Part 1
This part of the project is a classic image classification problem. The goal is to take an image from the MNIST fasion database and classify it as one of the following categories: T-shirt/top, Trouser/pants, Pullover shirt, Dress, Coat, Sandal, Shirt, Sneaker, Bag, Ankle boot. This is a well known dataset and is pretty easy to work with. All images are 28x28 in dimensions and gray scale.

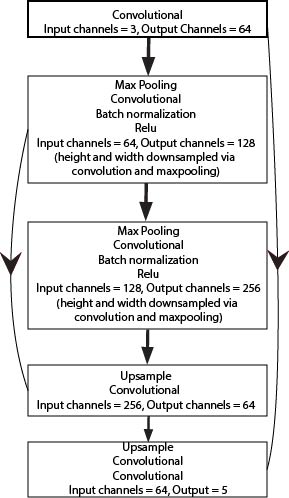
My network was a simple convolution network build in pytorch. It's pretty small and light weight for a convolution network but because the images are so small, the net doesn't really need an extremely high level of complexity to capture and approximate the data. The architecture was:
- Conv2d(1, 16, kernel_size = 5 , padding = 2)
- BatchNorm2d(16)
- ReLu
- MaxPool2d(2)
- Conv2d(16, 32, kernel_size = 5, padding=2)
- BatchNorm2d(32)
- ReLu
- MaxPool2d(2)
- Linear(7*7*32, 10)
This is a pretty standard set up for this kind of problem. It's effectively 2 convolution blocks with some extra functionality (normalization, activation and downscaling) followed by a fully connected layer which moves from the altered dimensions of the net to the number of classes we want to classify.
After this I built some dataloaders and compiled the model. I used (categorical) cross entropy loss and the Adam optimizer with a learning rate of 0.01. I still think this is a little too high but I guess for a lightweight net it works fine. Using batch size of 128 and training for 10 epochs. After writing a mess of a training loop we get the following loss and accuracy graphs.
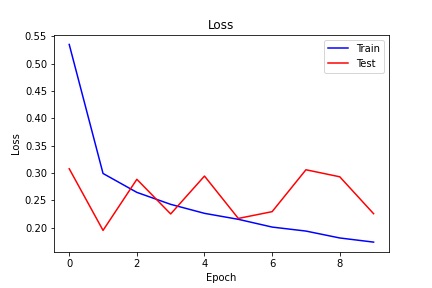
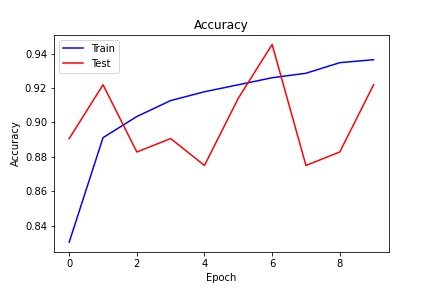
The training cure on both graphs is super pretty, but the validation curve is a bit jumpy. This could be random, I think the batch size for the test data was smaller, but it could also be the result of the high learning rate. Ether way, if I trained this for longer I'm sure it would flatten out a but but I'm training on a macbook without a GPU and i just don't have that much time.
Class Accuracies
We can find out more about how our network functions by looking at things it got wrong vs things it correctly classified. Sometimes the errors the network makes are understandable. Often time it all looks like nonsense to a human because networks tend to prioritize texture over other features but in some cases, such as this one, the mistakes are similar to that which a human would make, and we can empathize somewhat. The first thing I did was figure out the class by class accuracies of the test set.
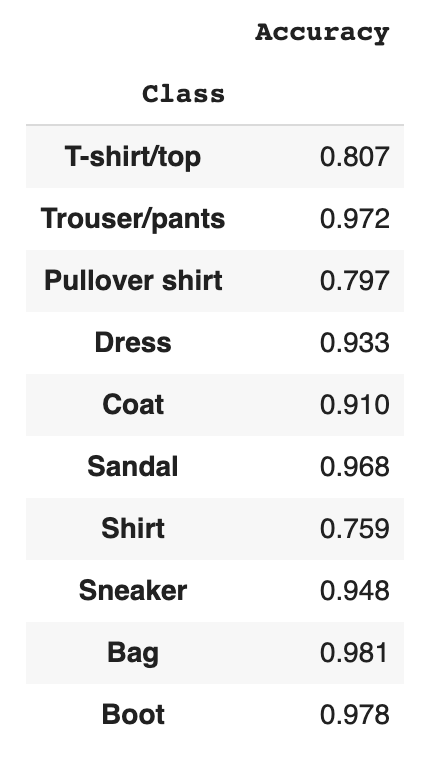
As you can see, the network had a pretty hard time classifying the t-shirts but almost never misclassified a bag. The next thing we can do is to build a confusion matrix which shows not only what was correct or incorrect but also in what way. This tells us, if something was misclassified, what our network thought it was.
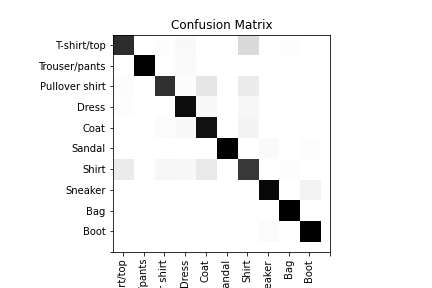
This actually tells us a lot about the mistakes the network made. Obviously, it got most of the images correct, but when it made errors we can see that it was usually something that looks similar. We see that t-shirts are often misclassified, and when they are our network usually thinks they are normal shirts or coats, which makes a lot of sense.


For low resolution images, you can kind of squint and see what it's thinking. They have similar colors and the same general shape. For some t-shirts, and shirts, they may be even more similar. Contrast this with a pair that the network never got wrong.


The bags are a unique shape and don't really look like anything else in the dataset. The network rarely makes mistakes classifying bags and boots.
Visualizing layer activations
In some networks, we can see exactly what the network is thinking by using gradient ascent (opposite of the normal optimization function) to create saliently maps. Saliently maps show exactly what causes the network to activate at a specific node. This technique can be very valuable when trying to understand or troubleshoot convolutional networks. At their best (and with a guided back propagation), they can look almost exactly like the images you would expect.


At the first few layers of the network, they tend to just look like simple edges and circles and stuff like that, but in the deeper layers, they are clearly human recognizable.
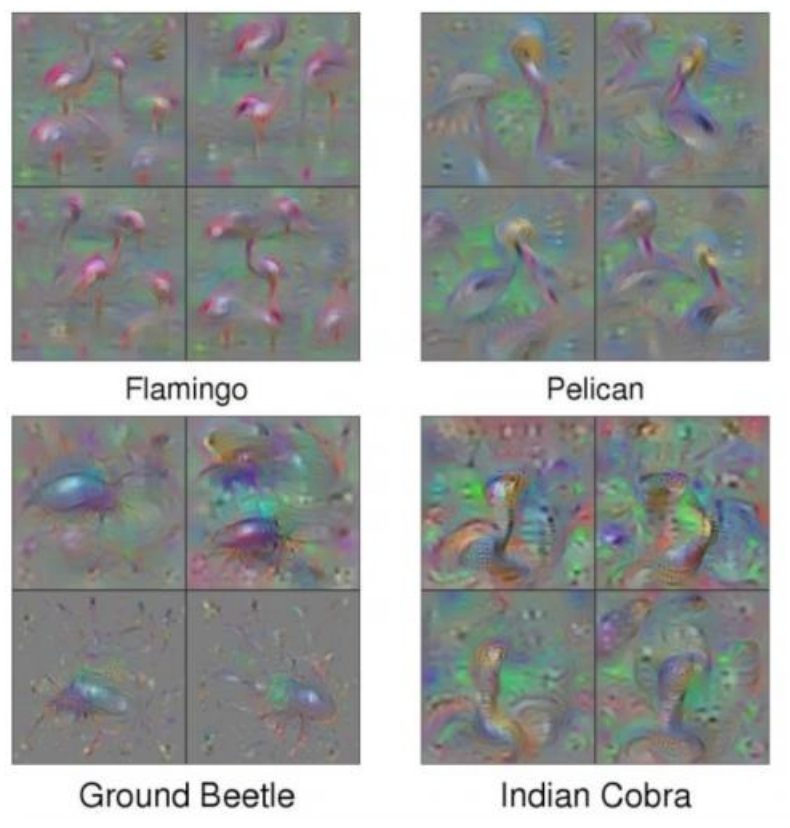
Unfortunately, mine do not look like that. There are several reasons for this. One is that the images are low resolution, good for fast training, bad for visualization. Secondly, my network is pretty shallow. With only 2 real convolutional layer, the network doesn't really learn complex shapes well. Finally, I used a large step size and some max pooling. This causes some harsh down sampling which means that my filters are only 5x5 in the final layer. But what can ya do?

If you REALLY squint you can maybe sort of see how those might look something like the fasion dataset...?