Part 1: Image Classification
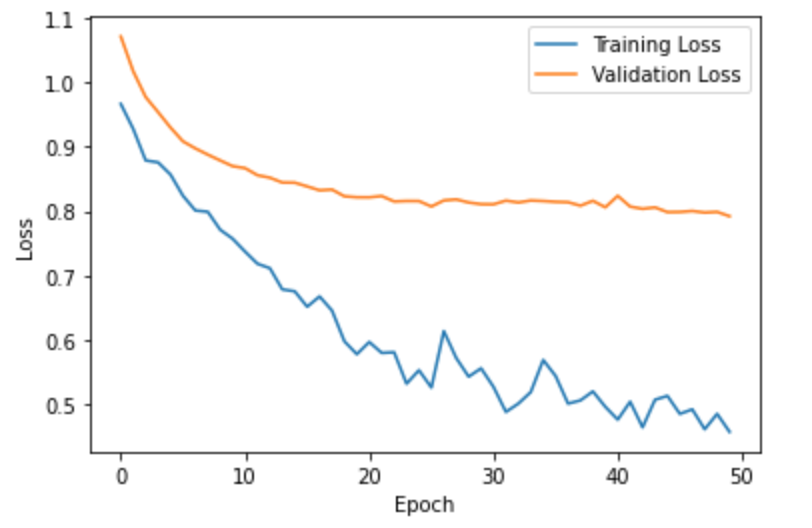
In this part, we had to set up a Convolutional Neural Network to model a classifier on the Fashion MNIST datset. We had 60,000 images to train on and 10,000 to test on. For hyperparameter tuning, I split up the training set into 48,000 (80%) for training and 12,000 (20%) for validation. The batch size was 50. It was a nice and gentle introduction to setting up and tuning light neural networks. Here are some examples of an image for each class:
| Category | Image |
|---|---|
| T-shirt |

|
| Trouser |

|
| Pullover |

|
| Dress |

|
| Coat |
|
| Sandal |

|
| Shirt |

|
| Sneaker |

|
| Bag |

|
| Boot |
|
1.1 Model Architecture and Results
Since this was just a simple classification task on low resolution images, we didn't need a very deep or fancy network. The network architecture was:
1. Convolution (32 channels, 3x3 kernel, padding=1) → ReLU → MaxPool (2x2 kernel, stride=2)
2. Convolution (32 channels, 3x3 kernel, padding=1) → ReLU → MaxPool (2x2 kernel, stride=2)
3. Fully Connected Layer (120 nodes) → ReLU
4. Fully Connected Layer (10 nodes)
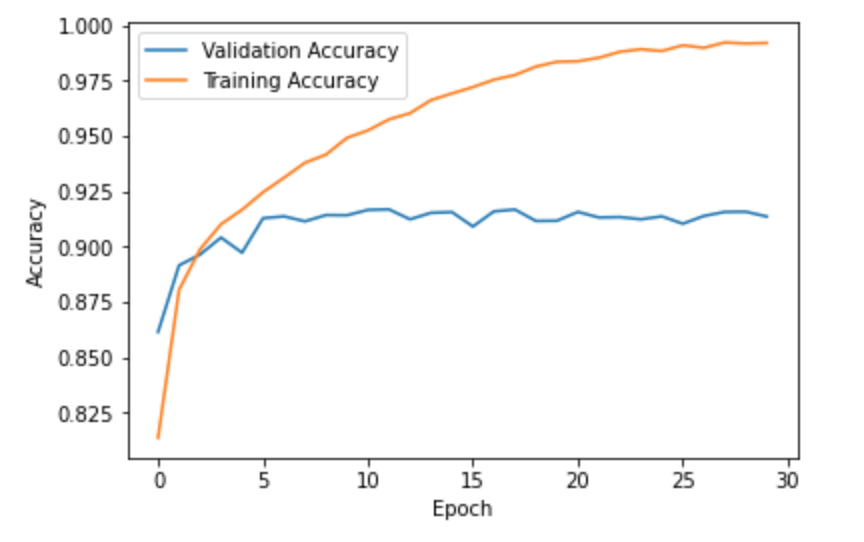
1.2 Qualitative Results
To get a better idea of how good our model is, let's look at the per-class classification accuracy:
| Class | Validation Accuracy | Test Accuracy |
|---|---|---|
| T-shirt/top | 0.881 | 0.891 |
| Trouser | 0.986 | 0.985 |
| Pullover | 0.870 | 0.881 |
| Dress | 0.902 | 0.890 |
| Coat | 0.853 | 0.854 |
| Sandal | 0.976 | 0.969 |
| Shirt | 0.757 | 0.742 |
| Sneaker | 0.972 | 0.982 |
| Bag | 0.984 | 0.981 |
| Ankle boot | 0.950 | 0.948 |
Overall, the model classified them pretty well though it's worth noting that it had trouble with the "Shirt" class. I would think this is due to the fact that it is quite a general category and therefore is susceptible to false positives (such as t-shirts or pullovers being classified as shirts). Below you can see examples of incorrectly and correctly classified images for each class.
| Correct Classification | Correctly Classified | Incorrectly Classified | Incorrect Classification | Incorrectly Classified | Incorrect Classification |
|---|---|---|---|---|---|
| T-shirt/top |


|

|
Bag |

|
Shirt |
| Trouser |

|

|
Dress |
|
Pullover |
| Pullover |


|

|
Coat |

|
Dress |
| Dress |


|

|
Bag |

|
Shirt |
| Coat |


|

|
Dress |

|
Shirt |
| Sandal |


|

|
Ankle boot |

|
Sneaker |
| Shirt |


|

|
Pullover |

|
T-shirt/top |
| Sneaker |


|

|
Ankle boot |

|
Sandal |
| Bag |

|

|
Dress |

|
T-shirt/top |
| Ankle boot |


|

|
Sneaker |

|
Sneaker |
1.3 Visualizing the Learned Filters
Sometimes, it is informative to look at the learned filters. At lower levels of a convolutional network, the filters usually correspond to high level features, whereas later levels filter out low-level details. Since our first layer has 32 channels, we have 32 filters that we can look at.