
Kelly Lin
This project used convolutional neural networks (CNNs) to (1) create a classifier for the Fashion MNIST dataset, and (2) perform semantic segmentation on the Mini Facade dataset.
The task was to create a convolutional neural network to classify images pulled from the Fashion MNIST dataset. The Fashion MNIST categorizes images into 1 of 10 categories: t-shirt/top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, and ankle boot.
Here are a few sample images from the Fashion MNIST dataset, along with their respective classes:
My final CNN consists of 2 convolutional layers, each followed by a SELU and maxpool layer. Those are then followed by 2 fully-connected layers followed by SELUs, a dropout layer with probability p=0.5, another fully-connected layer followed by a SELU, and then a final fully-connected layer. The details are described below:
Network: input > conv1 > relu1 > maxpool1 > conv2 > relu2 > maxpool2 > fc1 > relu3 > fc2 > relu4 > dropout > fc3 > relu5 > fc4 > output
I used cross entropy loss as the prediction loss, and trained the network on an Adam optimizer using a learning rate of 0.001 and a weight decay of 0. I chose a convergence value of 1, leading to the model training for a total of 5 epochs (I had set the limit to 20). I also used a batch size of 128.
Here is a graph plotting the training and validation accuracy over time:
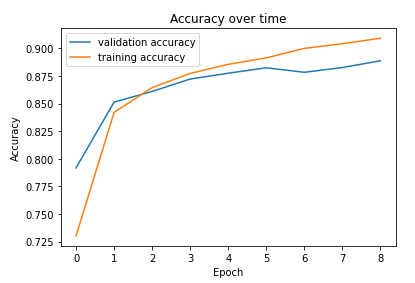
Here are the per-class accuracies on the validation and test datasets:
| Class | Validation Accuracy | Test Accuracy |
|---|---|---|
| T-shirt/top | 0.78 | 0.75 |
| Trouser | 0.96 | 0.97 |
| Pullover | 0.81 | 0.80 |
| Dress | 0.93 | 0.91 |
| Coat | 0.84 | 0.83 |
| Sandal | 0.95 | 0.95 |
| Shirt | 0.80 | 0.80 |
| Sneaker | 0.97 | 0.98 |
| Bag | 0.96 | 0.97 |
| Ankle boot | 0.93 | 0.93 |
| Overall | 0.88 | 0.88 |
The hardest classes to classify were T-shirt/top, pullover, shirt, and coat.
Here are images from each class that were classified correctly and incorrectly (Label 1 is the incorrect label that was assigned to Misclassified1, and Label 2 is the incorrect label that was assigned to Misclassified2):
| Class | Classified Correctly | Classified Correctly | Misclassified1 | Label 1 | Misclassified2 | Label 2 |
|---|---|---|---|---|---|---|
| T-shirt/top |  |
 |
 |
Bag |  |
Pullover |
| Trouser |  |
 |
 |
Dress |  |
Dress |
| Pullover |  |
 |
 |
Shirt |  |
Shirt |
| Dress |  |
 |
 |
Shirt |  |
Shirt |
| Coat |  |
 |
 |
Shirt |  |
Pullover |
| Sandal |  |
 |
 |
Sneaker |  |
Sneaker |
| Shirt |  |
 |
 |
Dress |  |
Pullover |
| Sneaker |  |
 |
 |
Ankle boot |  |
Ankle boot |
| Bag |  |
 |
 |
Shirt |  |
Pullover |
| Ankle boot |  |
 |
 |
Sandal |  |
Sneaker |
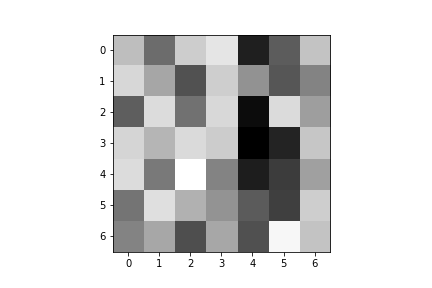
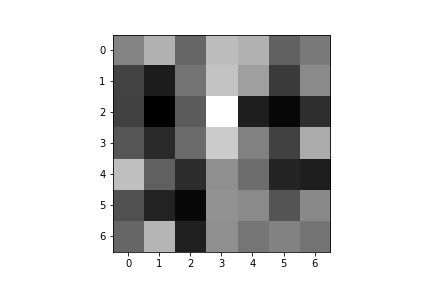
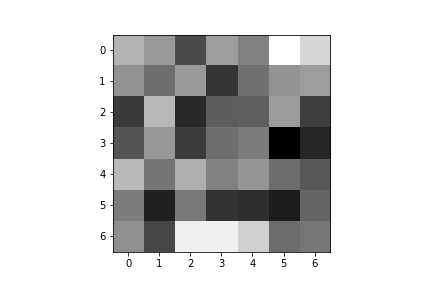
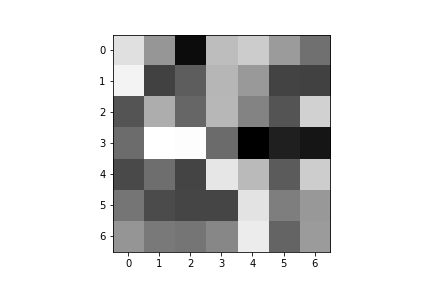
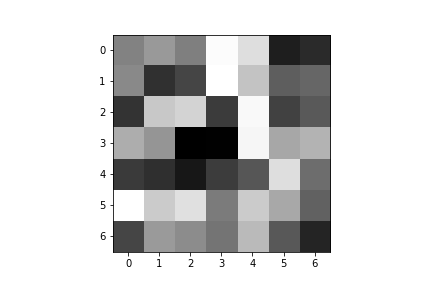
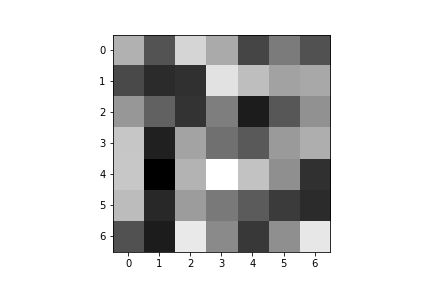
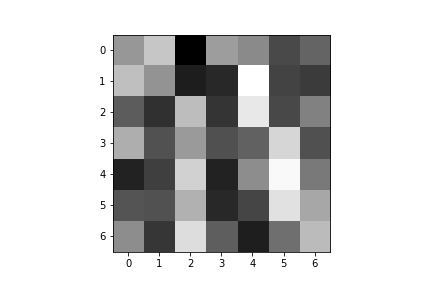
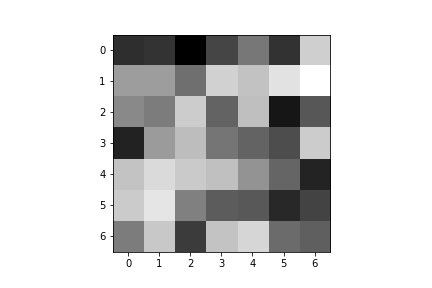
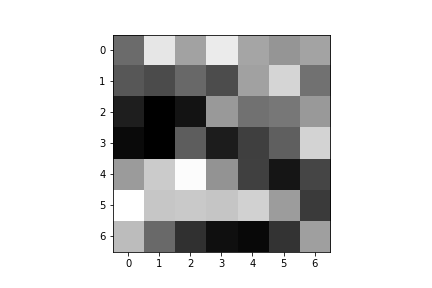
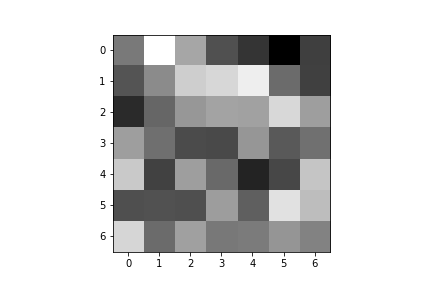
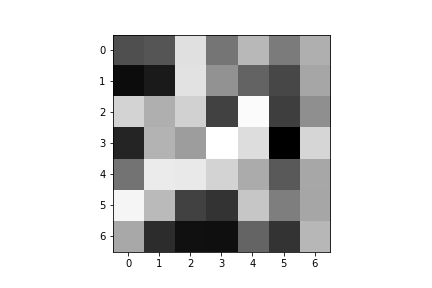
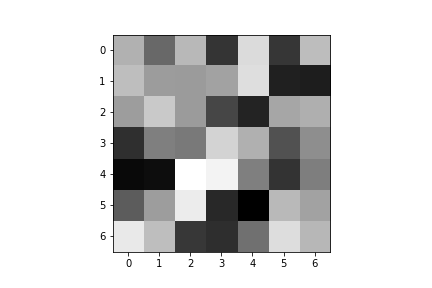
Here are the learned filters for both of my convolutional layers:
| Convolution 1: | ||||
|---|---|---|---|---|
 |
 |
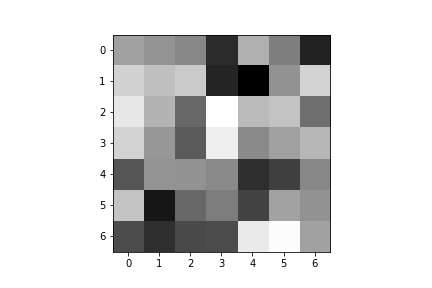 |
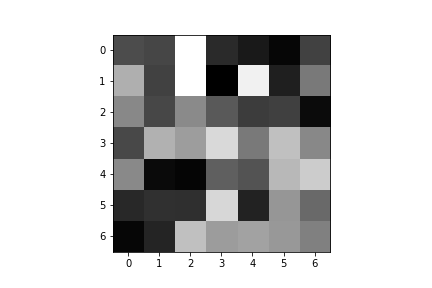 |
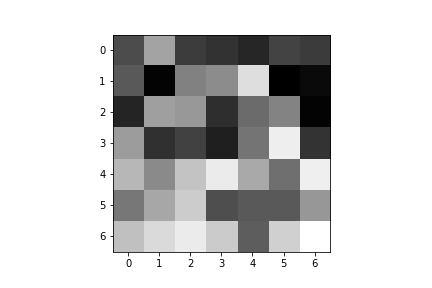 |
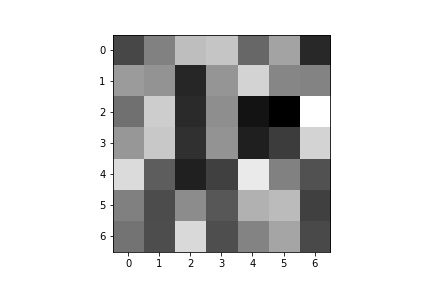 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Convolution 2: | ||||
|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
The task was to perform semantic segmentation on the Mini Facade dataset.
I split up the training data to be 80% of the original training data, and saved 20% of the data to be used for validation.
My final model architecture consisted of 6 convolutional layers, with all but the last followed by a ReLU.
Network: inputs > conv1 > relu > conv2 > relu > conv3 > relu > conv4 > relu > conv5 > relu > conv6 > output
Just like the previous part, I used the cross entropy loss for my loss function, and trained my model using the Adam optimizer. I used a learning rate of 0.001 and weight decay of 1e-5. I used a batch size of 64 (for both training and validation) and let the model train for 60 epochs.
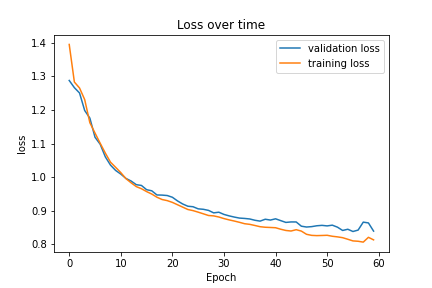
Here is the plot of the training and validation losses over time:
Here are the average precision results on the test data set:
| Class | AP Value |
|---|---|
| 0 | 0.66596 |
| 1 | 0.78164 |
| 2 | 0.149757 |
| 3 | 0.79940 |
| 4 | 0.34213 |
| Average | 0.5478 |
Below are the legend and some results from running my model on some images pulled from the Mini Facade dataset.

| Category | Image | Ground Truth | Labeled |
|---|---|---|---|
| Success |  |
 |
 |
| Success |  |
 |
 |
| Failure |  |
 |
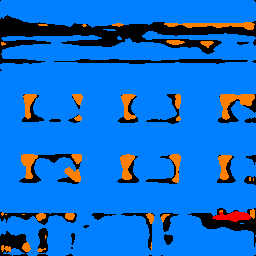 |
| Failure |  |
 |
 |
I also ran the model on one of my own images (Valley of the Temple, Hawaii). The model failed on this particular image since it misidentified nearly everything as either a balcony or facade. The training data did not deal with any examples of asian architecture, so I suspect that the lack of model familiarity led to the image segmentation failure.
| Original Image | Labeled Output |
|---|---|
 |
 |