Description of Model and Choices:
Network Model:
NeuralNetwork(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=800, out_features=120, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
(sig): Sigmoid()
)
Batch Size:
I tried to use the maximal batch size that I could, so I initially used 2000, and still had plenty of memory leftover. Even though higher batch sizes should be better/more accurate, I had mixed results, so I dropped it to 500 in the end.
Train vs. Validation Set:
I used an 80-20 split for my training and validation sets.
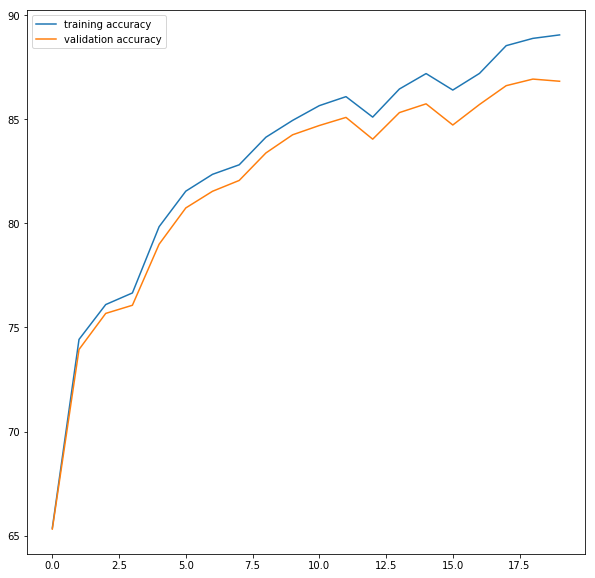
Training and Validation Accuracy:
Per Class Accuracy:
T-shirt/Top Accuracy = 84.9%
Trouser Accuracy= 97.4%
Pullover Accuracy= 79.5%
Dress Accuracy= 84.1%
Coat Accuracy= 72.5%
Sandal Accuracy= 96.0%
Shirt Accuracy = 64.6%
Sneaker Accuracy= 92.9%
Bag Accuracy= 95.6%
Ankle Boot Accuracy= 94.3%
Example Correct Images:

Example Incorrect Images:

Learned Filters Visualization:
Conv1 Filters:
Conv2 Filters:
Description of Model and Choices:
Model:
self.layers = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d((2,2)),
nn.ConvTranspose2d(64, 64, 2, stride=2, padding=0),
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d((2,2)),
nn.ConvTranspose2d(128, 128, 2, stride=2, padding=0),
nn.Conv2d(128, self.n_class, 5, padding=2),
)
After much playing around with a good structure, I ended with this model. I started by not using any MaxPooling, but I added them in to reduce the memory usage, and to isolate specific features in the image. I struggled a bit with maintaining the 264x264 resolution, so I ended up adding in the ConvTranspose2d filters, which essentially reversed the memory optimizations, but it made analyzing the image more consistent.
Dataset/DataLoader Parameters:
| Set | Flag | Data Range | Batch Size |
| TrainSet | train | 0, 799 | 25 |
| ValidSet | train | 800,899 | 1 |
| TestSet | test_dev | 0,109 | 1 |
| APSet | test_dev | 0,109 | 1 |
For the TrainSet I maximized Batch Size with respect to my memory constraints (8GB CUDA), and for the evaluation sets I had it at 1 to increase speed/allow for TrainSet to use more memory.
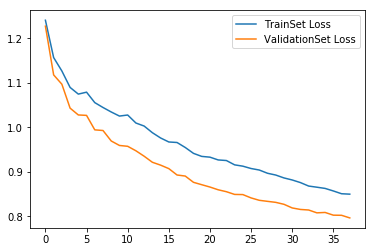
Training and Validation Loss over Epochs:
Average Precision on Test Set:
AP = 0.6074688650851506
AP = 0.7680592554423632
AP = 0.12238735057424996
AP = 0.7804787587538269
AP = 0.41658679299075146
Total AP = 0.5389962045692684
Takeaways:
I wrote a really long spiel here, but I managed to delete my entire webpage, so TLDR; I really liked this project and it opened my eyes to the fascinating world of NN/CNNs. I didn't have time to do it for this project, but I want to explore how to optimize computing with my RTX GPU using apex.amp to make use of FP16 computing speed on the new tensor cores in RTX cards. I also want to explore parallelization to be able to use both my RTX eGPU, and my RTX dGPU in my laptop, to even further increase items/sec.