Validation Data
Test Data
Classification and Segmentation
COMPSCI 194-26 // Project 4 // Spring 2020
By Naomi Jung // cs194-26-acs
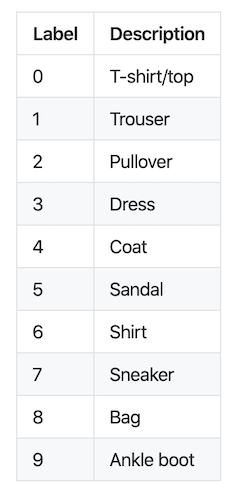
For Part 1, our goal was to classify images in the FashionMNIST dataset by labeling images as one of ten categories, listed below.
Below are a few example images in the dataset and their true categorization.

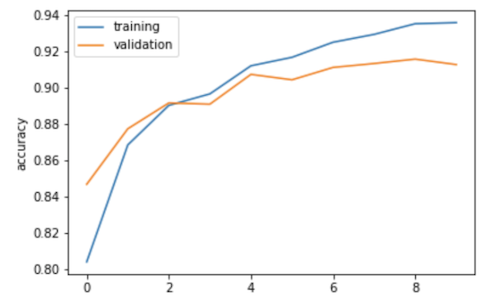
To train our model, we implemented a convolutional neural network using PyTorch. It involved 2 convolutional layers of 32 channels each, which were followed by ReLU and maxpool, and then two fully connected layers. We split the training data into training and validation sets, to finetune parameters such as the number of epochs, batch size, and learning rate. Below is a graph showing the training data and validation data accuracy over time as we trained our classifier. It makes sense that the training data continues to get more and more accurate toward the end while the validation data tapers off toward the end since we are creating the neural net using the training data only.
Once we trained our model and finetuned its hyperparameters using the validation data, we ran our model on the test data. Our classifier achieved an overall accuracy of 91.28% on the validation data and an accuracy of 90.33% on the test data.
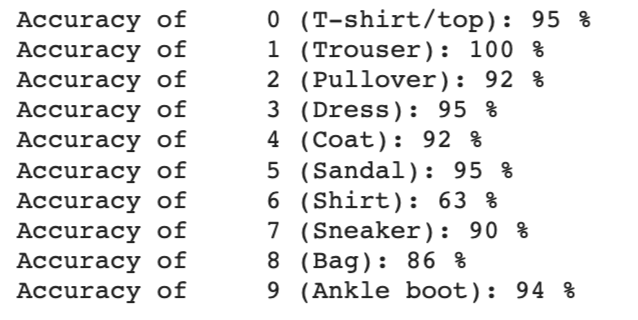
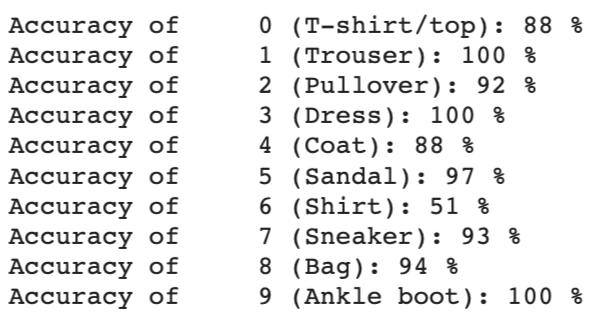
Below is a per class accuracy for our validation data and training data.
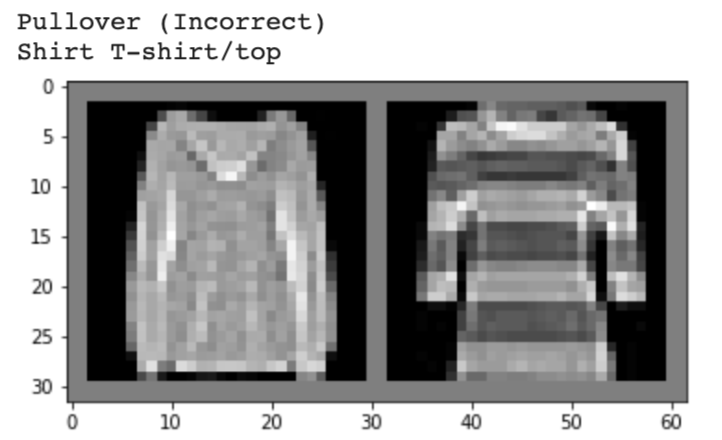
We see that label 6 ("shirt" category) was one of the most difficult categories to predict correctly. This might be because there is a lot of variability in what shirts can look like, and that shirts often look similar to other articles of clothing in different categories, such as dresses or t-shirts.
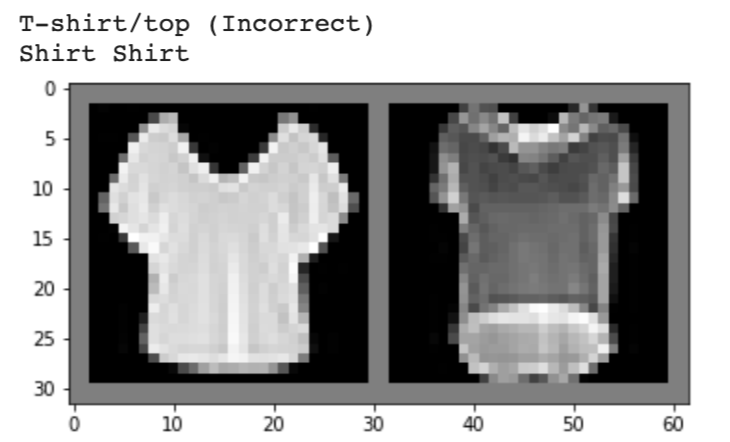
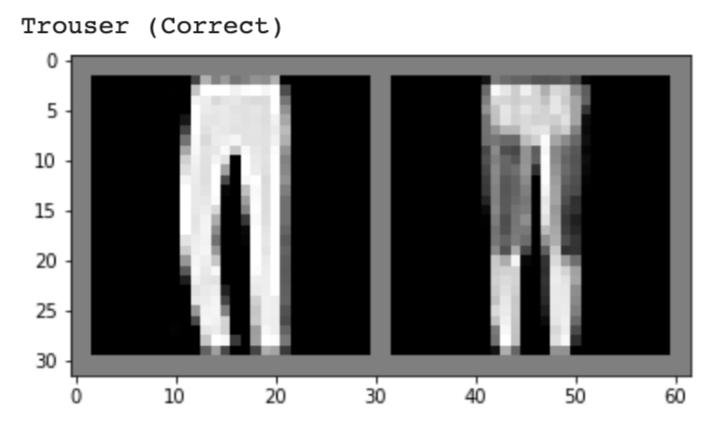
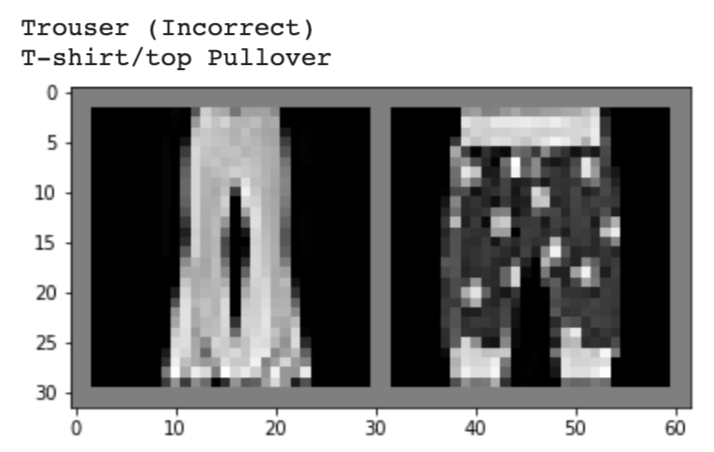
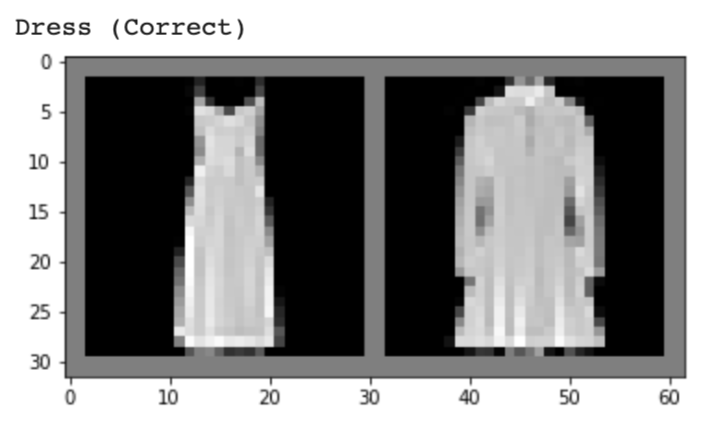
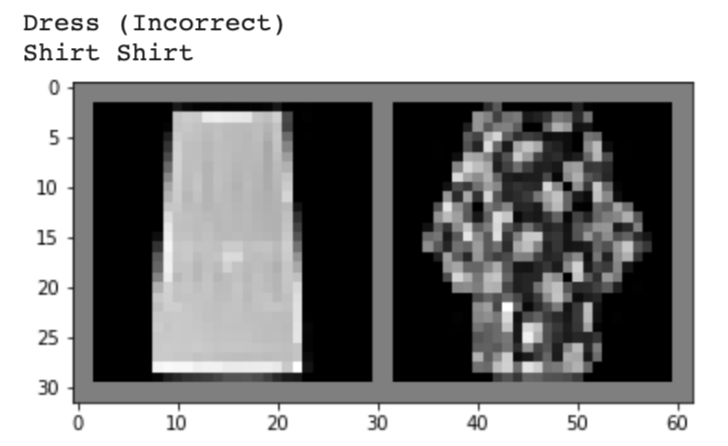
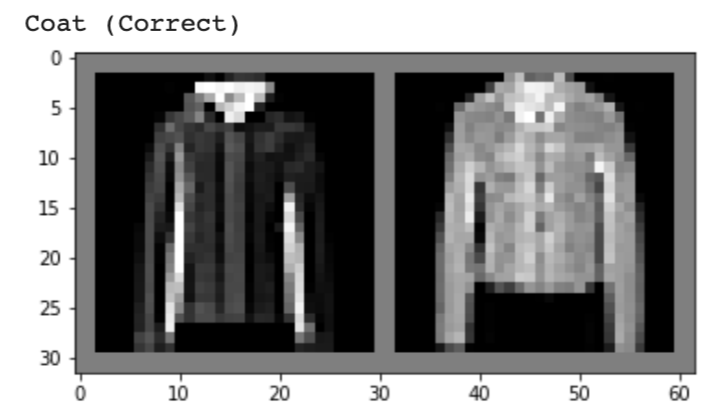
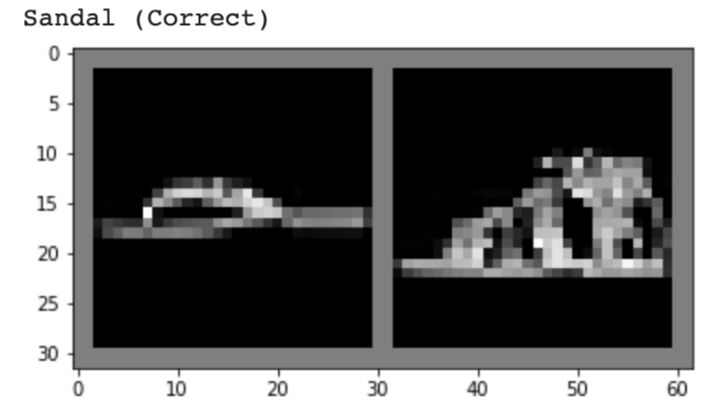
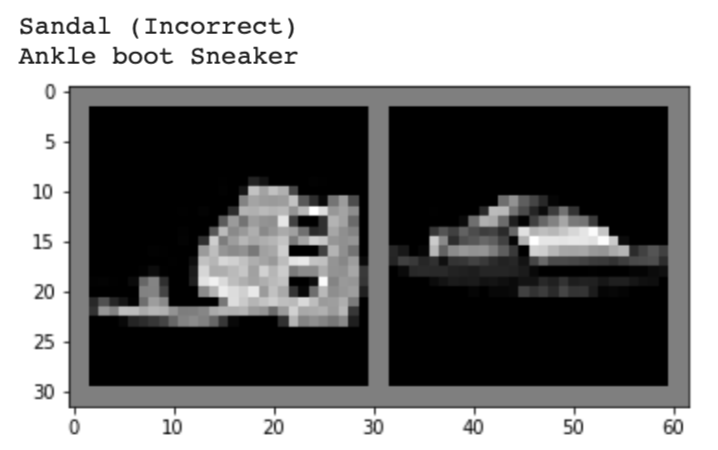
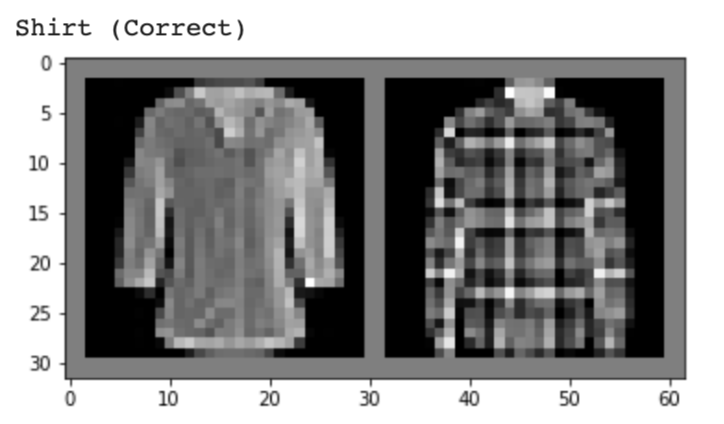
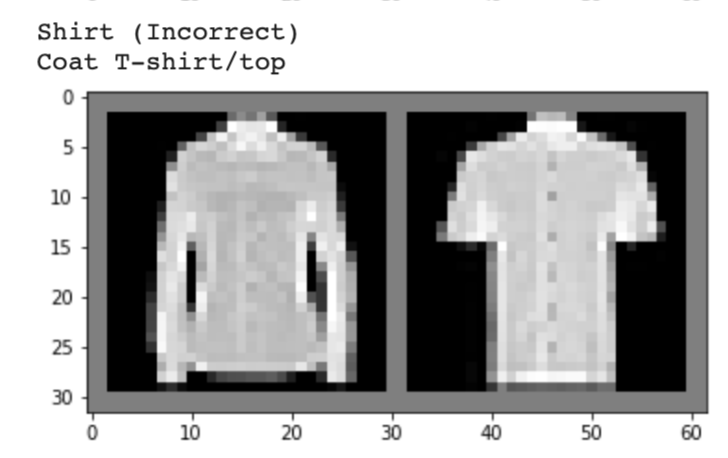
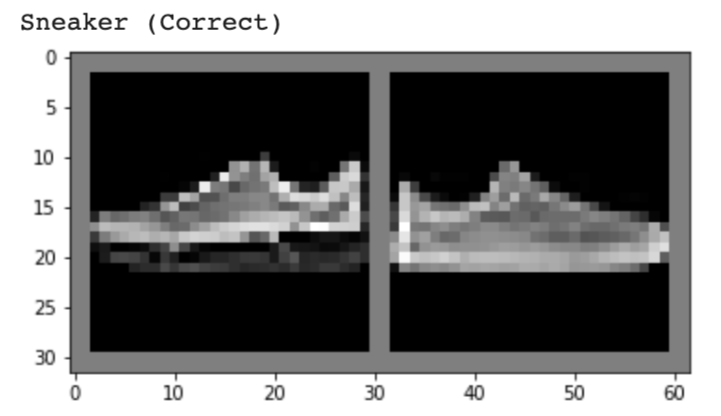
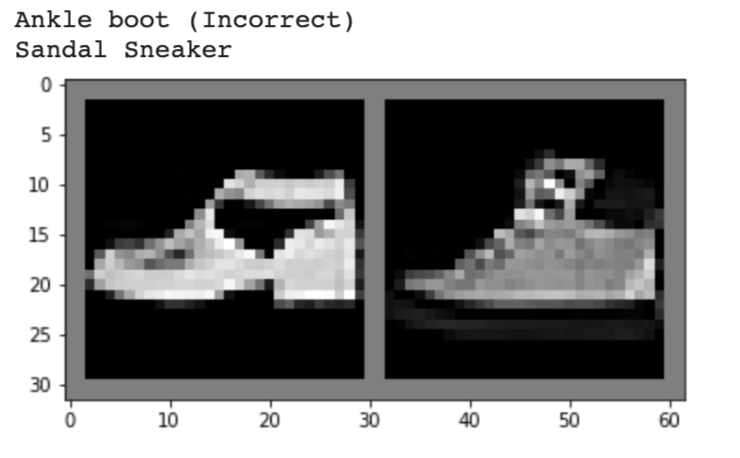
Below, I show 2 images from each class that my model classified correctly and 2 images that were classified incorrectly. The incorrectly labeled images state the labels predicted by my model.



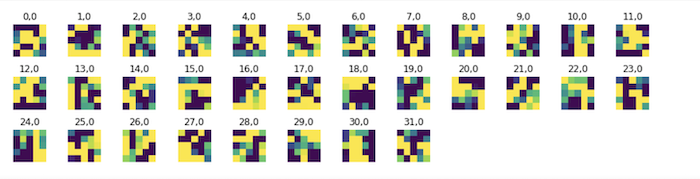
Finally, below are the 32 5x5 filters from my first convolution layer.
In this part, our goal was to segment different parts of an image into five different classes: facade, pillar, window, balcony, and other.
To train our model, I created a convolutional neural net with 5 convolution layers. Here is my detailed architecture:
1. Conv2d(3, 128, 5)
2. ReLU
3. Conv2d(128, 64, 3)
4. ReLU
5. MaxPool2d(2, 2)
6. ConvTranspose2d(64, 64, 4)
7. Conv2d(64, 32, 3)
8. ReLU
9. MaxPool2d(2, 2)
10. ConvTranspose2d(32, 32, 4)
11. Conv2d(32, 16)
12. ReLU
13. MaxPool2d(2, 2)
14. ConvTranspose2d(16, 16, 4)
15. Conv2d(16, 5, 5)
The MaxPool would downsample the images, so I used ConvTranspose to upsample and match the resolution of the input image.
I tuned my hyperparameters using 80% of the training data set, which was around 180 validation images. In the end, the parameters that gave the best results included using 50 epochs, a learning rate of 1e-3, a weight decay of 1e-5, among other parameters.
Below is the output of one of my test images. The original image has three main vertical sets of windows as well as pillars surrounding those windows. There is a small balcony at the top. My model was mostly able to classify the windows and the pillars to some degree but missed the balcony.

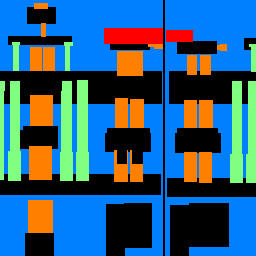
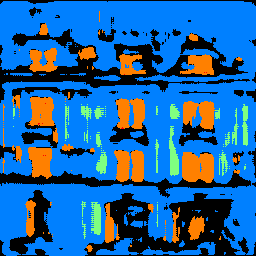
Overall, we achieved an average precision of 0.46575. Below we see the average precisions for each of the specific classes. While our model did relatively well for facades (blue) and windows (orange), but did pretty poorly for pillars (green) and balconies (red). This might be because the pillars and balconies don't take up a lot of area in the images they occur in, and so our model wasn't able to train as well on these classifications.

I tried running my model on an image of Doe Library. Below is the original and the segmented image. In general, the model did a good job of identifying the windows and the facade of the library. However, it also misclassified the pillars as windows. But as shown with the APs above, we know that our model was not very good at accurately identifying pillars so it makes sense that it failed in that area for Doe Library.


Overall, I enjoyed working on this project! It was a bit challenging since I haven't taken a machine learning course before, but I thought it was a valuable experience to learn how to use PyTorch and to gain a better understanding of how convolutional neural nets work. It was also really satisfying to see my model work in classifying clothing images and segmenting building images!