CS294-26 Project 4
Fuyi Yang
Overview
In the first part of the project we are going to classifty Fashion_MNIST dataset into ten classes. Firstly, dataset is loaded and converted to tensors. Severl sample
images are displayed. Then we build a CNN consisting of 2 convolutional layer, 2 fully connected linear layer and one output layer. After each conv layer and linear
layer, a ReLU followed by a maxpool is added. The cross entropy loss and Adam optimizer are used for prediction.
The second part of the project aims to achieve semantic segmentation of Mini Facade Dataset which is able to label each pixel in the image to its correct object class.
There are five classes encoded by different colors. A CNN made of 5 convolutional layer and 1 tansposed convolutional layer is used for training. Cross entropy loss
and Adam optimizer are used here to achieve an Average Preciseion (AP) over 0.45.
Part1
The batch_size is 32 and 20% of the training dataset are chosen to be the validation dataset.
| Sample images and their labels: |
 |
|
| Train and validation accuracy during training process: |
 |
|
Accuracy per class on the validation and test dataset:
|
Validation: |
Test: |
|
| T-shirt/top |
87% |
86% |
|
| Trouser |
95% |
97% |
|
| Pullover |
64% |
69% |
|
| Dress |
88% |
86% |
|
| Coat |
87% |
85% |
|
| Sandal |
96% |
96% |
|
| Shirt |
38% |
39% |
|
| Sneaker |
96% |
96% |
|
| Bag |
94% |
95% |
|
| Ankle boot |
91% |
88% |
|
Correct and incorrect classifications for each class:
|
Correct: |
Incorrect: |
|
| T-shirt/top |
 |
 |
|
| Trouser |
 |
 |
|
| Pullover |
 |
 |
|
| Dress |
 |
 |
|
| Coat |
 |
 |
|
| Sandal |
 |
 |
|
| Shirt |
 |
 |
|
| Sneaker |
 |
 |
|
| Bag |
 |
 |
|
| Ankle boot |
 |
 |
|
Learned filters (32):
Part2
Architecture of the CNN and hyperparameters chosen fot the traiing:
Five convolutional layers with two maxpool layers and one transposed convolutional layer for upsampling are used for training:
Conv2d(3,128,3,1,1) -> ReLU -> Conv2d(128,256,3,1,1) -> ReLU -> Maxpool(2,2) -> Conv2d(256,128,3,1,1) -> ReLU -> Conv2d(128,128,3,1,1) -> ReLU -> Maxpool(2,2)
-> ConvTranspose2d(128,64,6,4,1) -> Conv2d(64,5,3,1,1)
20% of the training dataset are chosen to be the validation set. Cross entropy loss is used as prediction loss. Adam optmiizer with learning rate 1e-3 and
weight decay 1e-5 is used for training.
| Train and validation loss during training process: |
 |
|
| Classes: |
AP: |
|
| Others |
0.6619 |
|
| Facade |
0.7851 |
|
| Pillar |
0.1336 |
|
| Window |
0.8087 |
|
| Balcony |
0.3766 |
|
| Average |
0.5532 |
|
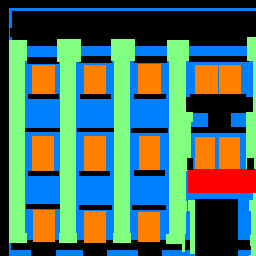
Examples from test set:
| Input Image |
Ground truth |
Predicted label |
|
 |
 |
 |
|
 |
 |
 |
|
Flinders Street Railway Station from my collection:
| Input Image |
Predicted label |
 |
.png) |
|
As it can been seen from the examples above, Window(orange) and Facade(blue) are well predicted while it is difficult to identify Pillars(green). Furthermore,
due to the fact that training dateset images are always within the boundaries of the building, it will fail to predict the surroundings outside the building like
the Railway Station case above.
