Project 4 - Classification and Segmentation
Part 1: Image Classification
Part 2: Semantic Segmentation
CNN Architecture & Training Details
The CNN architecture has six convolution layers, having 1 * 48, 2 * 48, 4 * 48, 8 * 48, 8 * 48, 5 channels respectively and each followed by the ReLU activation except at the very end. The padding size is 1 and kernel size is 3 * 3. For the training, I use the cross-entropy loss and Adam optimizer with a learning rate of 1e-3 and weight decay 1e-5. The network is trained for 50 epochs, and 20% of training data is used as validation set.
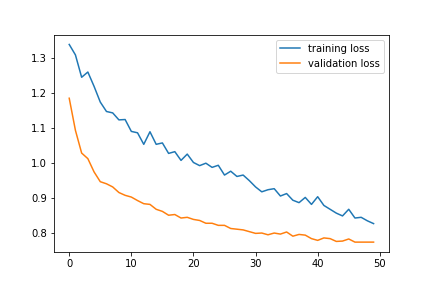
Loss Curve
Below is the training loss and validation loss curve against the number of epochs during training for 50 epochs. Note that as training progresses, the network slowly overfits as the validation loss no longer decreases.
Average Precision
I achieve an average precision (AP) of 0.533 on the test set, with precision of 0.657, 0.751, 0.100, 0.781, 0.375 on each class. The pillar channel and balcony channel have relatively low precision.
Example
Below is an example from the test set.
CNN Architecture & Training Details
The CNN architecture has two convolution layers having 32 channels and kernel size of 5 respectively and each followed by the ReLU activation and a maxpool layer of size 2. At the very end we have two fully-connected layers of size 120 and 10 respectively. For the training, I use the cross-entropy loss and Adam optimizer with a learning rate of 0.001. The network is trained for 30 epochs, and 20% of training data is used as validation set.
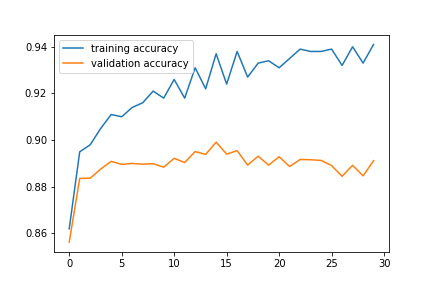
Accuracy Curve
Below is the training accuracy and validation accuracy curve against the number of epochs during training for 30 epochs. Note that as training progresses, the network slowly overfits as the validation accuracy no longer increases.
Analysis of Different Classes
Below is the per class accuracy of the classifier on the validation and test set. Shirt class is the hardest to get, probably because it can be mixed up with T-shirt, Pullover or Coat, which also has relatively low accuracy.
Here is the image of Blackwell Hall and the trained network's segmentation result from it. From the segmentation, we can see that this network performs well on window prediction, which is the orange area. However, it does not predict well on pillar(green) and balcony(red) in the image, mainly due to the difference style between Blackwell Hall and the training sets.

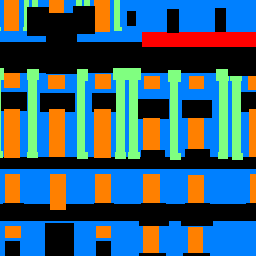

Image
Label
Segmentation


Image
Segmentation

Class Name
Validation Acc (%)

Test Acc (%)
T-Shirt
84
85
Trouser
97
96
Pullover
77
79
Dress
88
87
Coat
88
88
Sandal
97
97
Shirt
67
65
Sneaker
95
95
Bag
97
96

Ankle Boot
96

95
Below in the left two columns are correctly classified images from each class, in the right two columns are misclassified images from each class, the incorrect prediction is written above the image.

Class Name

T-Shirt

Trouser

Pullover

Dress

Coat

Sandal

Shirt

Sneaker
Bag
Ankle Boot

Correctly Classified
Misclassified
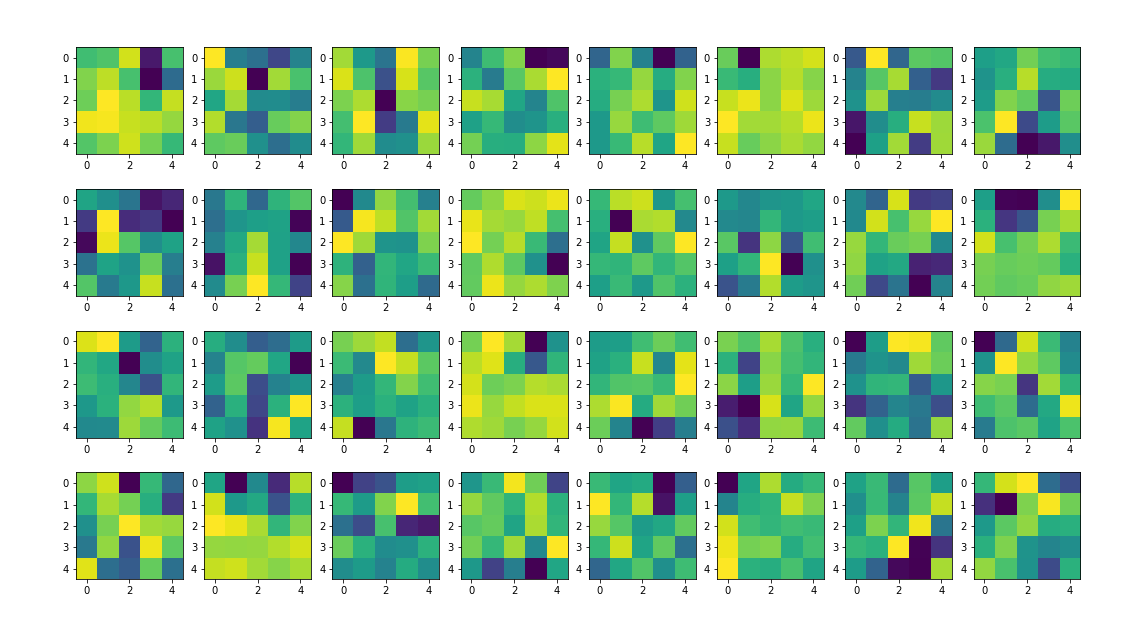
Visualization of Learned Filters
Below are the learned filters by the first convolution layer. Some of the filters corresponds to some structure of images in the training set.