Background
CNNs are a type of artificial neural network that are specialized for computer vision tasks. Their defining feature is the usage of convolutions in-between layers, which is a traditional signal-processing method used to express how a signal changes w.r.t the filter. In CNNs these filters are learnable and, as a result, have been shown to help NN methods produce much better results on vision tasks. This is because conv. filters not only take advantage of repeated structure in images, help make classifiers invariant to object location within an image, but also greatly reduce the number of parameters of a neural network (which in turn reduces necessary compute and allows for longer training). As deep learning and other data-driven methods have surged in popularity in the past decade, the availability of huge amounts of data and compute has pushed CNN architectures to posses often super-human performance on tasks such as image classification within datasets. There definitely is still much room for improvement (particularly in more difficult vision tasks and in terms of generalizability), but the past few decades of advancement have shown great promise for the future.
Image Classification
In this task, a model must assign each input image x in the dataset to one of predefined class labels y. Typical CNN architectures for this task are usually composed of many convolutional layers in the beginning followed by a few fully connected layers at the end. The intuition is that the CNN will use the sequential system of convolutional layers to learn hierarchy of visual features, and the fully connected layers will use information from the highest-level features to solve the actual classification task.
FashionMNIST
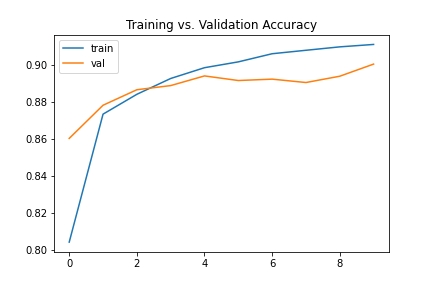
This dataset is inspired by the original MNIST digit dataset used to train LeNet, but theoretically presents a more difficult classification task for CNNs due to the more complex and somewhat overlapping nature of the object classes. For this project, we train a CNN using the architecture as shown below, where each convolution operation is accompanied by a ReLU activation and max pooling. A ReLU activation is also applied in-between the first and second FC layer, but not after the second. To train, we optimize standard cross-entropy loss using Adam with a learning rate of 0.01. The plot below details the training and validation accuracy of the model throughout training.
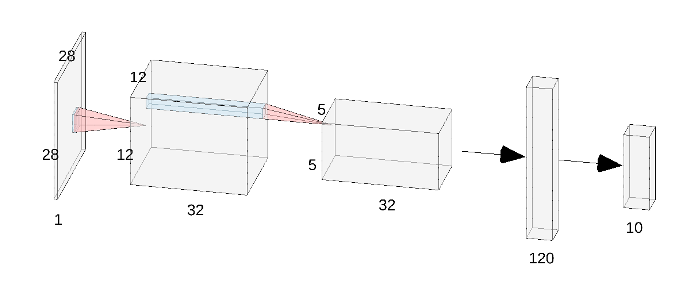
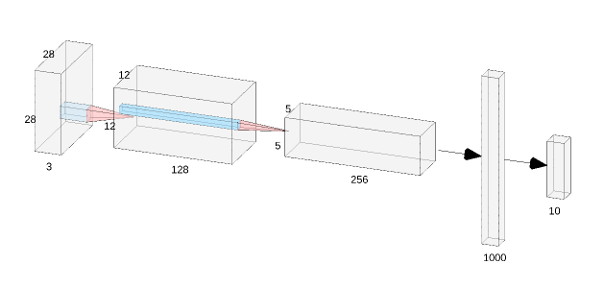
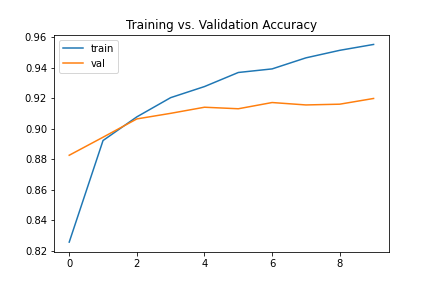
For better results, I used a modified architecture with a greater number of channels and changed all activations to Leaky ReLU (as shown below). This pushed the classifier accuracy up to roughly 91%.
Using this improved model, we can take a more detailed look into its behavior. Below is the per-class accuracy on both the validation and the test set, as well all the learned filters in the first convolutional layer (whiter = higher activation).
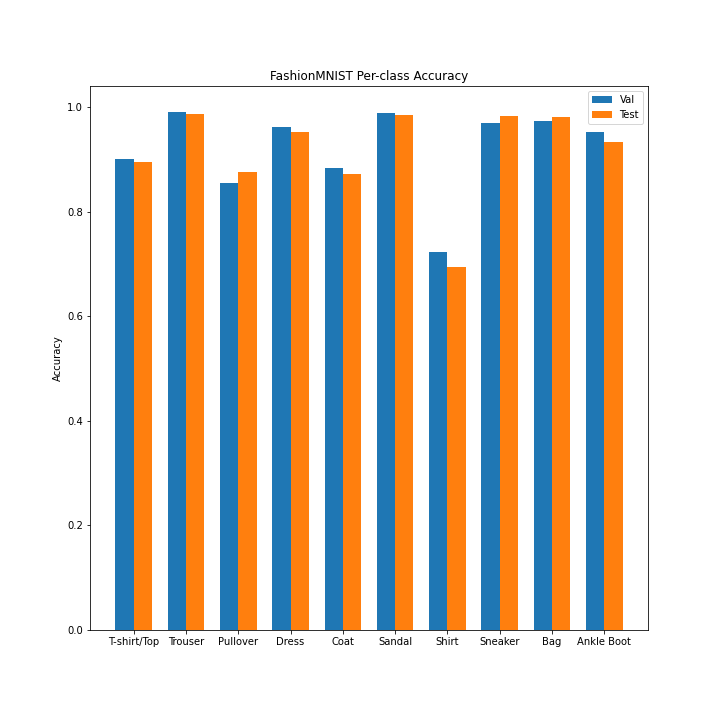

It seems that shirts are the hardest to classify by far, which makes sense due to the varying nature of that type of clothing. We can take a look at some random examples of correct/incorrect classifications from the test set to look even deeper into what is happening.
| Class | Correct | Incorrect (False Positive) |
|---|---|---|
| Top |


|


|
| Trouser |

|


|
| Pullover |


|


|
| Dress |


|


|
| Coat |


|


|
| Sandal |


|


|
| Shirt |
|


|
| Sneaker |


|


|
| Bag |


|


|
| Ankle Boot |


|


|
Semantic Segmentation
As opposed to assigning the whole image to a class, in this task the model much assign each pixel in the image to one of predefined object classes y. This is usually a much more difficult task for models in general, as object boundaries in images are often hard to detect for various reasons such as lighting or overlap. In contrast to the design of image classifiers, CNNs designed for this task are often fully convolutional, meaning they are composed of convolutional layers end to end. Because images are often downsampled within models, fully convolutional CNN architectures must make use of upsampling or transpose convolutions to match the original image dimension by the end.
Mini Facade
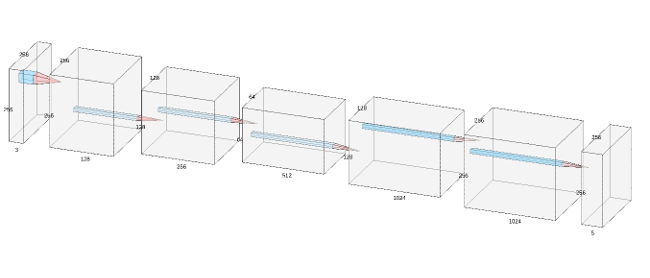
This dataset contains images of various buildings and architectures from around the world, and the goal is to classify each pixel as part of a balcony, window, pillar, facade, or other. The architecture I used is detailed below, where each convolution operation is followed by a ReLU activation and batch norm (except the final two convolutions). For upsampling, I used learned transpose convolutions. Note that I did not use any max pooling, but instead simply used strided convolutions for downsampling.
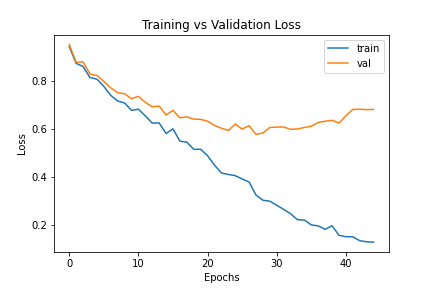
To optimize, we similarly use Adam to optimize a cross-entropy loss between the ground truth labeled image and predicted pixel labels. Via random grid search and manual heuristic tuning, I found the optimal hyperparameters for my model to be a learning rate of 1e-4 and weight decay of 1e-5. The loss curves of the final model are shown above, and the final model was able to achieve a mAP of ~0.56.
As a final fun test, I tested the model on a few pictures I took on my phone, one of Quebec's town hall and one of a hotel in Macau. After rescaling the images to 256x256, we get the following results.

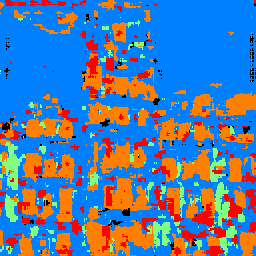


As we can see, the one thing the model can do reasonably well is classify windows. It is also decent at detecting facades, but it is clear that it has some trouble generalizing as it is classifying the sky in Quebec as facade. However, this lack of robustness to distributional shift may be expected since the images in the training set are up close and don't include the sky at all. The model also clearly struggles with false positives when detecting pillars and balconies for these two test images, as there are scattered spots of green and red despite the ground truth images lacking such structure. Its poor performance in detecting pillars is expected based off the models test set results; its AP for pillars was the lowest at around 0.15.