Labels: shirt, sandal, dress, trouser, sneaker, sandal, shirt, pullover
I loaded the Fashion MNIST dataset from torchvision.datasets.FashionMNIST to train the convoluntial neural network. The dataset contains images of clothing and 10 labels: top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, and ankle boot. I split the dataset into 50,0000 training, 10,000 validation, and 10,000 test images. Here is the first batch of images with their labels.
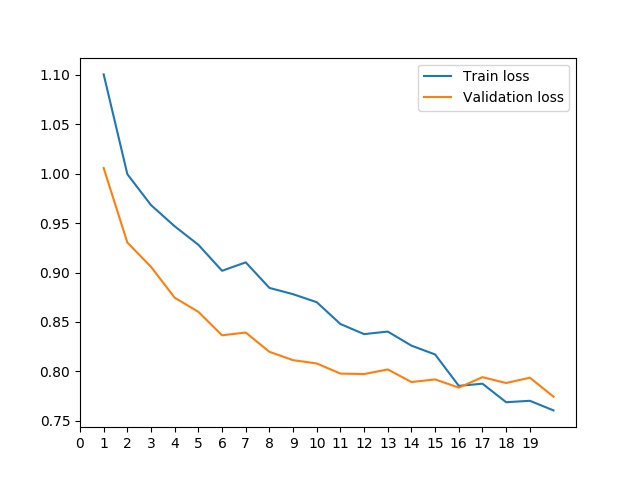
Next, I wrote a CNN with the following layers
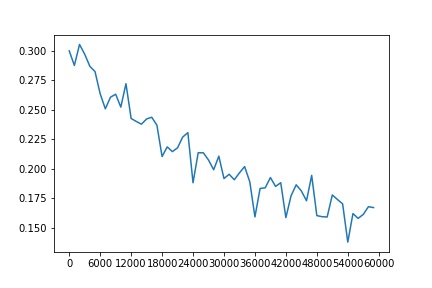
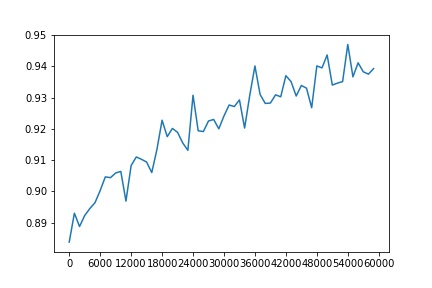
Accuracy of the network on the 10000 validation images: 0.9016
Accuracy of the network on the 10000 test images: 0.8996
Here are the per class accuracies on the validation and test set. The
hardest classes were shirt and pullover.
For each class, the left 2 photos are 2 examples where the class was predicted correctly and the right 2 photos are 2 examples where the class was predicted incorrectly with its incorrect prediction.
Here are the 32 learned 5x5 filters from the first convolution layer.
In this part of the project, we tried to label each pixel of an image to a correct class using the Facade Datateset which contains 5 classes: balcony, pillar, window, facade, and other. The dataset contains 905 training images and 113 test images. I split the training dataset to use 800 images for training and 105 images for validation.
The CNN I wrote had the following layers:
| Class | AP on test set |
|---|---|
| other | 0.5706324898350593 |
| facade | 0.6424847422315797 |
| pillar | 0.09759549263535051 |
| window | 0.7544610725258761 |
| balcony | 0.37914373106545085 |
The mean AP score on the test set was 0.48886350565 or ~48.9%
Here's the model output on a test image. The model is good at picking out
windows correctly and shutters as other. It fails on noticing whether the
roof is a facade or not. The blue at the top of the image means that the
model thinks that the roof at the top is actually a facade when it should
be classified as other (shaded in black).