Image Classification
We will use the FasionMNIST dataset available in torchvision.datasets.FashionMNIST for training our model. Fashion MNIST has 10 classes and 60000 train + validation images (50000 were used for training and 10000 for validation) and 10000 test images. Each example is a 28x28 grayscale image, associated with a label from 10 classes: T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, and Ankle boot.
![]()
Network Architecture
For our CNN, we used the recommended two convolution layers (3x3) with 32 channels and two fully connected networks, which worked quite well, netting an accuracy around 88%. To boost the accuracy to above 90%, we added padding to the convolutional layers.
We used cross entropy loss with Adam at a learning rate of 0.001 and trained it on batch sizes of 64 for 10 epochs.
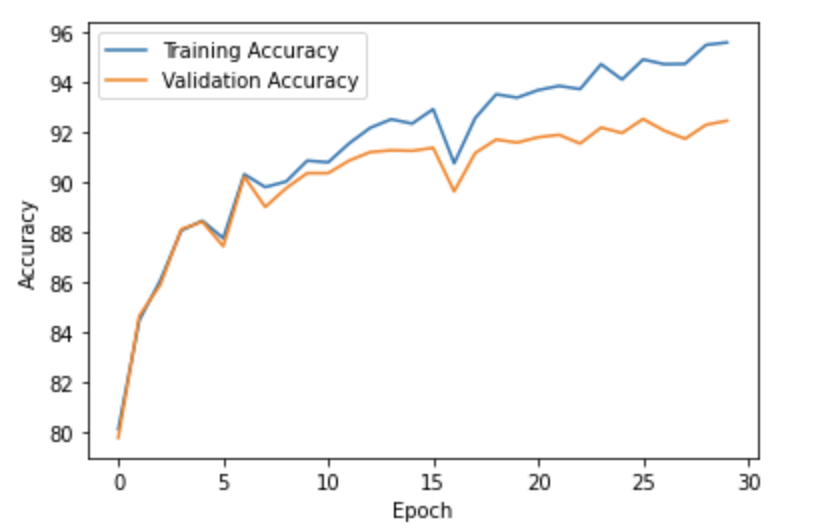
Results
This CNN was able to achieve a test set accuracy of \(91.2\%\).
Below are more class-categorized results.| Class | Accuracy | Correctly Identified | Incorrectly Identified |
|---|---|---|---|
| T-shirt/Top |
Test: 87%
Validation: 88% |


|


|
| Trouser |
Test: 98% Validation: 98% |


|


|
| Pullover |
Test: 88% Validation: 89% |


|


|
| Dress |
Test: 93% Validation: 96% |


|


|
| Coat |
Test: 89% Validation: 90% |


|


|
| Sandal |
Test: 98% Validation: 98% |


|


|
| Shirt |
Test: 62% Validation: 66% |


|


|
| Sneaker |
Test: 97% Validation: 97% |


|


|
| Bag |
Test: 98% Validation: 98% |


|


|
| Ankle Boot |
Test: 97% Validation: 97% |


|


|
Filter Visualization
Below are the learned filters from the first convolutional layer

Semantic Segmentation
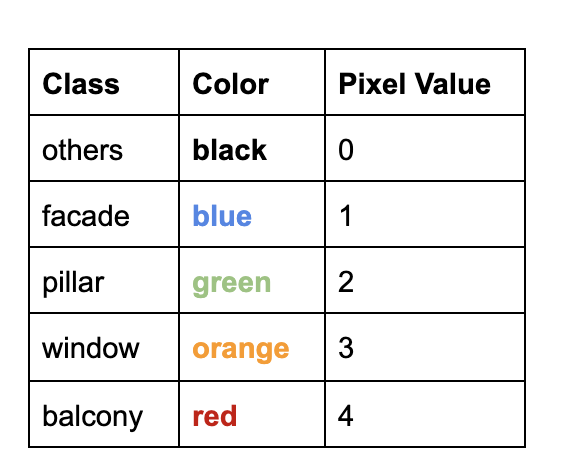
In this section, we will train a CNN to label each pixel in the image to its correct object class using the Mini Facade dataset. This dataset consists of images of different cities around the world and diverse architectural styles. We will try to segment these images into 5 different classes: balcony, window, pillar, facade and others.

Network Architecture
We split the training images into a 658 image train set and 165 image validation set. Then we used cross entropy loss with Adam at a learning rate of 0.001 and weight decay of 0.00001 and trained it on batch sizes of 1 for 10 epochs.
1. Use a 3x3 convolutional layer to go from 3 to 32 channels (padding 1).
2. Apply a ReLU.
3. Apply a 2x2 max pooling layer.
4. Use a 3x3 convolutional layer to go from 32 to 64 channels (padding 1).
5. Apply a ReLU.
6. Apply a 2x2 max pooling layer.
7. Use a 3x3 convolutional layer to go from 64 to 128 channels (padding 1).
8. Apply a ReLU.
9. Use a 3x3 transposed convolutional layer to go from 128 to 64 channels (stride 2).
10. Use a 3x3 convolutional layer to go from 64 to 64 channels (padding 1).
11. Apply a ReLU.
12. Use a 3x3 transposed convolutional layer to go from 64 to 32 channels (stride 2).
13. Use a 3x3 convolutional layer to go from 32 to 5 channels (padding 1).
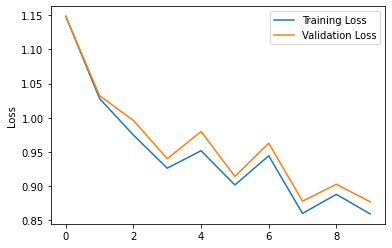
Results
This CNN was able to achieve a test set accuracy of \(0.53\%\).
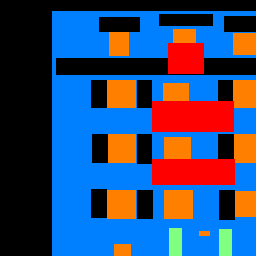
Below are the average precisions for each of the 5 classes: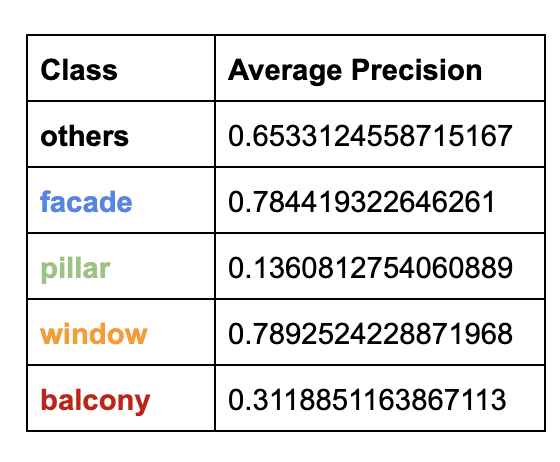 The following table contains segmented images from the test set and an additional photo of Evans hall.
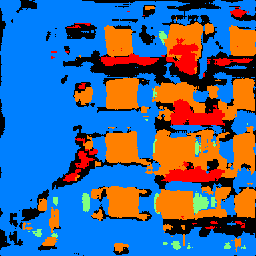
The following table contains segmented images from the test set and an additional photo of Evans hall.
| Original | Ground Truth | Segmented Image |
|---|---|---|
 |
 |
 |
 |
 |
 |
|
|
 |
 |
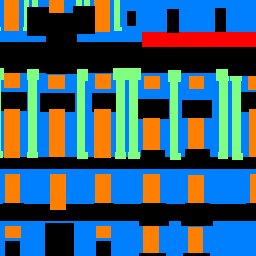 |
 |
 |
N / A |  |
It seems like our classifier has a rather hard time judging between facade and others but is able to identify windows pretty well. Balcony and Pillar probably both have low average precision because there is comparatively less comapred to facades and windows and they maybe harder to identify from the image.