The goal of this project is to use neural nets that we trained in order to classify images and their corresponding parts. We do this through a combination of convolution, sampling, and ReLUs. We use this type of architecture because of what we know about neurons and how human cognition works in terms of image recognition. Neural networks emulate the human visual cortex, with the filter weights in a neural network that classify real images bearing remarkable resemblance to the DoG filters that we can see in the human brain. In addition, we prefer convolutional methods because it makes it easier to identify components that may be in different parts of the image, since a convolution will sweep a small filter over the whole image. This in turn gives us better results than implementing only fully-connected networks.
Here is a test of the dataloader showing images and their corresponding class.
In this architecture of our neural network, we use 2 convolutional layers of 32 channels each, where each layer is followed by a ReLU. We finish this with two fully connected networks where the first layer is followed by a ReLU but the second layer is not. I played around with the number of channels by increasing them, but found that just increasing the number of channels did not yield a result that was significantly better. I also using another nonlinearity, the sigmoind function, but the runtime was too slow to yield any meaningful results. Thus, the original suggested architecture with the channel sizes and ReLU placement was what I found as optimial. However, I did find that adding a final ReLU and FC layer made my results better, so that change made it into my final network.
I used cross entropy loss as my loss function and I started training with my by using Adam with a learning rate of 0.01. However, this did not work very well, and even playing with the learning rate, my results with Adam were still poor. However, when I switched over to using stochastic gradient descent, my results were much better. For SGD, I used a learning rate of 1e-3 and a momentum of 0.9.
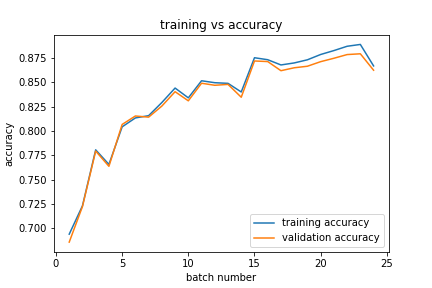
The data was trained on for two epochs. We split the 2 epochs so that we had 24 batches, meaning that each batch contained 1/12 of the original training data. The training and validation accuracies here were relatively close.
As a test of my classifications, here is the classifier run on a set of images in the dataloader.

In the per-class accuracies for the validation and test dataset, we see that the network does a good job of classifying some classes, but a relatively poor job of classifying others.


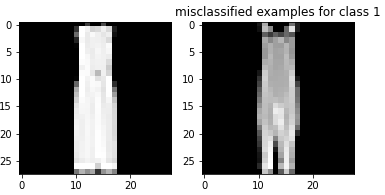
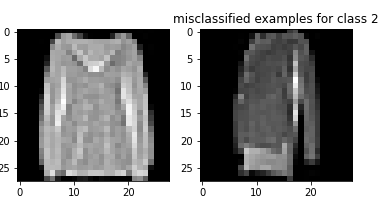
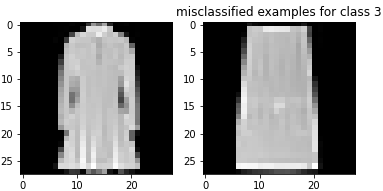
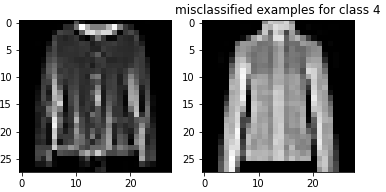
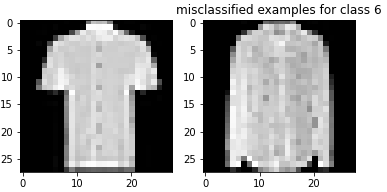
The shirt and pullover are relatively difficult to classify compared to the rest of the images. The shirt seems especially bad with respect to classification accuracy. This makes sense because there is a larger variation in shirts than the other types of clothing. Additionally, shirts and pullovers look relatively similar to each other, making them difficult to classify.
Here's the combined test accuracy of the whole model:

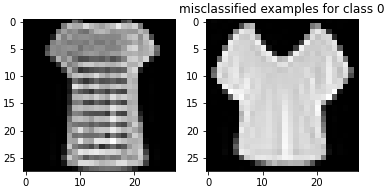
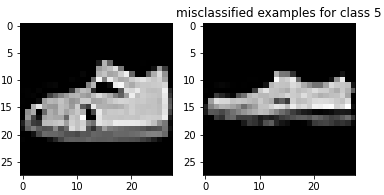
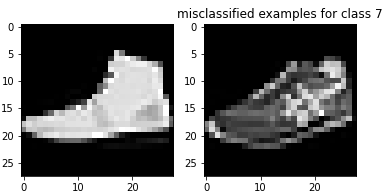
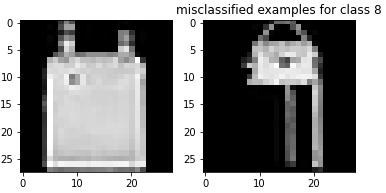
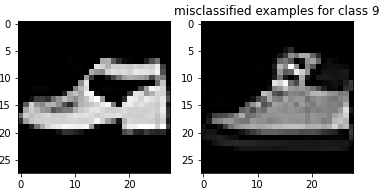
Here are examples of misclassified images from each class:
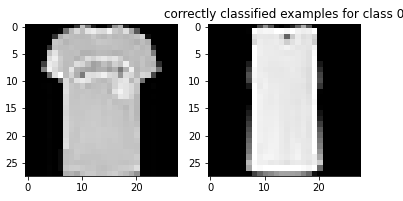
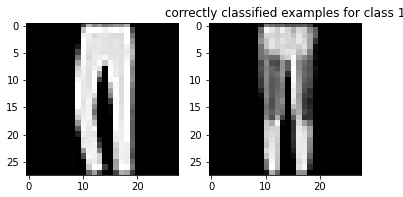
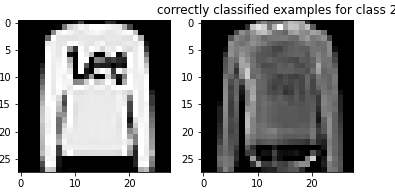
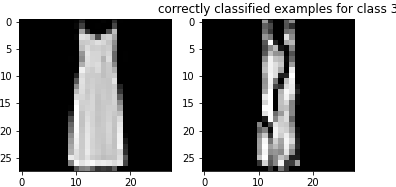
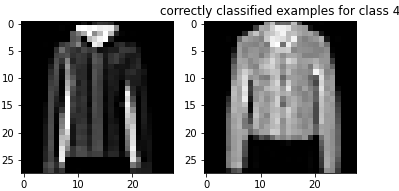
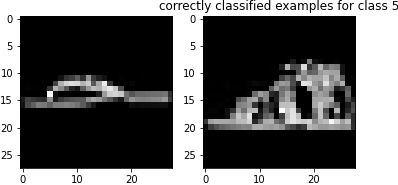
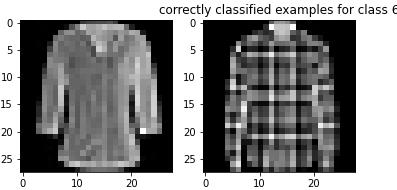
Here are examples of correctly classified images from each class:
To visualize the learned filters, we show the filters that were genereated in the first convolutional layer of our network. Yellow here is higher activation and blue here is lower activation.
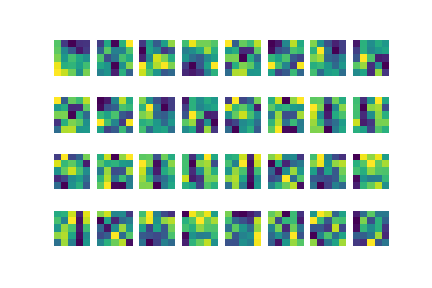
My network is structured as follows.
My training size was 800, validation size was 106, and my test set size was 114. My batch size was 16, I used 15 epochs, and I had a learning rate of 1e-3 and decay of 1e-5. My whole network ended up being size stages of convolution and ReLU. When I used a maxpool, I used a ConvT in order to make the dimensions match for the following stages. Since I maxpooled by 2, my scaling factor for the upsampling was also 2.
The precise dimensions for each of the convolutional layers and upsampling are best described by the code, which is as follows:

For the optimization process, I stuck with the suggested Adam, with a learning rate of 1e-3 and weight decay 1e-5. I tried tuning the learning rate and weight decay by substituting out the provided default values. I also changed out the optimizer from Adam to SGD and tried to tune the SGD hyperparameters. However, this time all of the changes either had no effect on the AP or made the final AP worse. Thus, I ended up deciding to stick with the default parameters and optimization method that were given to me.
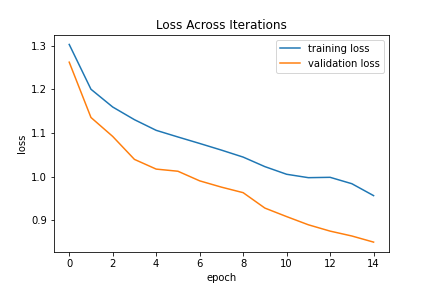
We compute the loss across iterations in the following graph. Each iteration in the graph corresponds to an epoch.
In terms of AP measurements (classes are others, facade, pillar, window, balcony in order from top down), I achieved the following numbers:

Here are example classifications. On the left is the original image, in the middle is the ground truth, and on the right is my network output.



And this is running the code on one of my own images. On the left is the original image and on the right is my network output.


The parts of this image that the classifier gets right are the windows and some of the pillars. The classifier also does an okay job identifying the balconies. The major things that fail are that the classifier cannot detect where the building ends and the sky starts, so all of the sky also gets classified into the facade. Similarly, there are three flat pillars on the left side of the building that the classifier fails to get right, probably because they lack the curvature of normal pillars. The classifier also classified a lot of stuff that wasn't a balcony as a balcony, probably because there were carvings on the side of the buildings that made the texture rough. This usually corresponds to the railings of a balcony, but in this case it was a false positive. However, I am surprised that the classifier did such a good job at identifying windows, even if it did classify some cutouts with statues as windows.