Classification and Segmentation
Overview
In this project, we use convolutional neural nets to classify the Fashion-MNIST dataset and segment the Mini Facade Dataset.
Part 1: Image Classification
Network
My final network included:
- Conv2d(in_channels=1, out_channels=55, kernel_size=(5, 5))
- ReLU
- MaxPool2d(kernel_size=2, stride=2)
- Conv2d(in_channels=55, out_channels=48, kernel_size=(3, 3))
- ReLU
- MaxPool2d(kernel_size=2, stride=2)
- Linear(1200, 124)
- ReLU
- Linear(124, 10)
I also used Cross Entropy Loss and the Adam optimizer with a 0.001 learning rate, and I trained the network for 10 epochs. Here are a few sample images from the dataset:

Here's the classifier's performance while training. I've included both the overall performance and the performance by classes:
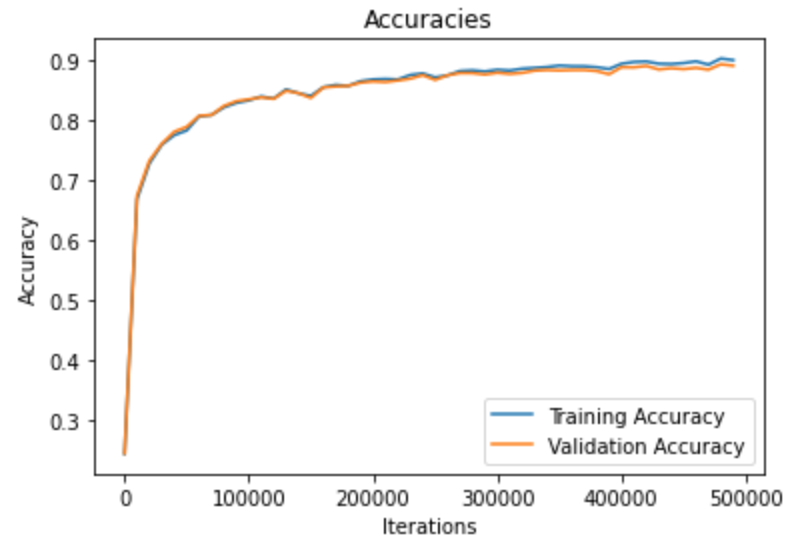
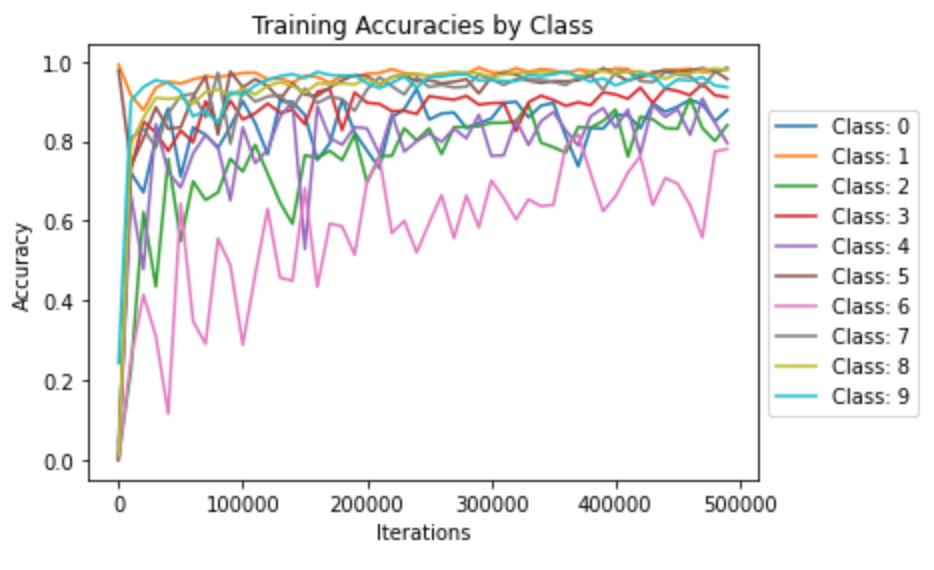
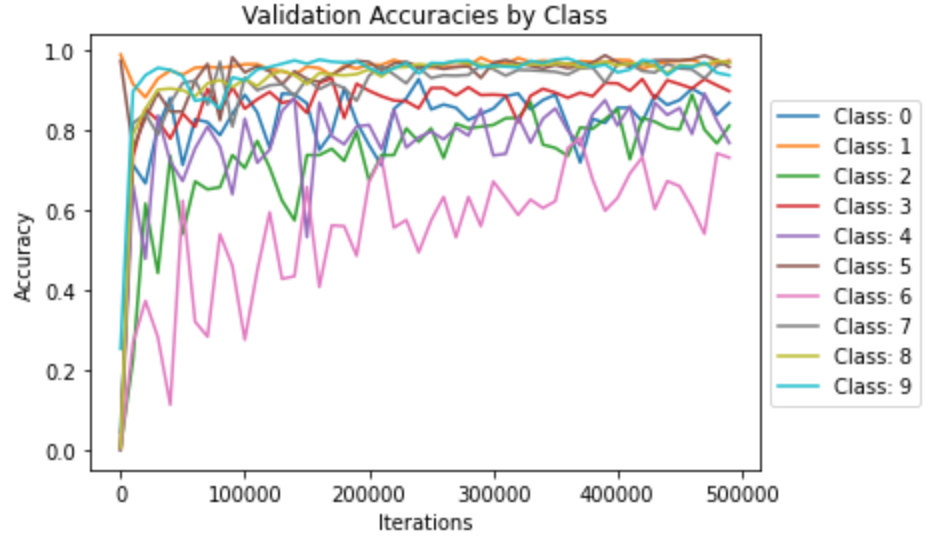
Where each class id corresponds to the following clothes and has the following final accuracies.:
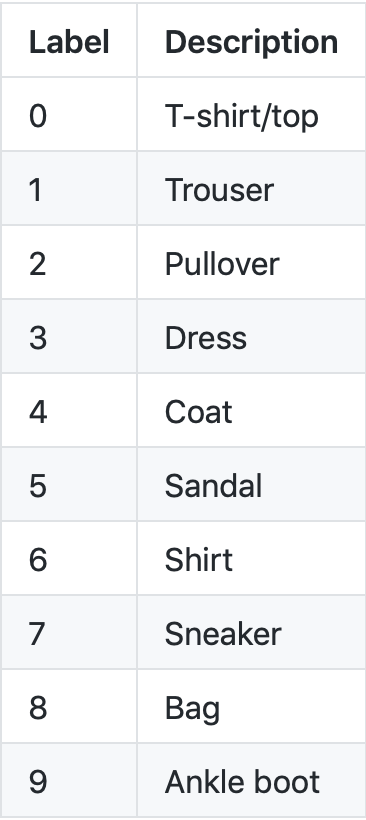
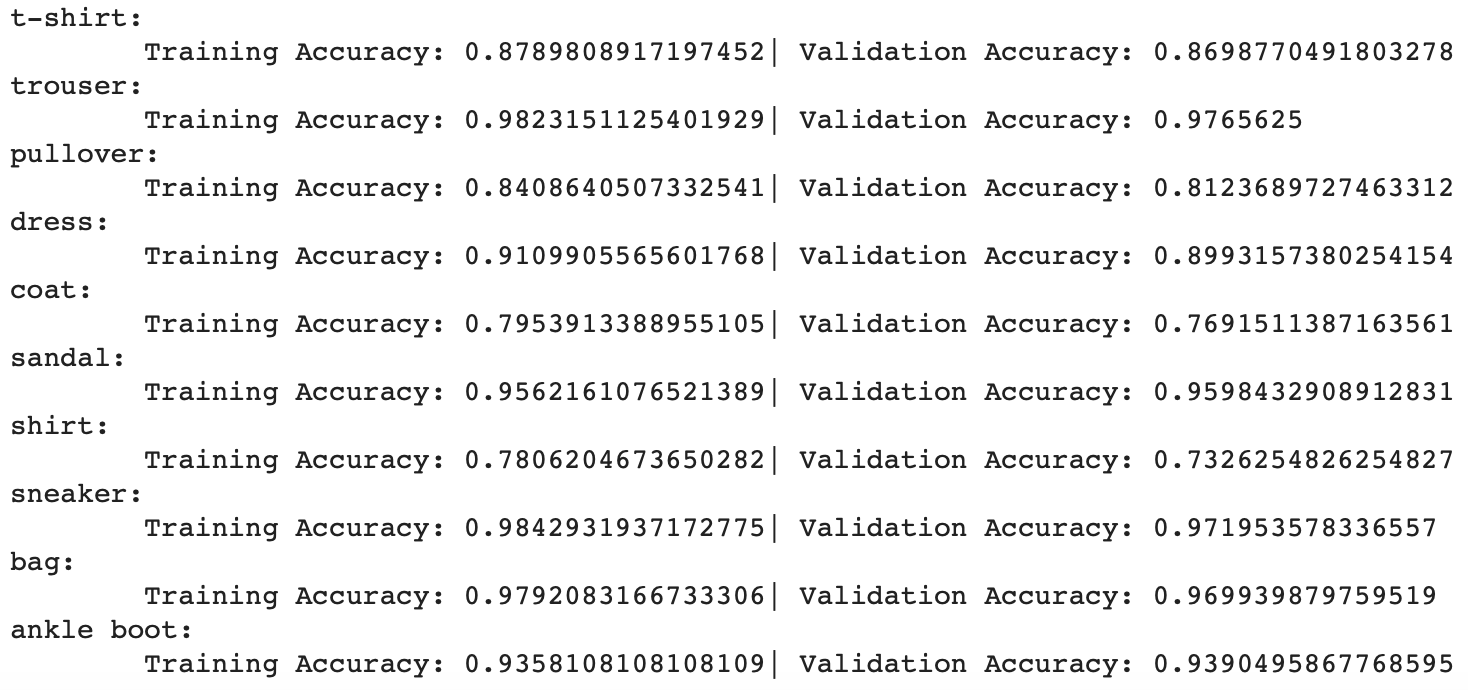
The classifier is especially good at classifying trousers and sneakers, but struggles to classify shirts and coats. Here are a few examples of correct and incorrect classifications. The two left images on each row were classified correctly. The two on the right were classified incorrectly.










We can also visualize the filters used in both convolutional layers to get a sense of what features the net is looking for:
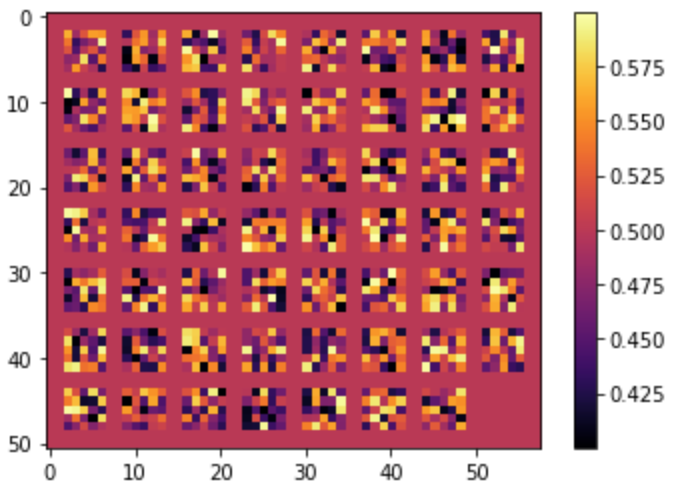
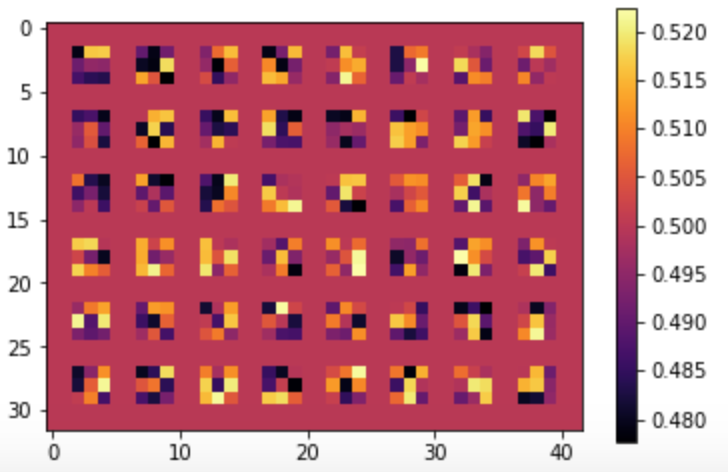
Part 2: Semantic Segmentation
Network
My final network included:
- Conv2d(3, 64, 1, padding=0)
- ReLU
- Conv2d(64, 256, 5, padding=2)
- ReLU
- MaxPool2d(kernel_size=2, stride=2)
- Conv2d(256, 128, 3, padding=1)
- ReLU
- MaxPool2d(kernel_size=2, stride=2)
- Conv2d(128, 96, 3, padding=1)
- ReLU
- Upsample(scale_factor=2.0, mode='bilinear')
- Conv2d(96, 64, 3, padding=1)
- ReLU
- Upsample(scale_factor=2.0, mode='bilinear')
- Conv2d(64, 5, 1, padding=0)
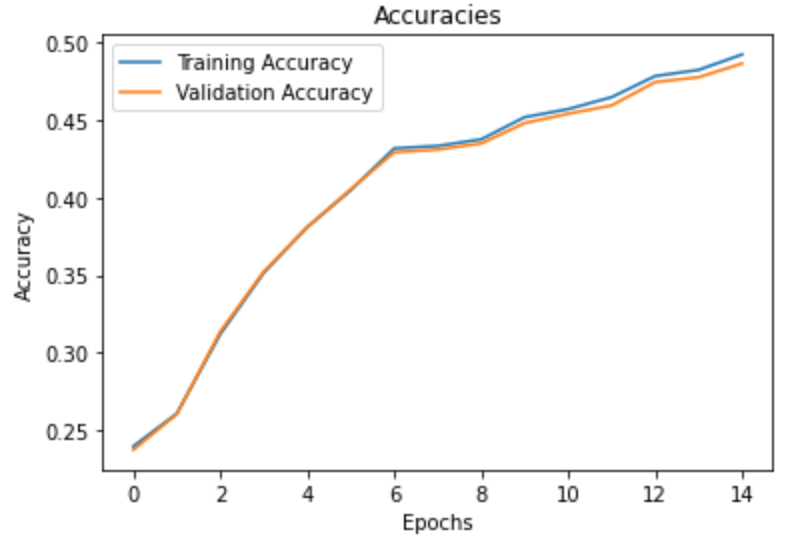
I again used Cross Entropy Loss and the Adam optimizer with a 1e-3 learning rate and 1e-5 weight decay. I trained the network for 15 epochs and acheived a 0.497 Average Precision on the test set.
I then ran the network on an image from the Internet (https://www.123rf.com/photo_17985244_beautiful-old-facade-at-a-historic-building.html). Here's the original and the network output for comparison:

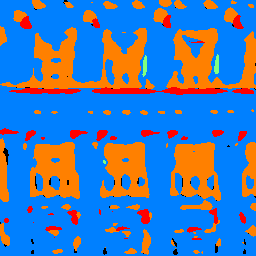
My classifier did a decent job generally locating the windows but a poor job filling them in completely. It also seems to recogize some of the lining below the top row of windows but classifies it as a "balcony" rather than "other." It does a poor job locating pillars as well. It entirely misses the pillars in the bottom row; however, it does make out some of the pillars in the top row. Unfortunately, it doesn't fill them out completely on the segmentation. Considering the entire image contains a facade, the classifer does a good job of labelling most of the image with blue.