Part 1: Image Classification
Dataset
I built a CNN to classify images of fashion items. I built the network using PyTorch and used Fashion MNIST as the dataset. Fashion MNIST has 10 classes and 60000 train + validation images and 10000 test images. Here are some images from the dataset:

|
Implementation Details
The network has two convolutional layers with 40 channels and a 3x3 kernel each. Each convolutional layer is followed by a ReLU followed by a max pool with a 2x2 kernel and stride of 2. There are then 2 fully connected layers with output size 120 and 10 respectively. The first fc layer is followed by a ReLU, but not the second. I used cross entropy loss as the prediction loss and Adam as the optimizer with a learning rate of 1e-3 and a weight decay of 1e-5.
Network: input -> conv -> relu -> pool -> conv -> relu -> pool -> fc1 -> relu -> fc2 -> outputs
Optimizer: Adam (lr=1e-3, weight_decay=1e-5)
I tried different activiation functions (sigmoid, elu), number of channels (16, 32, 64), and convolution kernel sizes (5x5), as well as some other learning rates (1e-2, 1e-4), optimizers (SGD), and weight decays (0, 1e-4, 1e-6), and got the best results with the structure detailed above.
Results
The network is trained on 80% of the entire training set, and the rest is used for validation. I calculated accuracies after 100, 200, 500, 1000, 2000, 5000, 12000, 24000, and 48000 training samples.
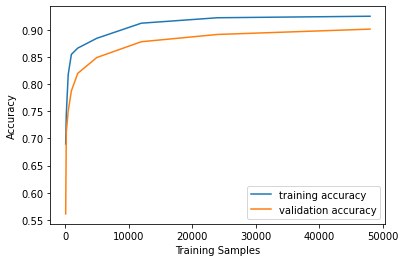
|
|
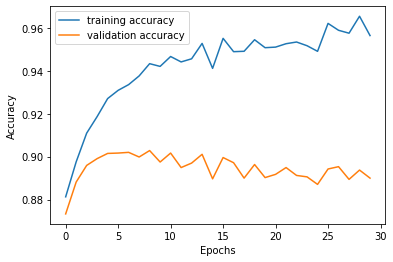
I trained the network for 30 epochs. After about 5 epochs, the validation accuracy starts to decline as the model is overfitting the training data.
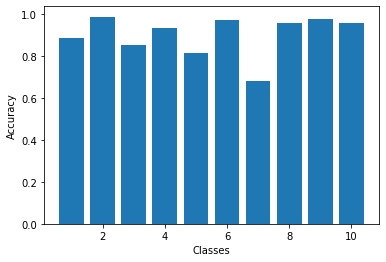
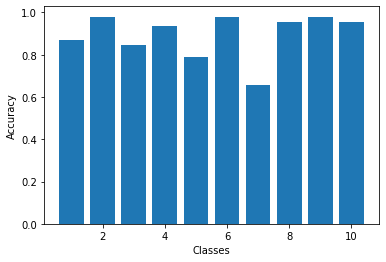
Here are the per class accuracies of the network for both validation and test sets. The hardest classes to classify are shirt and coat.
| Class | Class Name | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| 0 | T-shirt/top | 88.3% | 86.8% |
| 1 | Trouser | 98.6% | 98.0% |
| 2 | Pullover | 85.2% | 84.4% |
| 3 | Dress | 93.3% | 93.5% |
| 4 | Coat | 81.6% | 79.1% |
| 5 | Sandal | 97.3% | 97.8% |
| 6 | Shirt | 68.2% | 65.9% |
| 7 | Sneaker | 95.9% | 95.6% |
| 8 | Bag | 97.5% | 98.0% |
| 9 | Ankle boot | 95.8% | 95.7% |
|
|
Here is a table showing some images that were classified correctly and some that weren't. The first column is the actual class name of the images in the middle, and the last column are the classes predicted by the model of the two incorrectly classified images.
| Class Name | Classified Correctly | Classified Incorrectly | Predicted Class Name | ||
|---|---|---|---|---|---|
| T-shirt/top |

|

|

|

|
Dress, Shirt |
| Trouser |

|

|

|

|
Dress, Dress |
| Pullover |

|

|

|

|
Shirt, Shirt |
| Dress |

|

|

|

|
Shirt, Shirt |
| Coat |

|

|

|

|
Shirt, Pullover |
| Sandal |

|

|

|

|
Ankle boot, Sneaker |
| Shirt |

|

|

|

|
T-shirt/top, Coat |
| Sneaker |

|

|

|

|
Ankle boot, Ankle boot |
| Bag |

|

|

|

|
Sandal, Sandal |
| Ankle boot |

|

|

|

|
Sandal, Sneaker |
The first convolution layer has forty 3x3 filters. The learned filters are displayed below.

|
Part 2: Semantic Segmentation
Dataset
In this part we use a CNN to do image segmentation. We use the Mini Facade dataset to label structural elements in building facades. The Mini Facade dataset consists of images of different cities around the world and diverse architectural styles (in .jpg format). It also contains semantic segmentation labels (in .png format) in 5 different classes: balcony, window, pillar, facade and others.


Implementation Details
The network has four convolutional layers each with 32 channels, a 3x3 kernel, and padding=1 on all sides of the image. Each convolutional layer is followed by a ReLU and then a max pool with a 2x2 kernel and a stride of 2. Each max pool halves the resolution, so we upsample with four transposed convolutions each with 32 channels, a 3x3 kernel, padding=1, and a stride of 2 to double the size of the input. The network has a final convolutional layer with 5 channels, a 3x3 kernel, and padding=1. This layer is not followed by ReLU or max pool.
I used cross entropy loss as the prediction loss and Adam as the optimizer with a learning rate of 1e-3 and a weight decay of 1e-5.
Network: input -> [conv -> relu -> pool] (4 times) -> upsample (4 times) -> conv -> outputs
Optimizer: Adam (lr=1e-3, weight_decay=1e-5)
I tried different hyperparameters (eg. learning rate, weight decay), optimizers, and network architectures, and got the best efficiency and results with these settings.
Results
The network was trained on 80% of the training data and the rest was used for validation. It trained for 50 epochs, and the loss per epoch is displayed below.

|
We also use Average Precision (AP) on the test set to evaluate the learned model. The per class AP and overall AP are shown below.
| Class | Class Name | Average Precision |
|---|---|---|
| 0 | others | 0.640 |
| 1 | facade | 0.752 |
| 2 | pillar | 0.114 |
| 3 | window | 0.808 |
| 4 | balcony | 0.526 |
| Overall Average Precision | 0.568 | |
Here is an image I took of Radcliffe Camera in Oxford, padded with black to make it 256x256. On the right is the output of Camera segemented by the model. Notice that some classes like window are segemented well, while others like balcony and pillars aren't. I think this may be because the image of the facade of the building is relatively small compared to the ones in the training set, so it's harder for the model to distinctly recognize the more detailed building features.

|

|