Project Overview
In this project, I practiced building and tuning convolutional neural networks with pytorch to solve classification and semantic segmentation problems.
Part 1: Image Classification
In this part, we trained a convolutional neural network that classifies images in the Fashion MNIST dataset into clothing categories. Each image is a 28x28 grayscale image of a piece of clothing item belong to one of the ten categories. There are 60000 training examples and 10000 test examples. I splitted the training examples by 90-10, so 54000 of them are used as training data, and 6000 are validation data. After tuning the hyperparameters, I tested the network on the test set.
The structure of the convolutional neural network trained is as follows:
- Convolutional layer with 1 input channel, 32 output channels, and 3x3 resolution/filter size -> ReLU -> 2x2 Max Pooling ->
- Convolutional layer with 32 input channels, 32 output channels, and 3x3 resolution -> ReLU -> 2X2 Max Pooling ->
- fully connected layer with 1152 input features, 120 output features -> ReLU ->
- fully connected layer with 120 input features, 10 output features, which are the values for each class
I used batch size = 64, ReLU non-linearity, ASGD as the optimizer with a learning rate of 0.01 and weight decay of 0.0005. The prediction loss used is the cross-entropy loss. I trained the network for 30 epochs. Here is the training set and validation set accuracy across epochs.
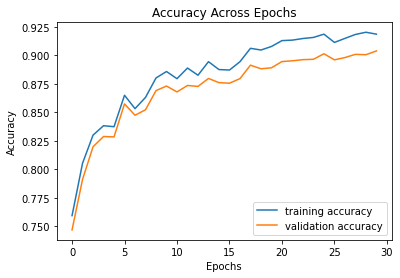
|
Then, I switched to Adam optimizer with learning rate = 0.001 and trained for another 10 epochs, this brings up the accuracy of the training and validation set accuracy a bit more. I lowered the learning rate since the model already has a decent accuracy, and we want to minimize the gradiant descent overshoot. The following plot shows the accuracy progression. At the end, we can see that the model is starting to overfit the training data.
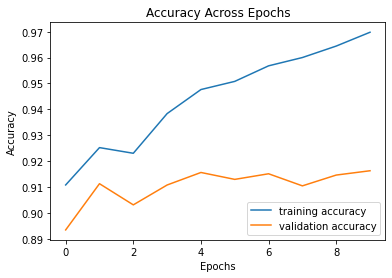
|
Finally, we test the trained network on the test set, and the overall accuracy is 91%. Accuracy per class is as follows:
| Class | Test set Accuracy | Validation set Accuracy |
|---|---|---|
| T-shirt | 85% | 96% |
| Trouser | 99% | 100% |
| Pullover | 87% | 97% |
| Dress | 91% | 98% |
| Coat | 82% | 85% |
| Sandal | 98% | 98% |
| Shirt | 74% | 87% |
| Sneaker | 95% | 99% |
| Bag | 97% | 100% |
| Ankle Boot | 94% | 94% |
We can see that the categories with higher accuracies are trousers, sandals, sneakers, bags, and boots, whereas the category with the lowet accuracy is Shirt. This is understandable since T-shirt, pullover, and shirt can look quite similar and are thus more difficult to distinguish.
Here are some images that are classified correctly. (2 examples per class)

|

|

|

|

|
|

|

|

|

|

|

|

|

|
|

|

|

|

|

|
Here are some images that are classified incorrectly. (2 examples per class) Some of these images are pretty difficult to classify even with the human eye, since the image is so low-resolution and pixelated.

|
|
|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
Here are the 32 trained filters of the first layer of this convnet. There is no apparent pattern that matches with the clothing categories, but they do indeed look like they would produce very distinct activation maps.
|
|
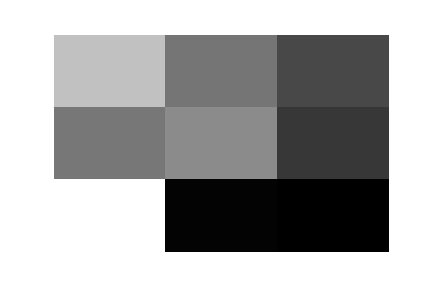
|
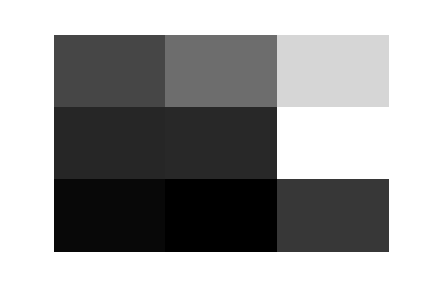
|
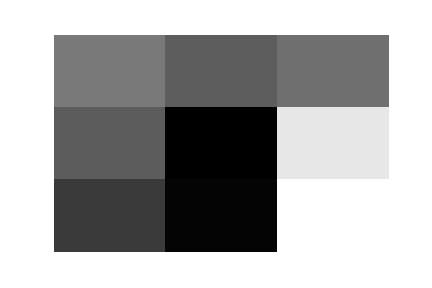
|
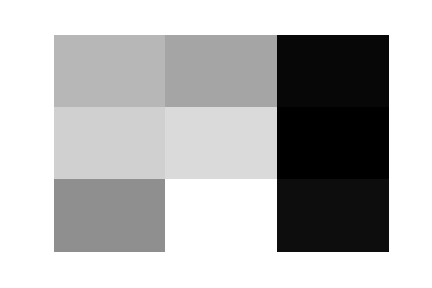
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
Part 2: Semantic Segmentation
In this part of the project, I constructed and trained a convolutional neural network that aims to produce a semantic segmentation of an image composing of five types of architectural elements. We attempt to label each pixel of the original image with the correct object class: facade, pillar, window, balcony, or other. We first load the miniFacade dataset and split the training set into training data (800 items) and validation data (105 items). Then, we construct the following network:
- Convolution Layer 1: input 3 channels, output 64 channels, 3x3 filters, followed by BatchNorm and ReLU
- Convolution Layer 2: input 64 channels, output 128 channels, 3x3 filters, padding = 1, followed by BatchNorm and ReLU
- 2x2 Max Pooling, padding = 1
- Convolution Layer 3: input 128 channels, output 128 channels, 3x3 filters, followed by BatchNorm and ReLU
- Convolution Layer 4: input 128 channels, output 256 channels, 3x3 filters, padding = 1, followed by BatchNorm and ReLU
- 2x2 Max Pooling, padding = 1
- Convolution Layer 5: input 256 channels, output 128 channels, 3x3 filters, followed by BatchNorm and ReLU
- Convolution Layer 6: input 128 channels, output 64 channels, 3x3 filters, padding = 1, followed by BatchNorm and ReLU
- Replication Pad by 1
- ConvTranspose layer 1: input 64 channels, output 32 channels, kernel size = 2, stride = 2, followed by ReLU
- ConvTranspose layer 2: input 32 channels, output 5 channels, kernel size = 2, stride = 2.
Paddings are used to maintain the shape of the activation maps. The final output of the network is 5x256x256, since each image is 256x256, and for each pixel there are five classes of options. Cross entropy loss is used as prediction loss, and Adam with a learning rate of 0.001 and weight decay of 0.00001 is used as the optimizer. Batch size = 1, and ReLU is the non-linearity chosen.
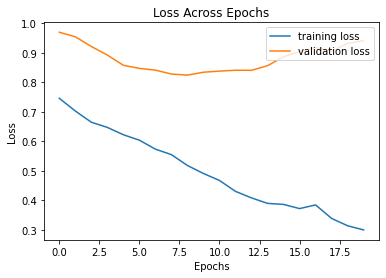
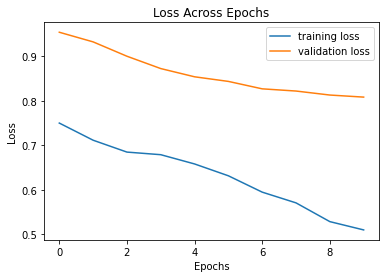
I trained through 20 epochs, and the following is the progression of training loss and validation loss along epochs. We see that the overfitting of the training set occurs at around the 10th epoch, and validation loss starts to increase, so the final model is trained with 10 epochs. The final AP on the test set is 0.5454.
|
|
The final AP evaluation on test set is as follows:
| Class | AP |
|---|---|
| others | 0.5074 |
| facade | 0.6724 |
| pillar | 0.2196 |
| window | 0.8180 |
| balcony | 0.5094 |
| average | 0.5454 |
Let's look at some photos that are segmented by this trained network. We see that the windows are relatively well captured, and the balconies in the second image is also somewhat captured in the segmentation result. The irregular shape of the occluding sculptures in the first photo and the tree in the second photo may have made it harder for the network to classify some regions. For example, the lower region of the first photo should not be classified as facade, and the lower left region of the econd photo should not be classified as balconies.

|

|

|
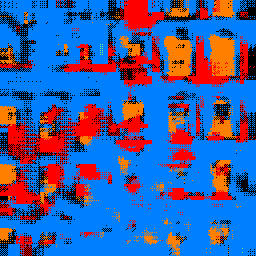
|
Here are some more segmented examples of this network compared to the original photo and the ground truth. We see that windows are decently recognized, but pillars and balconies are more difficult.

|

|

|

|

|

|
Final Reflections
This project has been really helpful in concretizing the knowledge we learned on designing and training CNNs. I definitely climbed the learning curve of using pytorch and Colab, and I found training networks and tuning hyperparamsters to be really fun, sometimes mysterious, and also very rewarding.