In this project, we built Convolutional Neural Networks (CNNs) for image processing: classification and segmentation. For the classification task, we classified articles of clothing in the Fashion-MNIST dataset. For the segmentation task, we semantically segmented images of mini Facade dataset using Deep Nets. For the implementation, I used PyTorch and ran my code on Google Colab.
The CNN consisted of two convolutional layers, with 32 channels each, and a kernel size of 3. Following each convolutional layer by a RELU and maxpooling layer of size 2 and stride 2. The CNN ends with two fully connected linear layers, and an output layer. The CNN used cross-entropy loss and training with Adam at a rate of 0.01.
The batch size was set to 100, and epoch number set to 5.
|
The CNN performed the worst on classifying shirts, with an accuracy of 74.60% accuracy on the train dataset, and only 69.50% accuracy on the validation dataset. Trouser classification, on the other hand, did quite well with the CNN, achieving 98.73% on the train dataset, and 97.90% on the validation dataset.
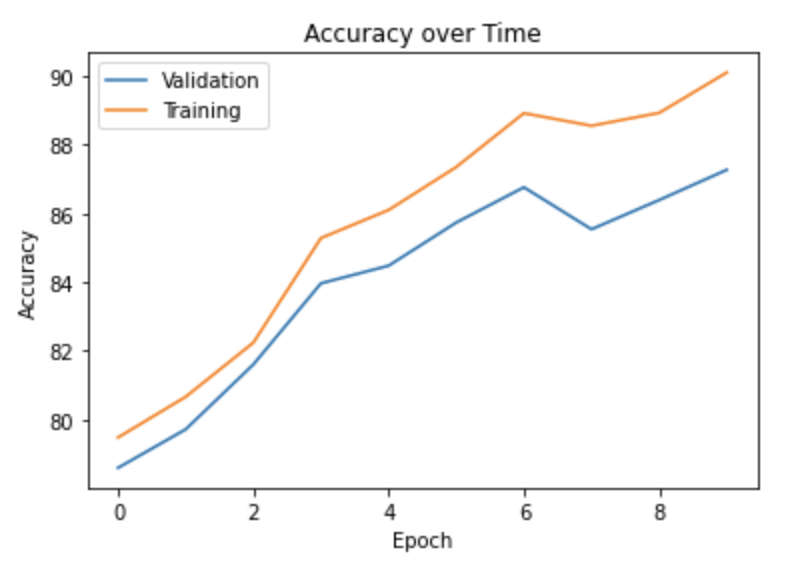
Below is a graph showing CNN accuracy over time, measured in epochs in this case, for the validation and training datasets:
Below are the 32 learned filters of the first convolutional layer of the CNN:




Below are the 32 learned filters of the second convolutional layer of the CNN:




The final CNN for the Fashion-MNIST dataset had an accuracy of 90%.
My architecture for the semantic segmentation portion of this project is as follows:

Pictured is the loss graph before training (on top), and after training (on bottom):
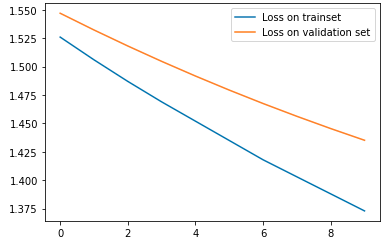
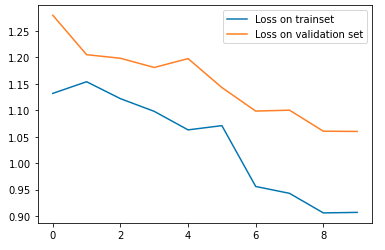
The average precision values, ranging from 0 to 1, are depicted below in order of by class: [others, facade, pillar, window, balcony]. The average precision after training was 0.3. This number could have been improved had I trained for longer, with more epochs.

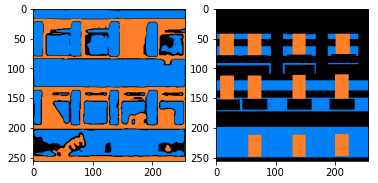
Below is a sample result for a random input image (as a result of shelter in place) of an office building: