Overview
In this project, I used the Fashion MNIST dataset to train a model capable of classifying certain images of clothing, shoes, bags, etc. I also implemented semantic segmentation, using the Mini Facade dataset to train a CNN with several convolutional layers.
Part 1: Image Classification
I implemented my model based on the specs. The main customizations I made were performing a 80% and 20% split on the training data into training and validation, using 20 epochs, and changing 32 channels to 64 channels as that resulted in an noticeable improvement. The rest of the architecture and hyperparameters basically followed the specs: "Our CNNs will use a convolutional layer (torch.nn.Conv2d), max pooling layer (torch.nn.MaxPool2d) and Rectilinear Unit as non-linearity (torch.nn.ReLU). The architecture of your neural network should be 2 conv layers, 64 channels each, where each conv layer will be followed by a ReLU followed by a maxpool (I used 2x2 maxpool). This should be followed by 2 fully connected networks. Apply ReLU after the first fc layer (but not after the last fully connected layer). You will use cross entropy loss (torch.nn.CrossEntropyLoss) as the prediction loss. Train your neural network using Adam using a learning rate of 0.01 (torch.optim.Adam)."
Plot the train and validation accuracy during the training process.
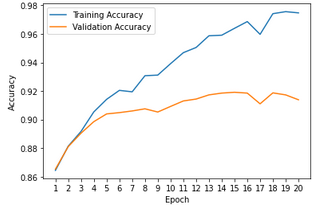
|
Compute a per class accuracy of your classifier on the validation and test dataset.

|
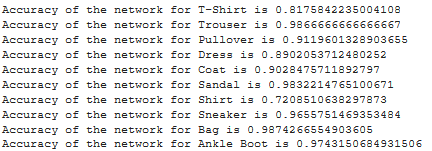
|
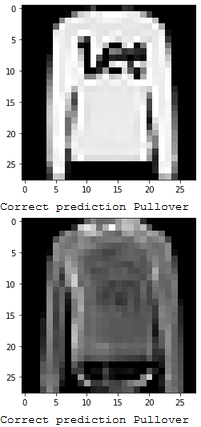
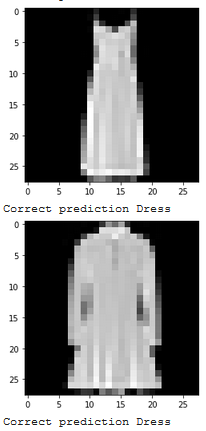
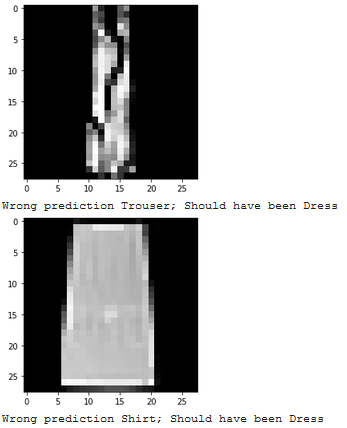
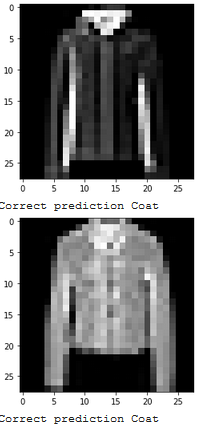
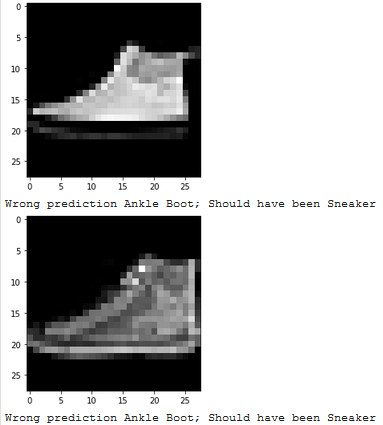
Which classes are the hardest to get?
The hardest classes to get were Shirt and Tshirt, and understandbly so since they often look reasonably similar in this dataset.
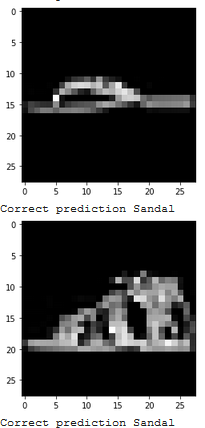
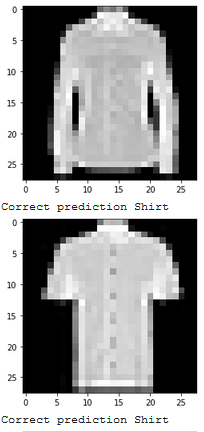
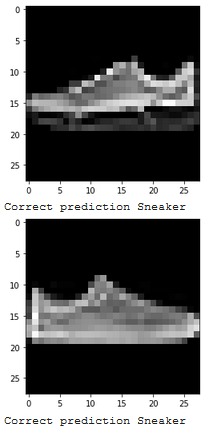
Show 2 images from each class which the network classifies correctly, and 2 more images where it classifies incorrectly.
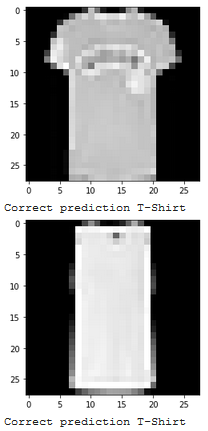
|

|
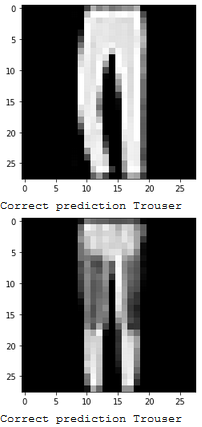
|

|
|

|
|
|
|

|
|

|
|

|
|
|
|

|
|

|
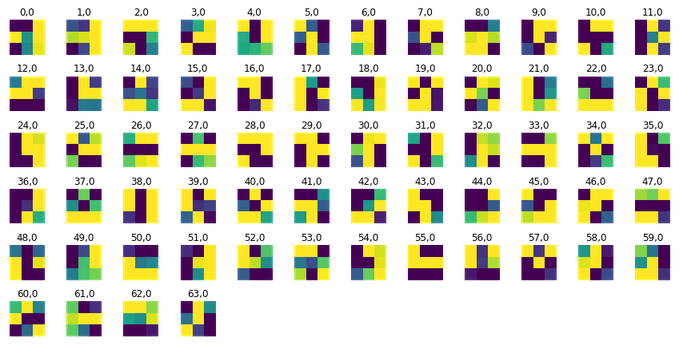
Below I visualize the learned filters from the first layer (on Piazza, Ashish said just the first layer is fine). I used the following tutorial https://towardsdatascience.com/visualizing-convolution-neural-networks-using-pytorch-3dfa8443e74e, which was shared on Piazza :
|
Part 2: Semantic Segmentation
In this part, I performed semantic segmentation of images in mini Facade using a CNN with 6 layers. Architecture details are described below.
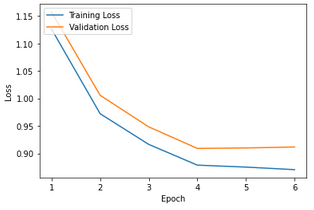
Report the detailed architecture of your model. Include information on hyperparameters chosen for training and a plot showing both training and validation loss across iterations.
My architecture of my model was the following:
3x3conv (64 channels) Batchnorm, ReLu, Maxpool (step size of 2), 3x3conv (128 channels) BatchNorm, ReLU, MaxPool (step size of 2), 3x3conv (512 channels), BatchNorm, ReLU, MaxPool, 3x3conv (256 channels), BatchNorm, ReLU, MaxPool, Conv3x3(5000), BatchNorm, ReLU, Conv3x3(10), BatchNorm, ReLU, ConvTranspose2d.
Include information on hyperparameters chosen for training:
Epoch: 6; Split training set to 80% training and 20% validation; Cross Entropy Loss Function; Adam; Learning Rate = 1e-3, weight decay = 1e-5; bath size = 1
Plot showing both training and validation loss across iterations.
|
Report the average precision on the test set:
The average precision on the test set was 0.5524018
Here is the per class AP:
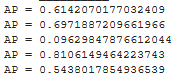
|
Try running the trained model on the photo of a building from your collection. Which parts of the images does it get right? Which ones does it fail on?
I ran the trained model on my photo below, and my model generated the image to its right. As you can see, my model did a decent job, getting most of the windows right. It incorrectly found balconies, when there were none in my actual image, and there was some Other classifications that seemed to be mainly noise. Overall, it did pretty good job at classifying the blue facade.

|

|