In this project, we train a couple Convolutional Neural Nets, one to perform image classification, and the second to perform the very interesting problem of image semantic segmentation. Image classification is the classic scenario of inputting an image and getting a prediction of what that image is as the output. Semantic segmentation, on the other hand, acknolwedges that the world is far too complex to always get images that feature one subject, and therefore seeks to identify multiple types of objects within one image. I enjoyed gaining exposure the latter, and seeing the side-by-side comparison of the actual per-pixel labels with the net's predictions really emphasizes how neural nets don't possess any of implicit understandings humans have of the world.
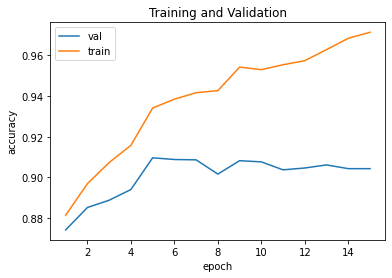
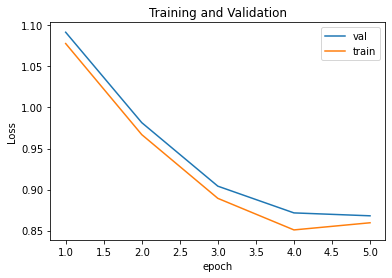
I use a CNN with two convolution layers, each followed with ReLU and max pooling over a 2 by 2 window, followed by two fully connected layers. I used a crude implementation of random searching to find sufficient values for various configuration variables for my networking. These variables include: learning rate, number of epochs, number of channels, and size of the "hidden" fully connected layer.
The final network was trained using the following values:
|
Variable |
Value |
|
Learning Rate |
0.001 |
|
Epochs |
15 |
|
Channels |
57 |
|
FC Size |
69 |
|
|
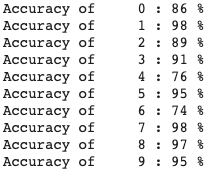
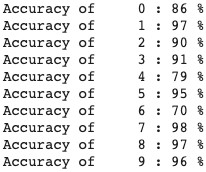
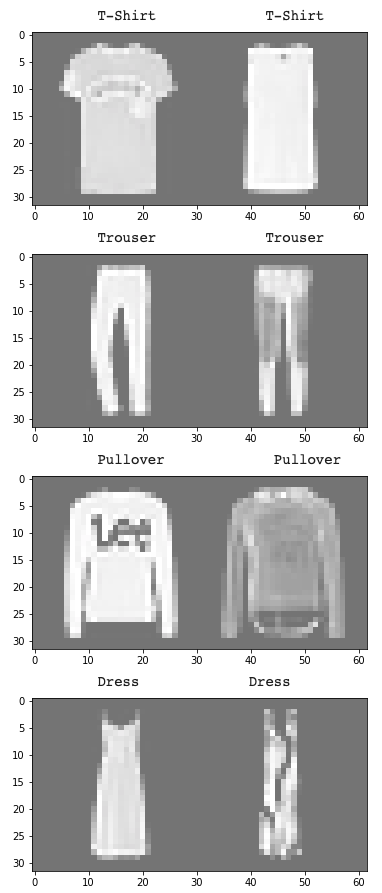
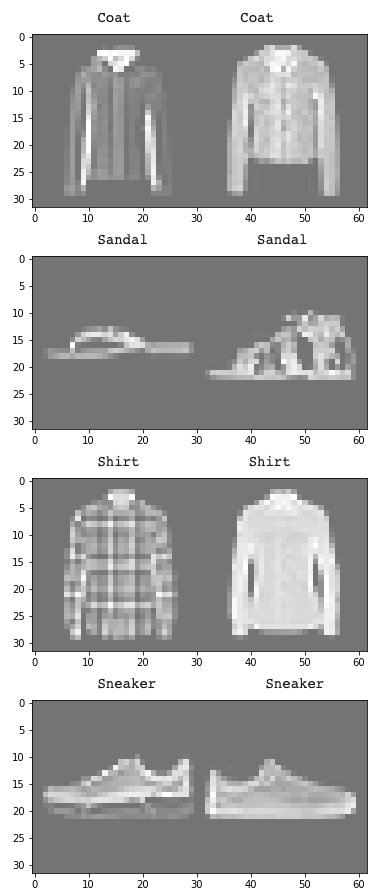
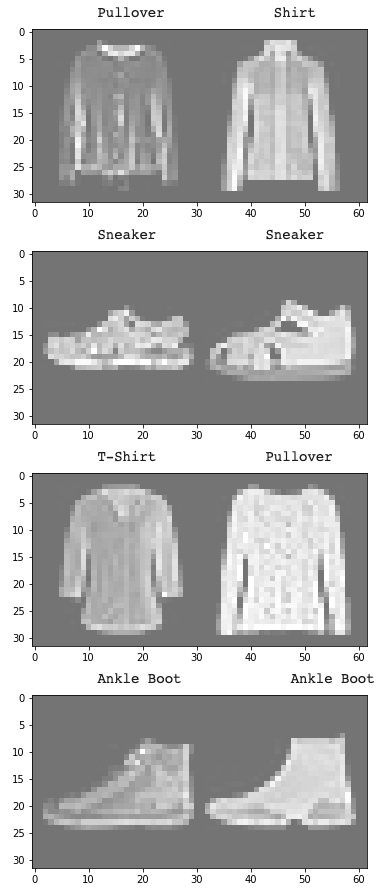
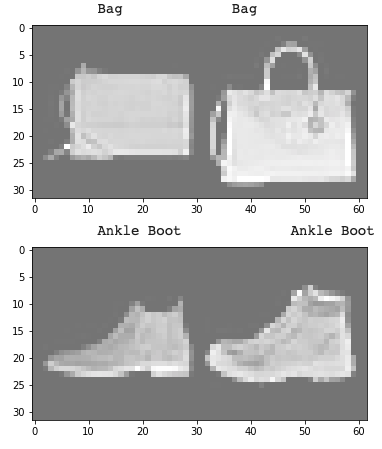
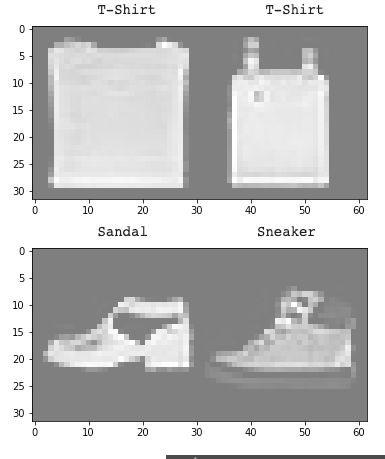
The class that the model very evidentally struggled on was class 6, or shirts. I think that this can partially be explained because a lot of shirts appear very close to pullovers/t-shirts/coats (see below).
Left are correctly labeled examples; right are incorrectly labeled examples whose predicted labels are given
 |
 |
 |
 |
 |
 |

Before doing random sampling for hyperparameters, I looked into some of the literature regarding semantic segmentation. I found this paper on Fully Convolutional Networks. In their findings, they note that using a fully convolutional architecture (ie. no dense layers) that emulates the structure of the well-known VGG-16 CNN architecture, except with transposed convolution at the end for upsampling, performed the best. Therefore, I adapted these findings to our dataset.
The model architecture is composed of five convolutions as per spec, with ReLU after each. After every two convolutions (after one for the final one), there is a maxpool layer. Finally, there is a transposed convolution that effectively does upsampling. The channel sizes for the convolution layers are 32, 64, 128, 256, and 512. All convolution filters are 3 by 3 and each feature map is padded by 1. The maxpool kernel size is 2 and the stride is also 2, so as to halve the dimensions. Finally, the transposed convolution has a kernel size of 8 and a stride of 8, as well as 5 channels, to result in a 256 by 256 by 5 image.
I decided to maxpool only after two convolutions to avoid reducing the image size too much, and I made the final transposed convolution kernel size 8 to give some form of granularity over the 32 by 32 by 512 feature map it convolves over (not sure if this is the right intuition, but the results are good).


|

|
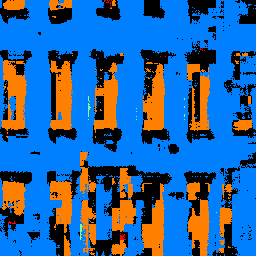
|
This example is interesting because it has examples of pillars, which is class 2 (AP = 0.18). The color map of pillars is green, and it's clearly visible that nearly none of the actual pillars are labeled properly, and some of the wall is labeled a pillar. However, the model is quite accurate with the facade of the building (blue), and relatively also the window (orange). I think this might be true because the designs of these might not vary as much in the training data.
I didn't have any pictures on hand and given the current covid-19 situation I didn't want to go out and take one, so I used a cropped picture of the white house.

|
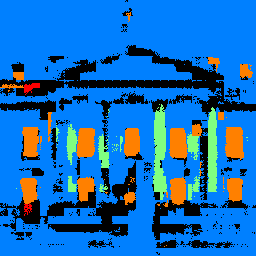
|
The model gets the windows rather correctly, but also has some false positives. Given the White House's prominant and classically designed pillars, it also detects the pillars better than expected. However, it heavily struggles with facade in the mount of false positives it gives, namely the entire sky and lawn. This might be because the sky is rather similar in color to the white house, and a lawn might not appear much in the training data.