
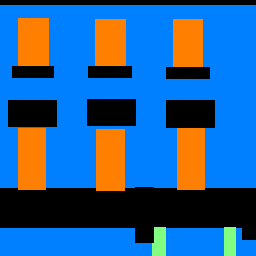
First, I trained an image classifier to classify 28x28 grayscale images of 10 different kinds of fashion products. Luckily, the Fashion-MNIST dataset provided by PyTorch has 70k labeled images available for use. For the architecture, I used a simple architecture of two 3x3 conv layers (each followed by a ReLU and a 2x2 maxpool) with two fully connected layers after. Each of the conv layers used 32 filters and the fc layers had 128 hidden units. This was trained using Adam with a learning rate of 1e-3 and no weight decay. Varying the number of channels/filters as well as the nonlinearities didn't seem to improve performance much, but I saw most of my improvements from adjusting the Adam learning rate. I found that the model would reasonably converge after 10 epochs.
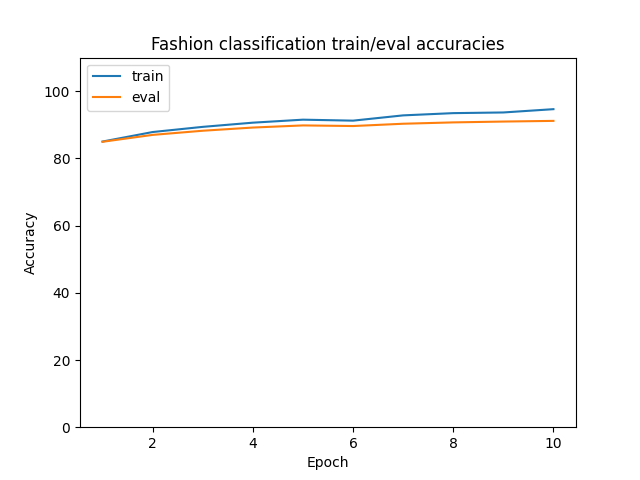
Per-class eval accuracies (in order from 0-9): [0.89, 0.99, 0.90, 0.95, 0.92, 0.99, 0.84, 0.97, 0.99, 0.97]
Per-class test accuracies (in order from 0-9): [0.82, 0.97, 0.85, 0.92, 0.88, 0.97, 0.73, 0.97, 0.99, 0.96]
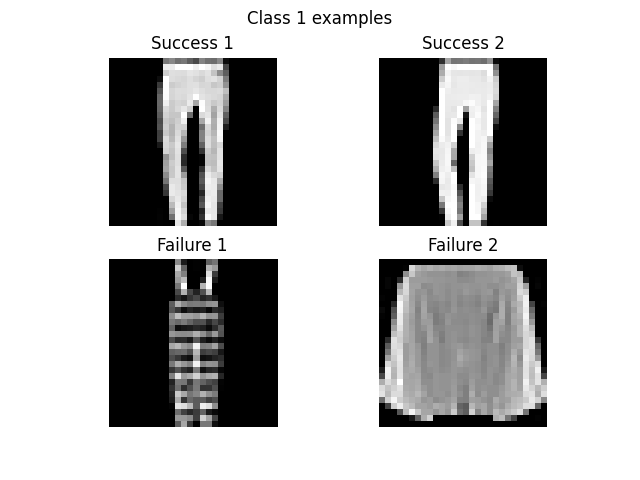
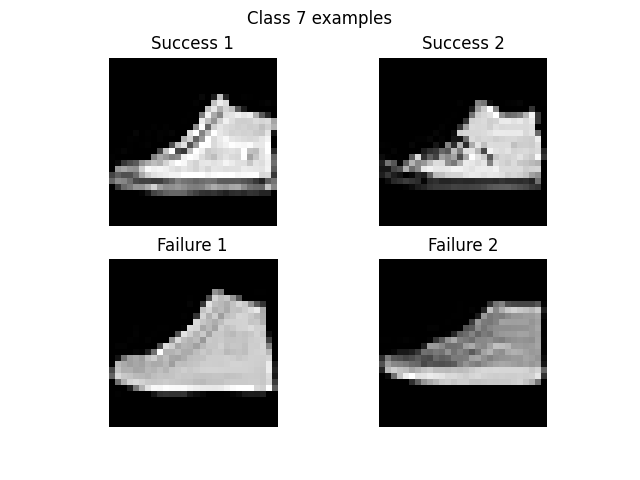
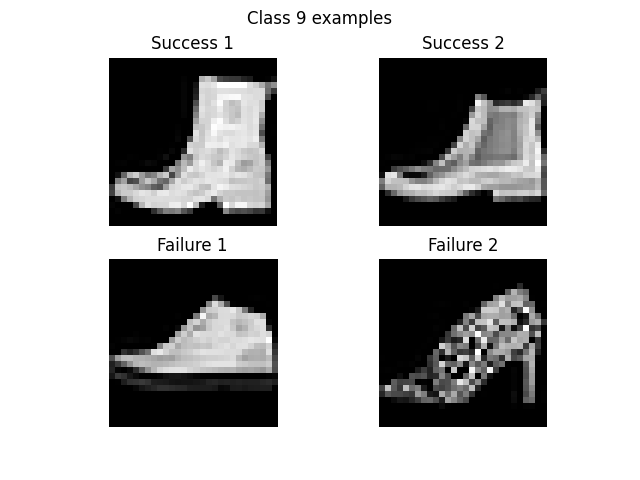
It appears that the classifier is not very good at classifying classes 0 (T-shirts), 2 (long sleeve shirts), and 6 (long sleeve shirts again?). Given that I myself am unclear what the difference between classes 2 and 6 is, I'm not surprised that the classifier is having a harder time, especially at such a low resolution. On the other hand, the classifier rarely misclassifies 1 (long pants), 5 (sneakers?), or 8 (I have no idea what these are, but they look very different from the other categories).







Here are all of the learned 3x3 filters/weights in the first conv layer of the learned network.
It can be hard to tell what some of these features are learning due to the low resolution, but we can see clearly that some of them are good edge detectors (top row, second from the right).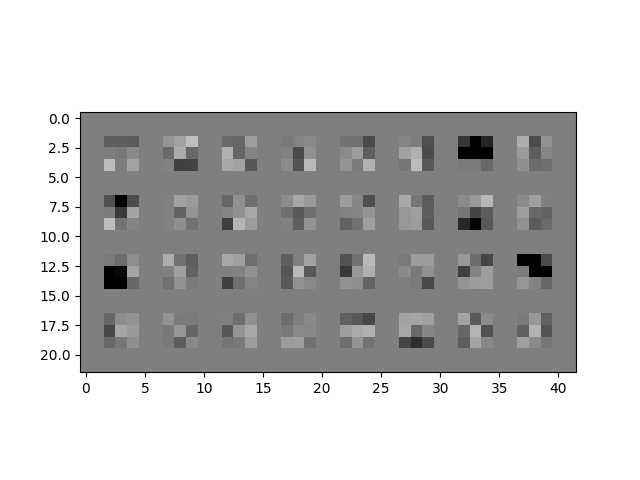
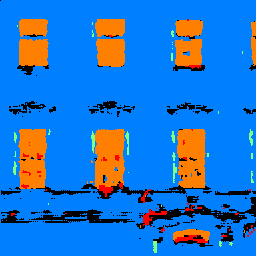
Next, I trained a segmentation network to infer labels for different parts of building images. I used the Mini Facade dataset, which tries to classify pixels as one of five different classes: balcony, window, pillar, facade, or other. For the network architecture, I decided to use only 3x3 conv layers (with ReLUs), 2x2 maxpools, and 2x2 upsampling layers (ConvTranspose2d) and added/removed conv layers as necessary to control under/over-fitting. The resulting architecture was two conv layers (with ReLUs), a 2x2 maxpool, a 2x2 ConvTranspose, two more conv layers, another 2x2 maxpool, another 2x2 ConvTranspose, and finally a conv layer with five output channels to generate five scores per pixel for each category. I used Adam with learning rate 1e-3 and weight decay 1e-5. I found that the model took about 25 epochs to converge, which makes sense given the smaller size of the dataset (800 training images only) compared to Fashion-MNIST.
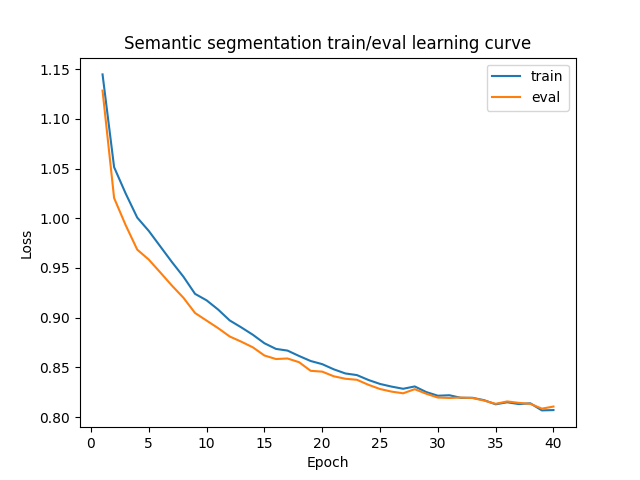
The model achieved reasonable results, but the outputs were still fairly noisy. Here are some examples from the test set.


Average precision was .54. Class-wise AP scores (classes from 0-5): .67, .75, .10, .77, .39.
The model seems to do a better job identifying windows and facades, but does an awful job with pillars and miscellaneous parts. The second example above shows a particularly spectacular failure, where the model is completely unable to handle the fire escape railing.