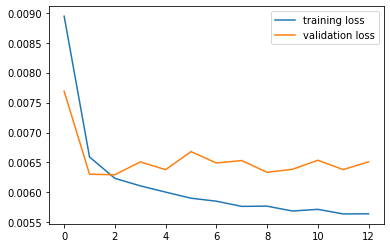
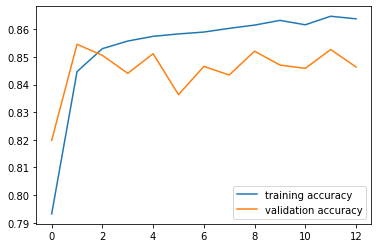
Using the suggested naive network, we train it for 15 epochs. The training and validation losses and accuracies are as follows:
|
|
|---|
The network achieves a highest validation accuracy of 0.855. As we can see from the trainig process, the model converges very fast in a few epochs due to the small input size, the shallowness of the network and that the learning rate is too high.
To achieve a better result, we switch a simple ResNet consists of two residual blocks and two FC layer at the end (I don't think the residual connections actually helped the training since the network is way too shallow. However I was plan to use a deeper netwokr, but this shallow already got a satisfiable result so I stopped there):
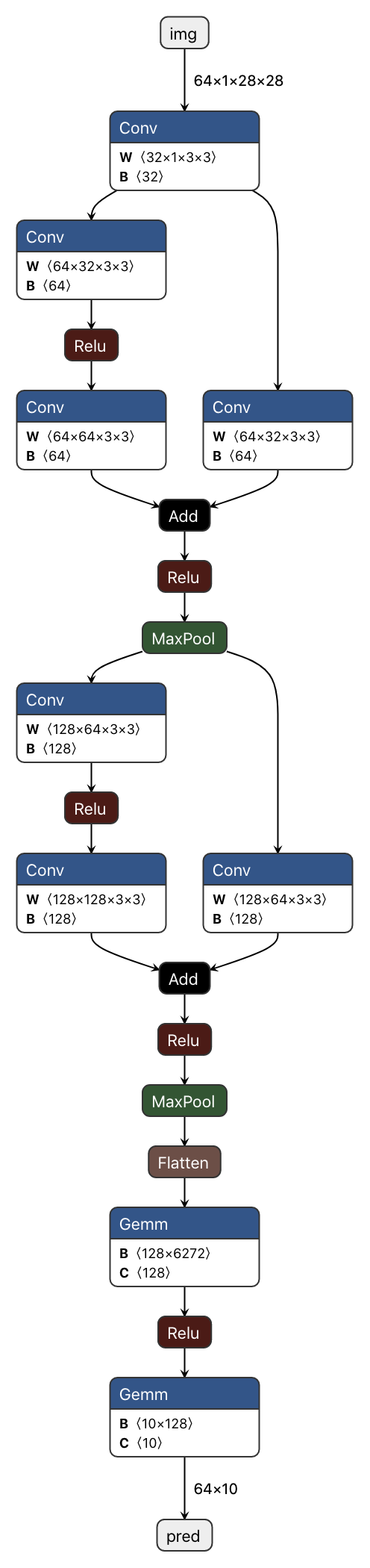 (click to open)
(click to open)
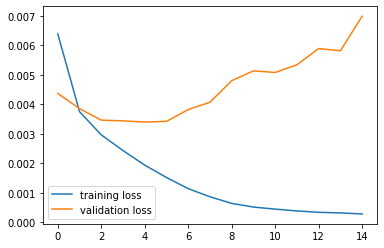
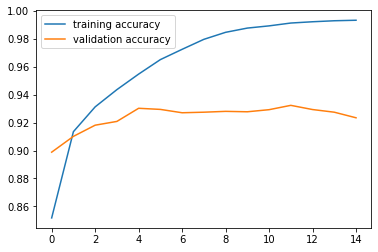
We also decrease learning rate to 3e-4 to smooth out the trainig. Below is the training and validation losses and accuracies during the training process:
 |
 |
|---|
We achieve a highest validation accuracy of 0.932. All results below are based on the weights at that epoch.
Below is the confusion matrix of the model:
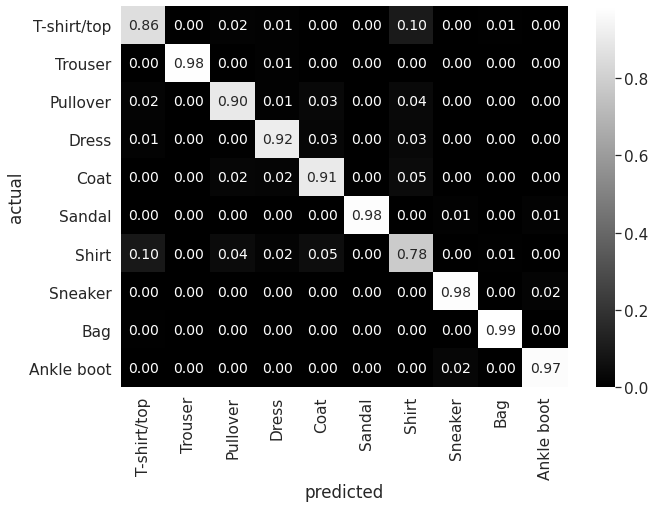
As we can see from the matrix, trousers and bags are easier to classify, but the model is having trouble with distinguishing between shirts, T-shirts, pullovers and coats. This is to be expected, since the input resolution is very low even for human eyes.
Below is some correct and wrong predictions from the network:

Below is the layer 1 features learned by the model. Since we use a 3x3 convolution as the first layer, these features are harder to interpret given their sizes.

We use a shallower U-Net to tackle semantic segmentation on the mini-facade dataset. We define down-convolution block as consisting of two Conv-BatchNorm-ReLU sets and a max pooling layer:
ConvBlock(in_channel, out_channel):
nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
ConvDown(in_channel, out_channel):
ConvBlock(in_channel, out_channel),
nn.MaxPool2d(2)
We define a up-convolution block as two Conv-BatchNorm-ReLU sets and a transposed convolutional layer with a kernel size of 2 and stride 2 to simulate upsampling 2x:
ConvUp(in_channel, out_channel):
ConvBlock(in_channel, out_channel),
nn.ConvTranspose2d(out_channel, out_channel, 2, stride=2)
The final model is consisting of 3 down-convolution blocks, 3 up-convolution blocks, two extra convolution sets and a final convolutional layer with a size 1 kernel. The number of channels in the model is increasing as resolution decreases and decrese back during the up-convolution blocks.
UNet:
ConvDown(3, 32),
ConvDown(32, 64),
ConvDown(64, 128),
ConvUp(128, 256),
ConvUp(256, 128),
ConvUp(128, 64),
ConvBlock(64, 32),
nn.Conv2d(32, self.n_class, 1)
The final architecture of the model is as follow:
 (click to open)
(click to open)
We train the model for 30 epochs, with a learning rate of 3e-3 and a higher than normal weight decay of 1e-4. The training and validation loss during training is as follows:
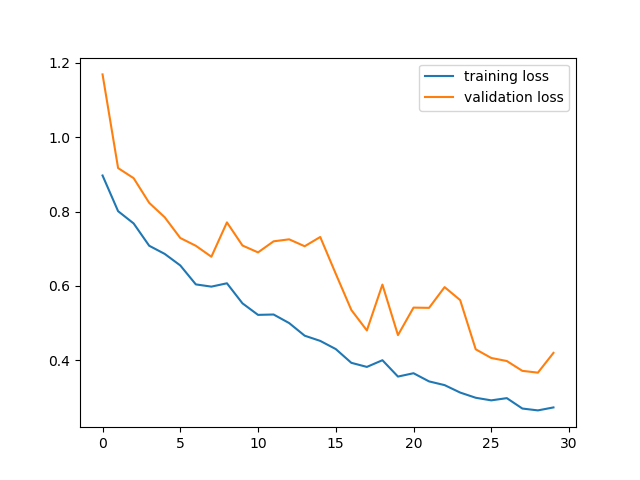
This model achieve an average percision of 0.672, and per-class AP is as follows:
| class | AP |
|---|---|
| others | 0.743 |
| facade | 0.806 |
| pillar | 0.272 |
| window | 0.870 |
| balcony | 0.670 |
As we can see the bottleneck of the model is detecting pillars. However, is a challenging since number of pillar instances in the dataset is rather small in comparison to other classes.
Here's some example result of the network from the test set and some of my images:
| input | output |
|---|---|
 |
 |
 |
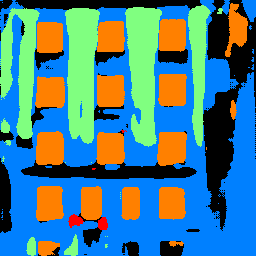 |
 |
 |
 |
 |
 |
 |
The model works pretty well when the input image is a clear, front-on image of a facade. Sometimes it will misclassify wall as pillar, and sometimes it will get confused about the shadows on the wall. The model fails to recoginize the sky in the third image and the plant in the fourth image, since these objects rarely exists in the training dataset. It also works less than idea when the image has an angle as shown in the last image. As we can see from these examples, the usage of the model is very restricted since we only trained it on a dataset that only consists of full building facades. If sky, roofs or other objects exists, the model will very likely to fail.