CS194-26: Image Manipulation and Computational Photography
Sping 2020
Project 4:Classification and Segmentation
Zixian Zang, CS194-26-act
Overview
In this problem, we will solve classification of images in the Fashion-MNIST
dataset and semantic segmentation of images in mini Facade dataset using Deep Nets!
Part 1: Image Classification
Section 1.1: CNN Architecture and Training Details
The input shape of Fashion-MNIST is 28*28*3. The Convolutional Neural Network I use starts with 2
convolution layers, each with 32 channels and followed by ReLU nonlinearity and 2*2 maxpooling layers.
Then there follows 3 fully connected layers, with dimensions 120, 84 and 10, followed by ReLU nonlinearity.
I use cross-entropy loss and Adam optimizer, with a learning rate of 0.001. I randomly split 20% of training
set to be validation set. The network is trained for 30 epochs and data batch of size 4.
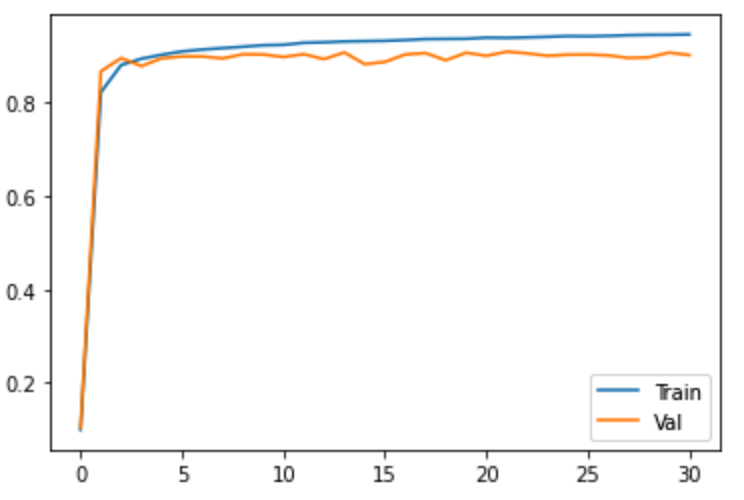
Section 1.2: Accuracy Curve
By keeping track of the network's performance on training and validation set during training process,
the curve below shows how the network improves. It is worth notice that during the ending epochs of training,
accuracy on validation stops from having significant improvement, suggesting that the network is overfitting
on the training set. This issue can be solved by adding random drop out to the model.
Section 1.3: Performance on Different Classes
| Class Name |
Accuracy (%) |
| T-shirt/top |
86 (test), 87 (validation) |
| Trouser |
96 (test), 97 (validation) |
| Pullover |
85 (test), 87 (validation) |
| Dress |
92 (test), 90 (validation) |
| Coat |
83 (test), 84 (validation) |
| Sandal |
97 (test), 98 (validation) |
| Shirt |
66 (test), 66 (validation) |
| Sneaker |
98 (test), 97 (validation) |
| Bag |
96 (test), 95 (validation) |
| Ankle boot |
95 (test), 95 (validation) |
As shown in the table above, the class that is hardest to get is SHIRT class, probably because
the images in shirt class varies a lot. The table below visualize some images in each class that are
classified correctly and incorrecly.
| Class Name |
Classified Correctly |
Classified Incorrectly |
| T-shirt/top |
  |
  |
| Trouser |
  |
  |
| Pullover |
  |
  |
| Dress |
  |
  |
| Coat |
  |
  |
| Sandal |
  |
  |
| Shirt |
  |
  |
| Sneaker |
  |
  |
| Bag |
  |
  |
| Ankle boot |
  |
  |
Section 1.4: Visualize Learned Filters
Visualize the 32 filters learned by the first convolution layer. Is is remarkable that some filters
successfully capture important details in the training data.
Part 2: Semantic Segmentation
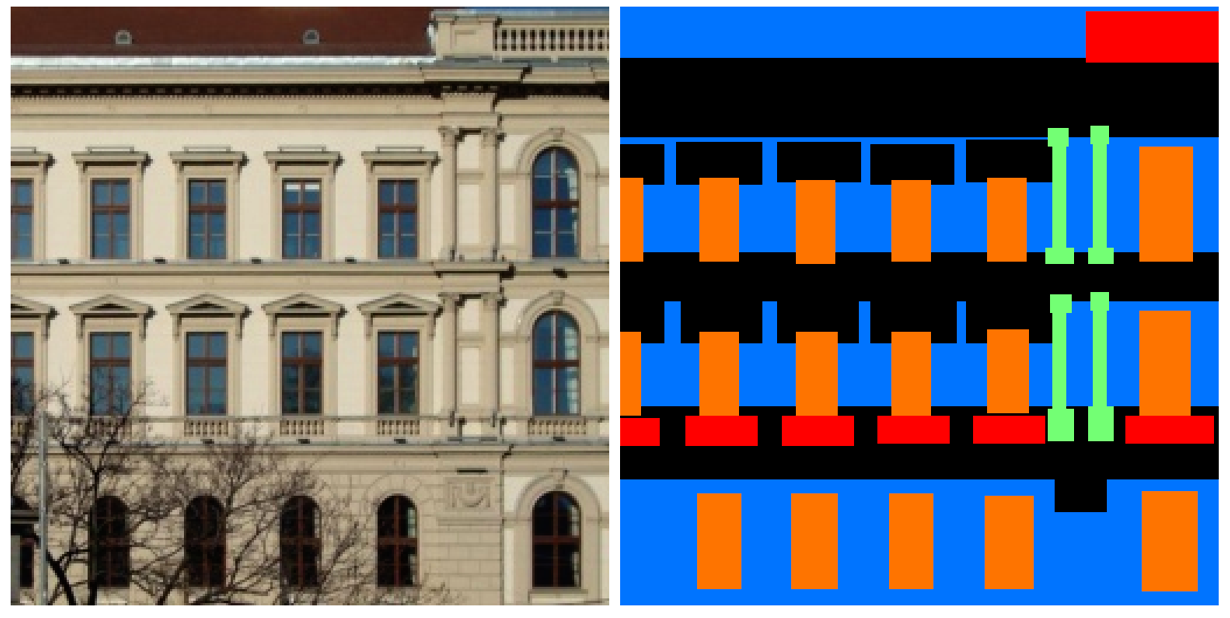
Mini Facade dataset consists of images of different cities around the world and diverse
architectural styles (in .jpg format), shown as the image on the left. It also contains
semantic segmentation labels (in .png format) in 5 different classes: balcony, window,
pillar, facade and others. The task is to train a network to convert image below from the one
on the left to the labels on the right. The color to label map is shown below.
Section 2.1: CNN Architecture and Training Details
I use a CNN with 6 convolution layers, with 32, 128, 512, 128, 32 and 5 channels respectively, and every
one but the last layer is followed by ReLu nonlinearity. No maxpooling and upsampling is used, and in order
to maintain the shape of the data, I use padding size 2 along with the kernel size 5*5. I use cross-entropy loss
and the network is trained with Adam with a learning rate of 1e-3 and weight decay 1e-5. The network is trained
for 50 epochs, and 20% of training data is used as validation set.
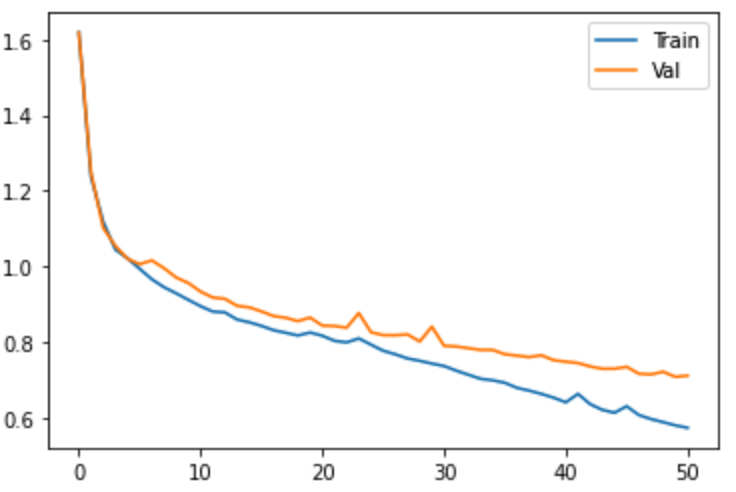
Section 2.2: Learning Curve
By plotting the training and validation loss during the training process, we can see that
the network slowly overfits, as the training loss keeps on decreasing but the validation loss
does not shown significant improvement.
Section 2.3: Results and Analysis
At the end of day, the network manages to achieve 57% overall AP (Average Precision) accuracy on test set.
To be honest it is surprisingly high for such a simple structured CNN. Besides the pillar channel, all other channels
exceed 65% AP accuracy. Here are some results generated from the testing images.
Input 1

|
Segmentation 1

|
Label 1

|
Input 2

|
Segmentation 2
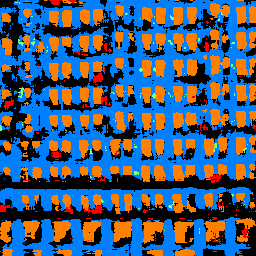
|
Label 2

|
I also try to generate segmentation from my own source image. Here is the result. This is a photo
of the Doe Library in UC Berkeley. Notice that the network performs well on capturing the windows but
does relatively poorly capturing pillars.
Input Image

|
Segmentation

|