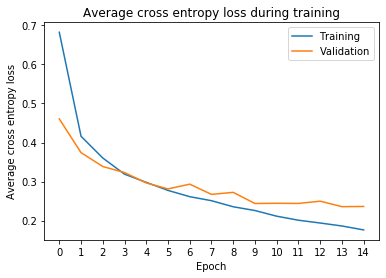
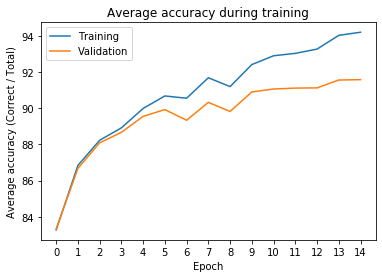
Alright, looks like it managed to learn pretty well from the test dataset while doing reasonably on the validation, which should mean the model does not overfit.
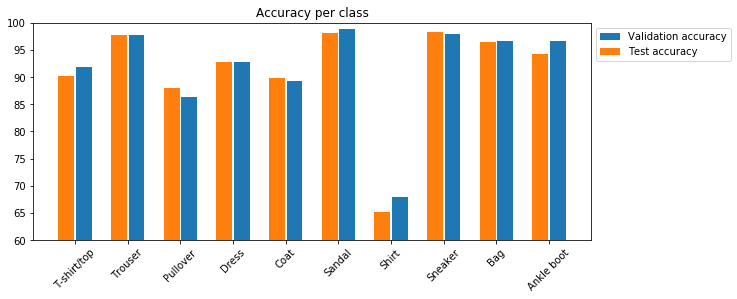
In the end, we got about 91.07% and 91.58% accuracy for the test and validation dataset respectively. Looks like it did pretty good. The worst category is shirts. It's likely due to the fact the the next three worst categories are pullovers, coats, and T-shirts/tops respectively. This is likely due to the fact that all these categories tend to resemble each other. Let's see some examples of correct and incorrect classifications for each class...
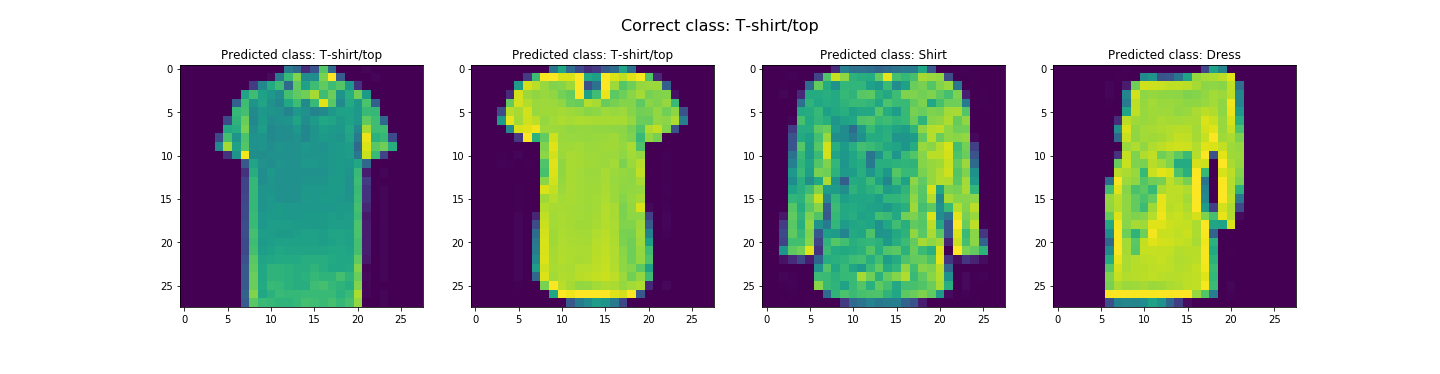
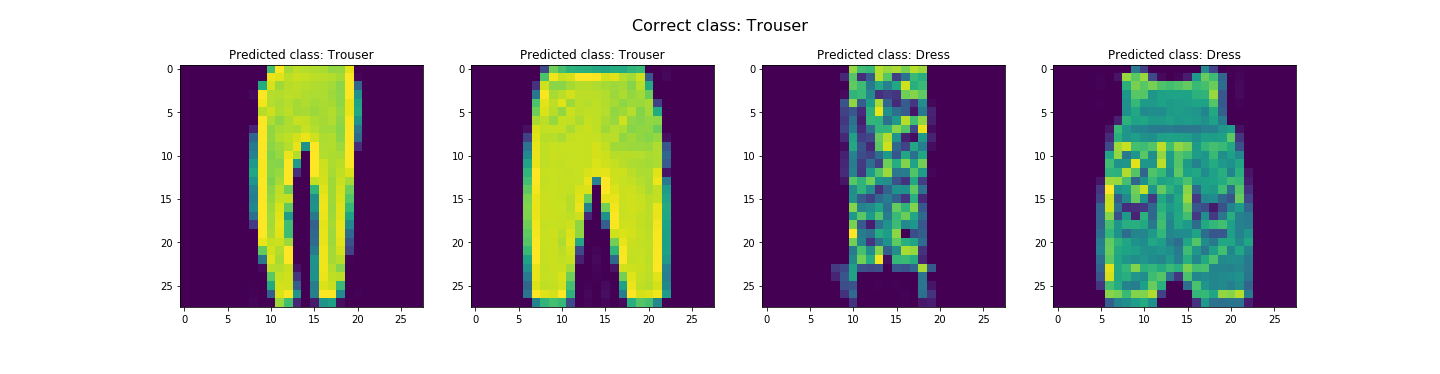
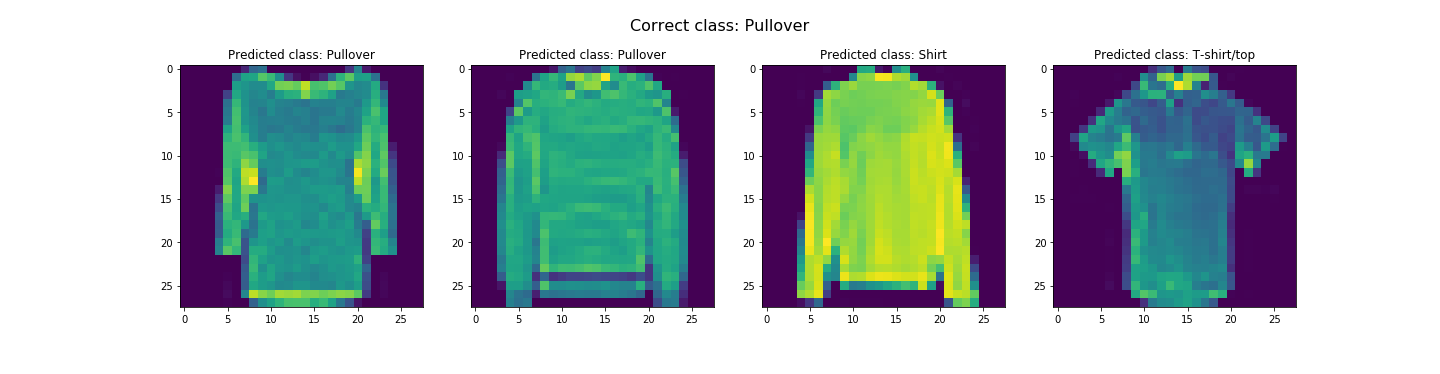
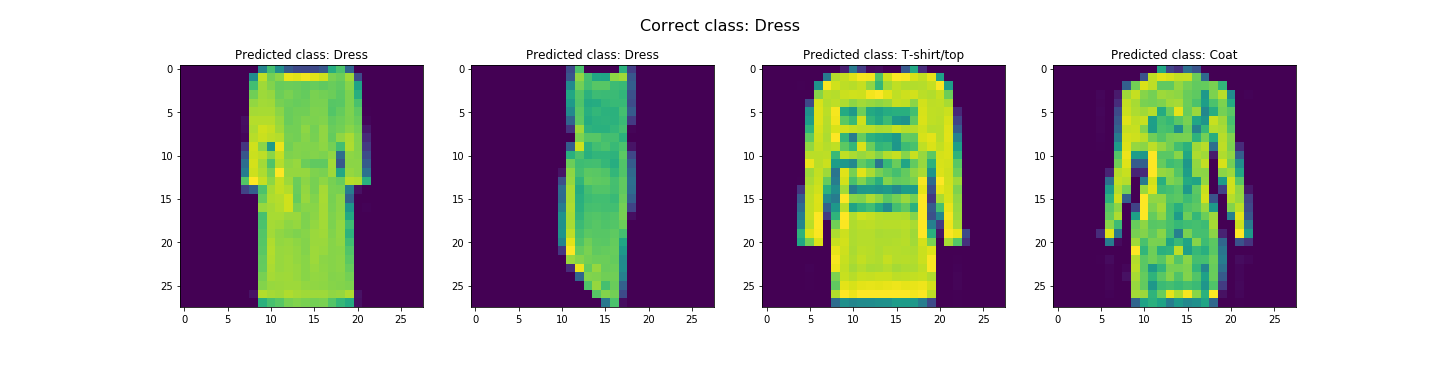
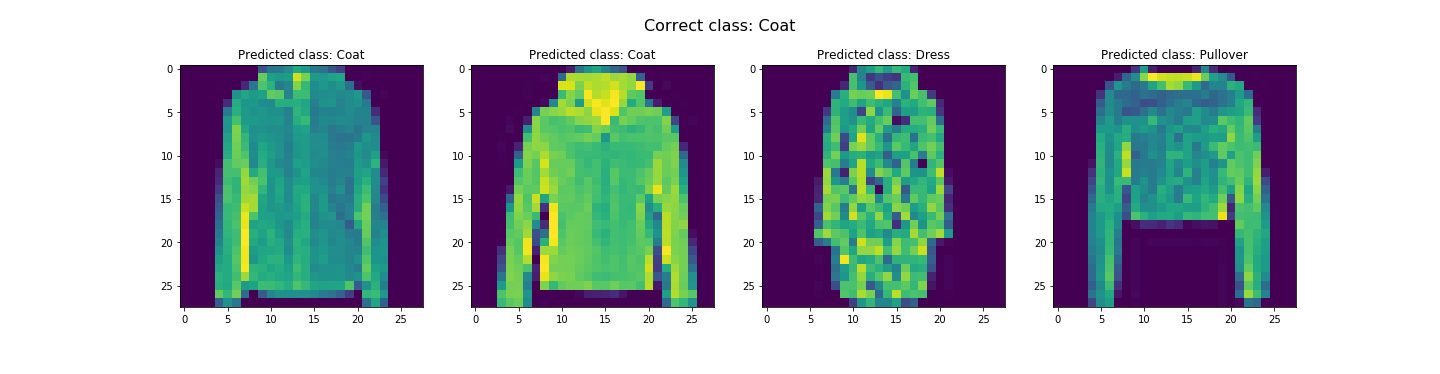
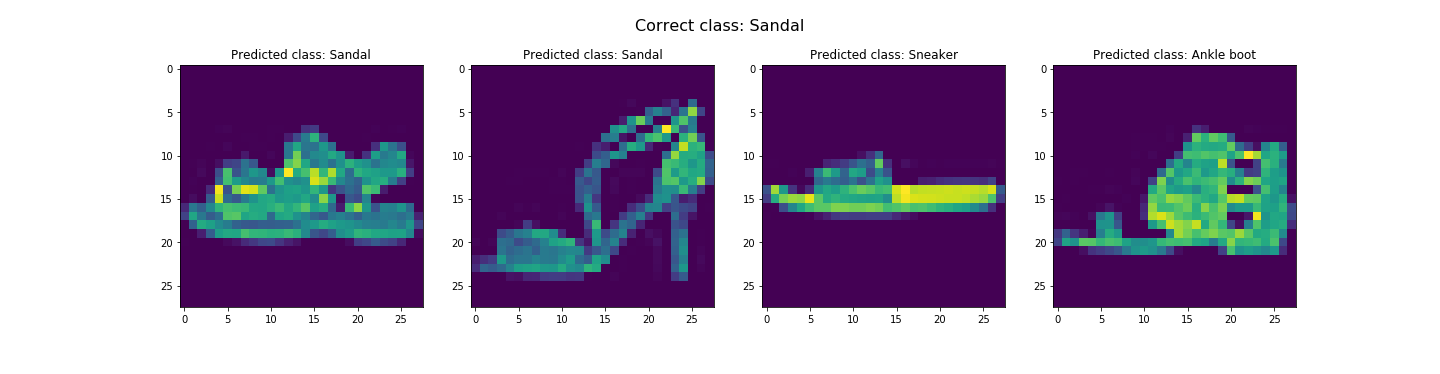
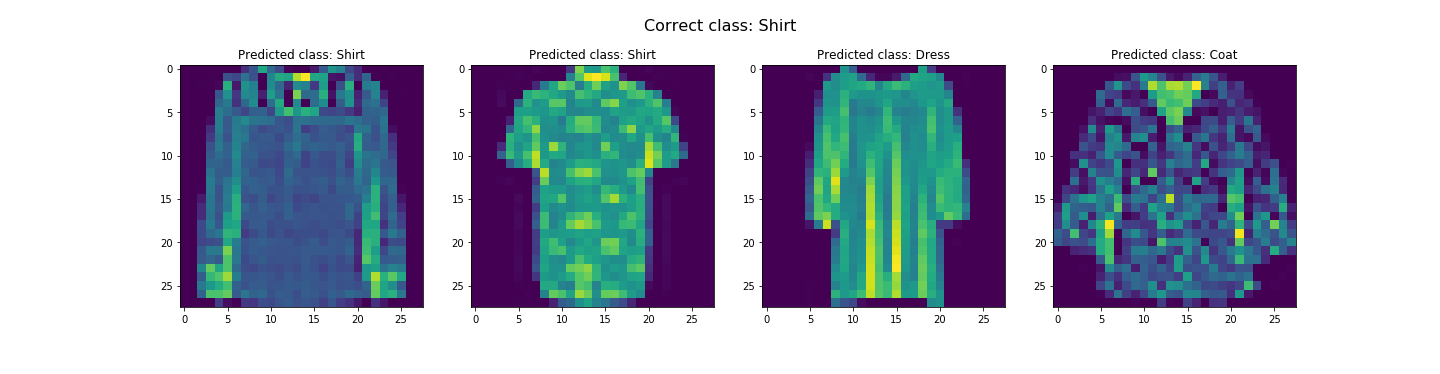
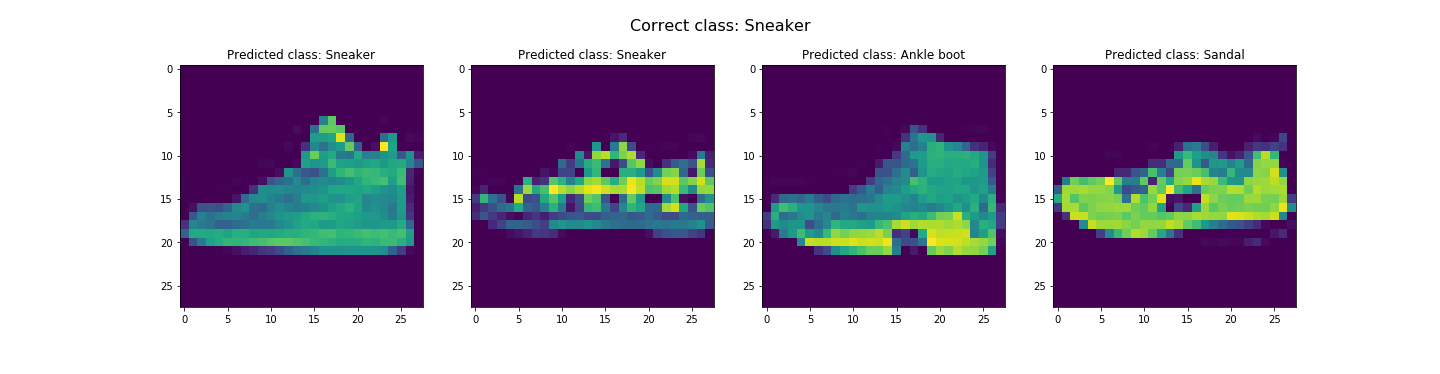
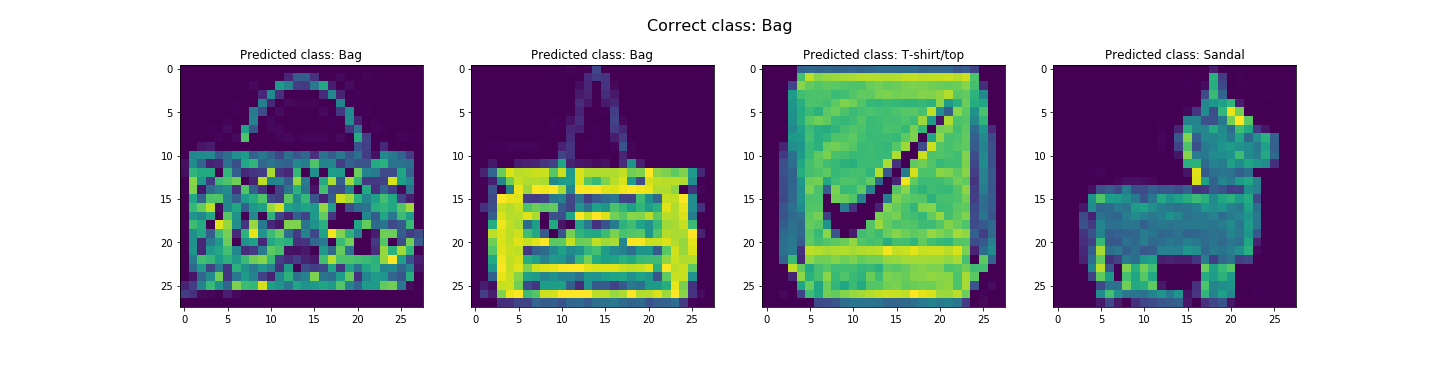
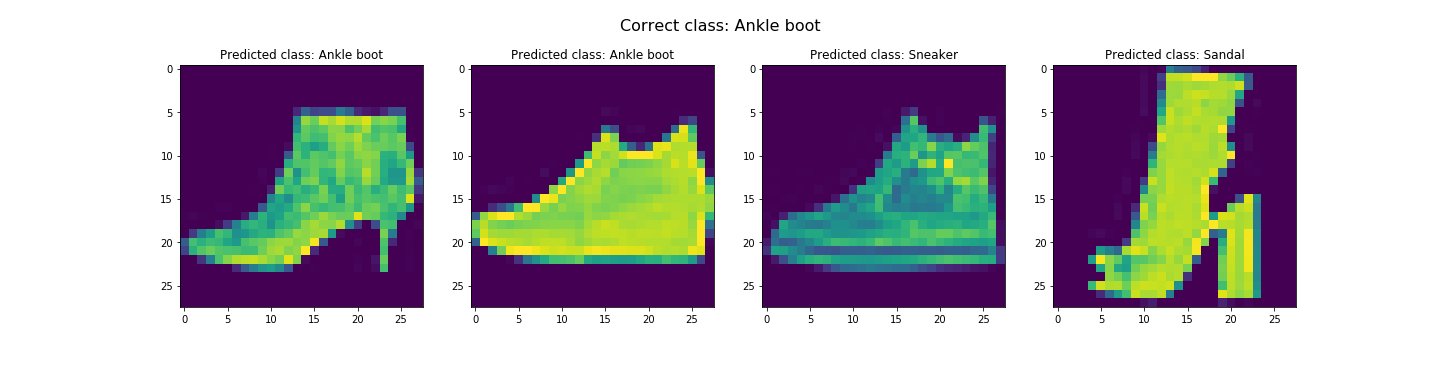
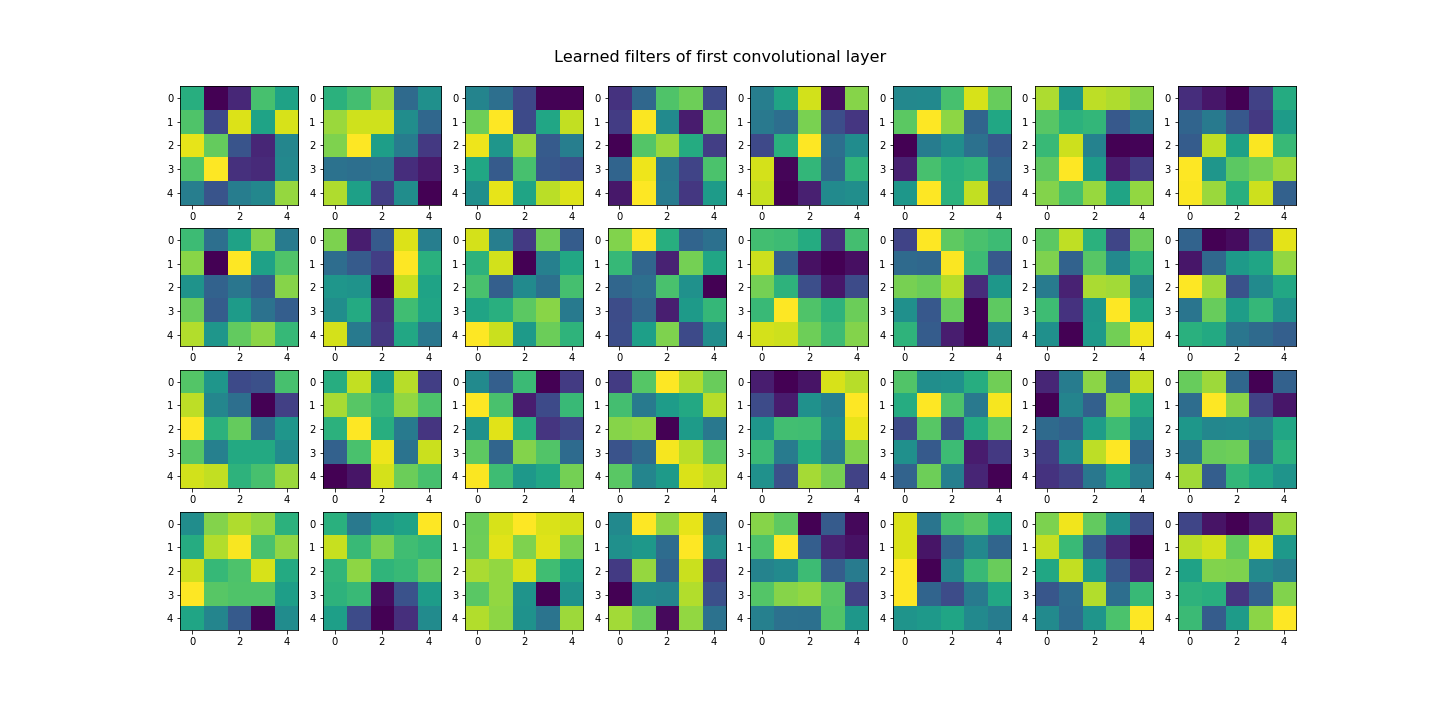
Seems like our hypothesis was true. Let's check the learned filters.
Well identifying pieces of clothing is cool and all, but wouldn't it be cooler if we could segment and label parts of a building facade?

Input

Target (ground truth)
Regardless of your opinion on buildings, we're gonna do it anyway. Let's throw this model on for size:
(0): Conv2d(3, 64, kernel_size=(7, 7))
(1): ReLU()
(2): BatchNorm2d()
(3): Conv2d(64, 128, kernel_size=(5, 5))
(4): MaxPool2d(kernel_size=2)
(5): ReLU()
(6): BatchNorm2d()
(7): Conv2d(128, 256, kernel_size=(5, 5))
(8): ReLU()
(9): BatchNorm2d()
(10): Conv2d(256, 128, kernel_size=(3, 3))
(11): MaxPool2d(kernel_size=2)
(12): ReLU()
(13): Upsample(scale_factor=2)
(14): BatchNorm2d()
(15): Conv2d(128, 64, kernel_size=(3, 3))
(16): ReLU()
(17): Upsample(scale_factor=2)
(18): BatchNorm2d()
(19): Conv2d(64, 5, kernel_size=(3, 3))
(20): ReLU()
AP (other) = 0.7117503462860113
AP (facade)= 0.7295915454210072
AP (pillar)= 0.20612026916508605
AP (window)= 0.8320750207266184
AP (balcony)= 0.5506869504980673
AP (AVERAGE)= 0.606044826419358

Input

Output

Input

Output