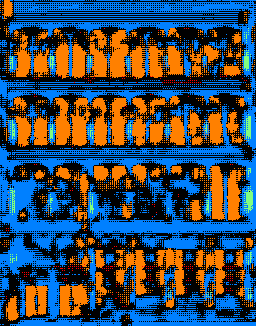As suggested by the project spec, I used two convolutional layers (each followed by a 2x2 maxpooling and a ReLU), followed by a fully connected layer (2304 to 120) with a ReLU and one final fully connected layer (120 to 10). I started with 32 layers, but later increased to 64 layers for a bit of a performance increase. I performed a hyperparameter sweep to find the optimal filter sizes of the two convolutional layers in this CNN. I swept over sizes from 2x2 to 9x9 (thus I tried 89 combinations in total), each one training for 15 epochs. I used a GPU that I rented on Google Cloud to reduce the training. I found that the optimal filter size for both layers was 2x2. I also experimented with the Adam vs SGD optimizer and different learning rates/weight decays after I had decided on this filter size - the one I had most success with was SGD with lr=0.01, momentum=0.9, and weight_decay=5e-4. However, it's worth noting that to find the true best parameters for this net, I would have to try all of the optimizers with all of the filter sizes again. It's possible that I overlooked an optimal filter size combination because I did not apply the right optimizer. I used a batch size of 50 because the images are quite small.
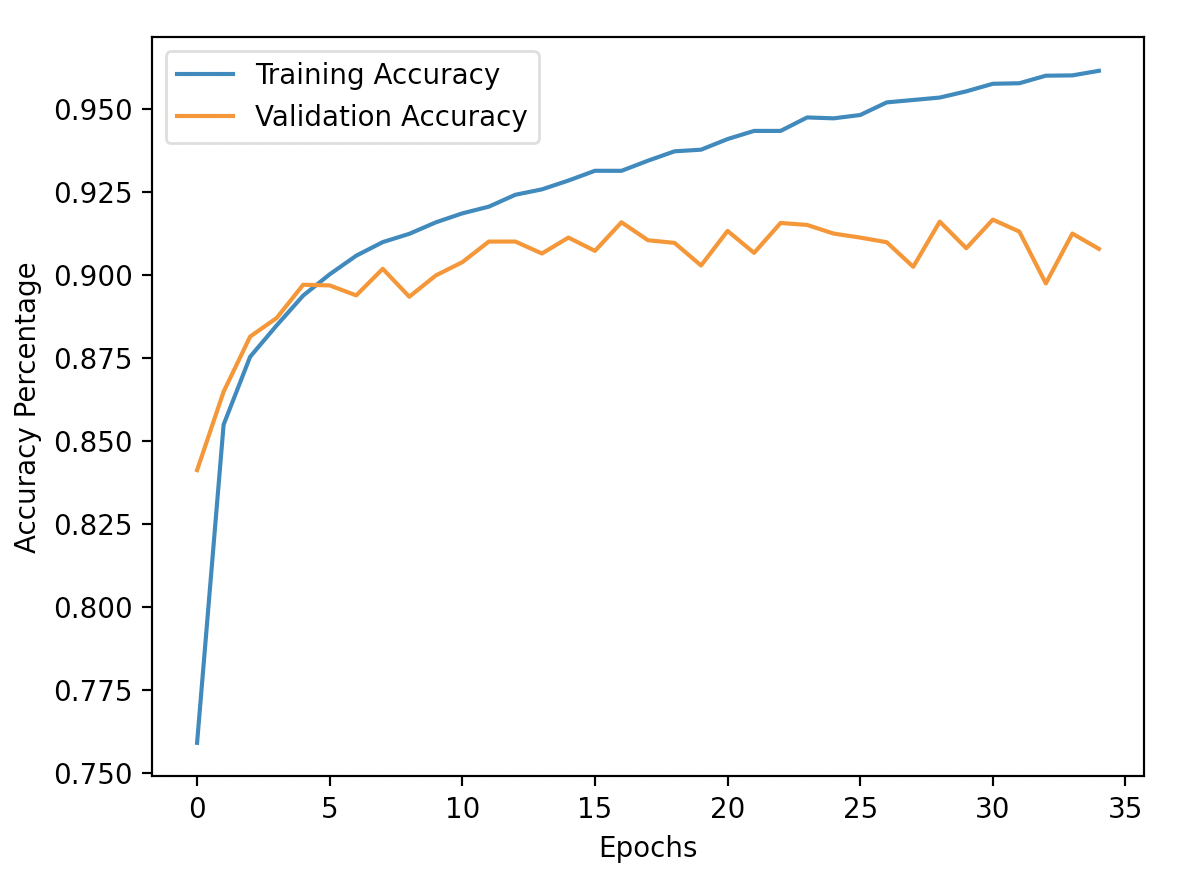
With this model, I achieved an overall accuracy of 90.38%. The following are the breakdowns by class:
Accuracy of T-Shirt : 92%
Accuracy of Pants : 97%
Accuracy of Pullover : 77%
Accuracy of Dress : 86%
Accuracy of Coat : 88%
Accuracy of Sandal : 96%
Accuracy of Shirt : 71%
Accuracy of Sneaker : 98%
Accuracy of Bag : 98%
Accuracy of Ankle Boot : 96%
The mistakes that my classifier made were certainly understandable. Looking at incorrectly classified images below, some of them were mistakes that I could have made myself. For example, the images labeled as sandals do look like sandals (there are holes or at least dark spots on the sneaker/boot which look like something sandals might have). One of the images misclassified as a dress just looks like a white rectangle - it could easily be a shirt, t-shirt, or dress.
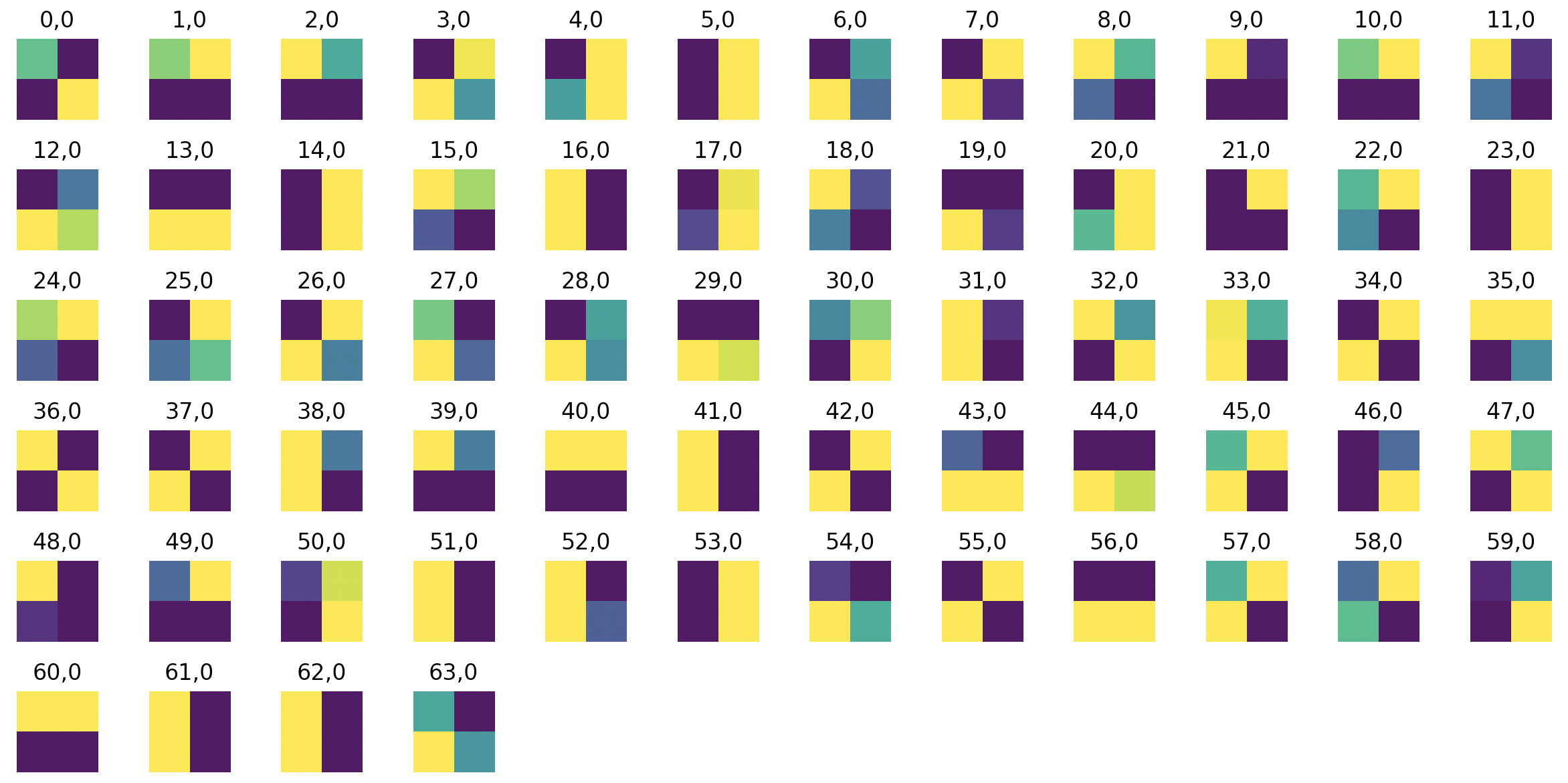
These are the 64 2x2 filters of first layer of the CNN, after training. 2x2 is quite a small filter size, so with 64 unique filters we see pretty much every possible combination of cell values, including horizontal and vertical edge detectors.
Using my experience from part 1, I hypothesized that small filters were the way to go. I actually got pretty lucky and had good performance within the first few designs that I tried. My final network was very simple, and is described by the following code block. It is essentially 5 repetitions of a 3x3 convolution, a ReLU, a 2x2 max pooling, and an upsampling by 2 (to keep the same dimension after the max pooling).
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.ConvTranspose2d(32, 32, 2, stride=2, padding=0),
nn.Conv2d(32, 32, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.ConvTranspose2d(32, 32, 2, stride=2, padding=0),
nn.Conv2d(32, 32, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.ConvTranspose2d(32, 32, 2, stride=2, padding=0),
nn.Conv2d(32, 32, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.ConvTranspose2d(32, 32, 2, stride=2, padding=0),
nn.Conv2d(32, 32, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.ConvTranspose2d(32, self.n_class, 2, stride=2, padding=0)
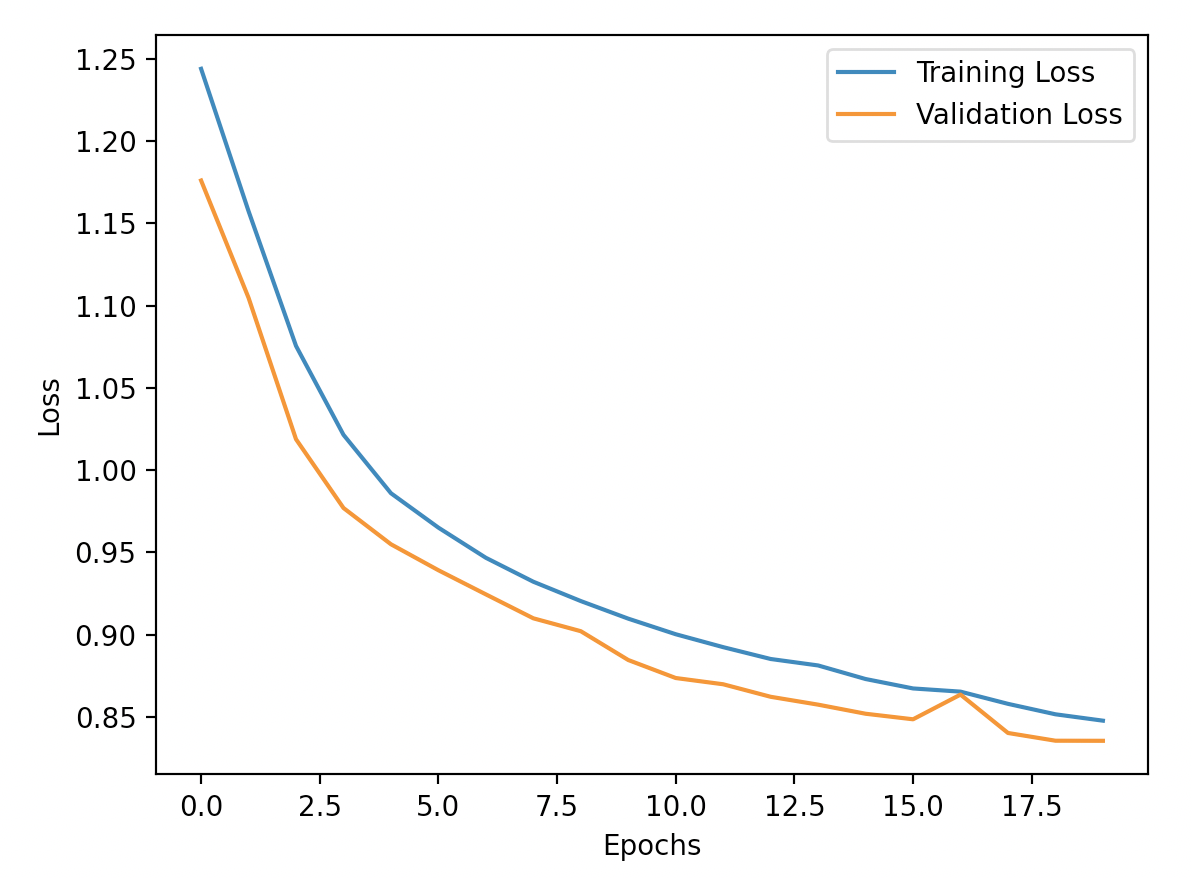
I experimented with additional layers beyond 32, but found that they mostly slowed down training time and did not improve the performance. I also found that that the Adam optimizer with parameters lr=1e-3, weight_decay=1e-5 worked the best. The default learning rate of 1e-2 was too fast (the loss decreased rapidly with the first few epochs, but then stagnated at a mediocre level as the network oscilated around a local minimum but never reached it). A batch size of 1 worked well for me.
With this network training for 20 epochs I achieved an average AP of 0.5383507478583202. Here are the breakdowns by class:
Others: AP = 0.6420657638904688
Facade: AP = 0.7657141401559255
Pillar: AP = 0.13364831856577875
Window: AP = 0.7689545532414854
Balcony: AP = 0.3813709634379425
This is photo of a restaurant facade in Chicago. My segmentation model performs well to identify the windows and facade on most of the image, but fails to identify the columns at all. There are no balconies, so no problems there.