| T-shirt/top | 84% |
| Trouser/pants | 98% |
| Pullover shirt | 79% |
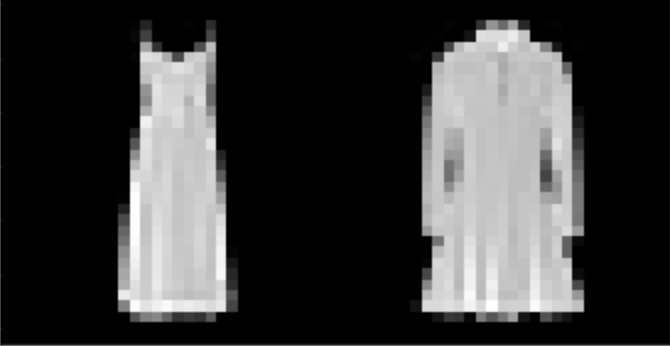
| Dress | 91% |
| Coat | 88% |
| Sandal | 97% |
| Shirt | 67% |
| Sneaker | 98% |
| Bag | 98% |
| Ankle boot | 94% |
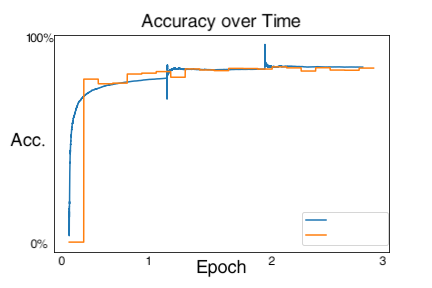
I found that shirts were the hardest to classify, while pants, sneakers, and bags were fairly easy. The following are correctly and incorrectly images for each class.


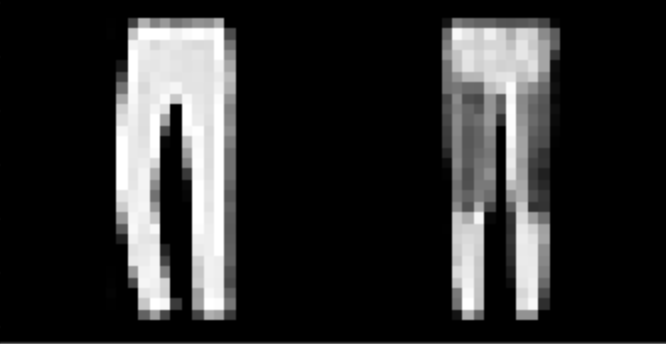



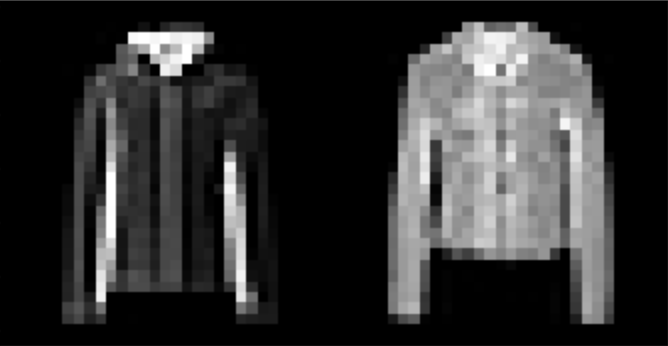
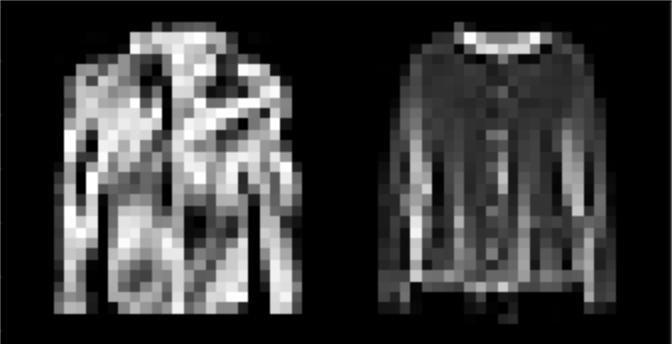
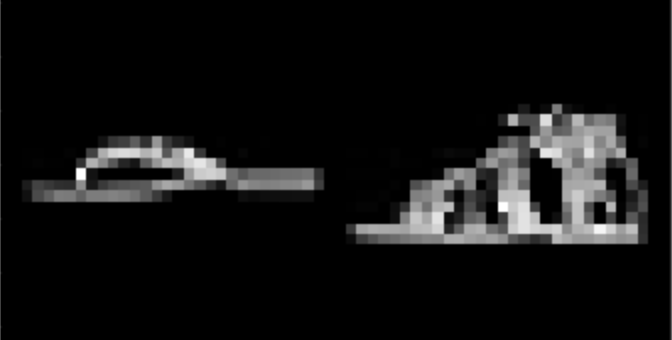
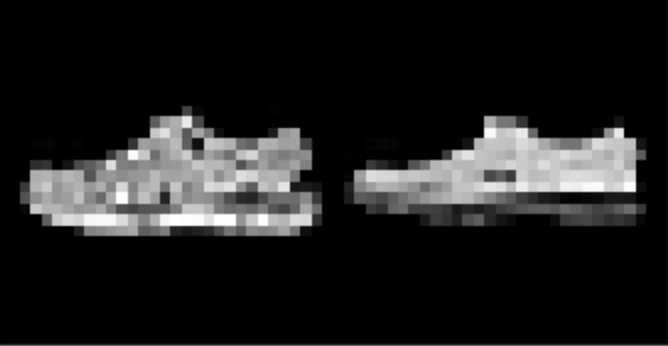


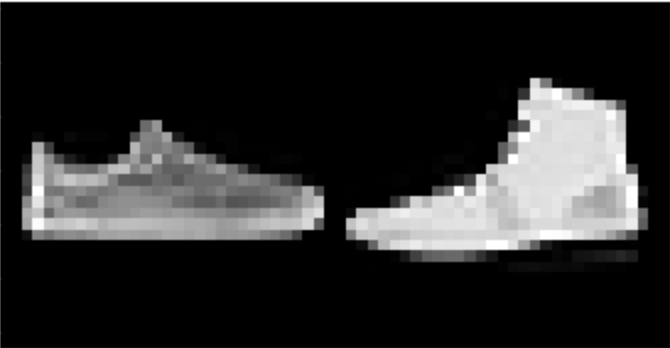
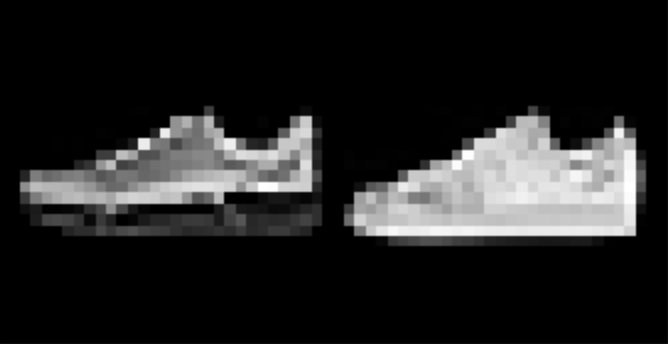


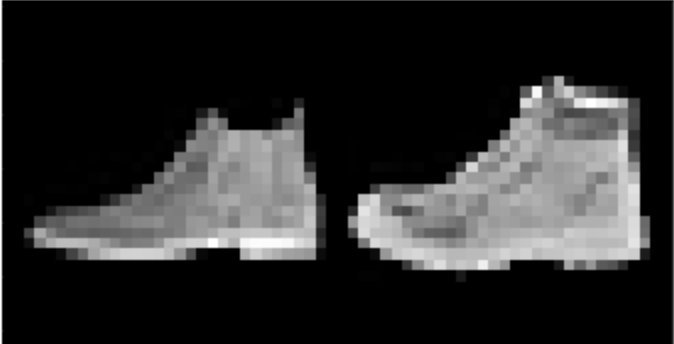




I used a UNet with 14 convolutional layers, as well as 3 pooling and 3 tranpose convolutional layers. Further information about the model architecture can be seen here:
| Layer | Output Shape | # Learnable Parameters |
|---|---|---|
| Conv2d-1 | [-1, 16, 256, 256] | 448 |
| Conv2d-2 | [-1, 24, 256, 256] | 3,480 |
| MaxPool2d-3 | [-1, 24, 128, 128] | 0 |
| Conv2d-4 | [-1, 36, 128, 128] | 7,812 |
| Conv2d-5 | [-1, 52, 128, 128] | 16,900 |
| MaxPool2d-6 | [-1, 52, 64, 64] | 0 |
| Conv2d-7 | [-1, 72, 64, 64] | 33,768 |
| Conv2d-8 | [-1, 96, 64, 64] | 62,304 |
| MaxPool2d-9 | [-1, 96, 32, 32] | 0 |
| Conv2d-10 | [-1, 96, 32, 32] | 83,040 |
| Conv2d-11 | [-1, 96, 32, 32] | 83,040 |
| ConvTranspose2d-12 | [-1, 96, 64, 64] | 36,960 |
| Conv2d-13 | [-1, 72, 64, 64] | 62,280 |
| Conv2d-14 | [-1, 52, 64, 64] | 33,748 |
| ConvTranspose2d-15 | [-1, 52, 128, 128] | 10,868 |
| Conv2d-16 | [-1, 36, 128, 128] | 16,884 |
| Conv2d-17 | [-1, 24, 128, 128] | 7,800 |
| ConvTranspose2d-18 | [-1, 24, 256, 256] | 2,328 |
| Conv2d-19 | [-1, 16, 256, 256] | 3,472 |
| Conv2d-20 | [-1, 5, 256, 256] | 725 |
| ReLU-21 | [-1, 5, 256, 256] | 0 |
| Total params | 465,857 |
| Trainable params | 465,857 |
| Non-trainable params | 0 |
| Input size (MB) | 0.75 |
| Forward/backward pass size (MB) | 89.00 |
| Params size (MB) | 1.78 |
| Estimated Total Size (MB) | 91.53 |
I used Cross Entropy as my loss, and Adam as my optimizer, with a learning rate of 1e-4 and a weight decay of 1e-4
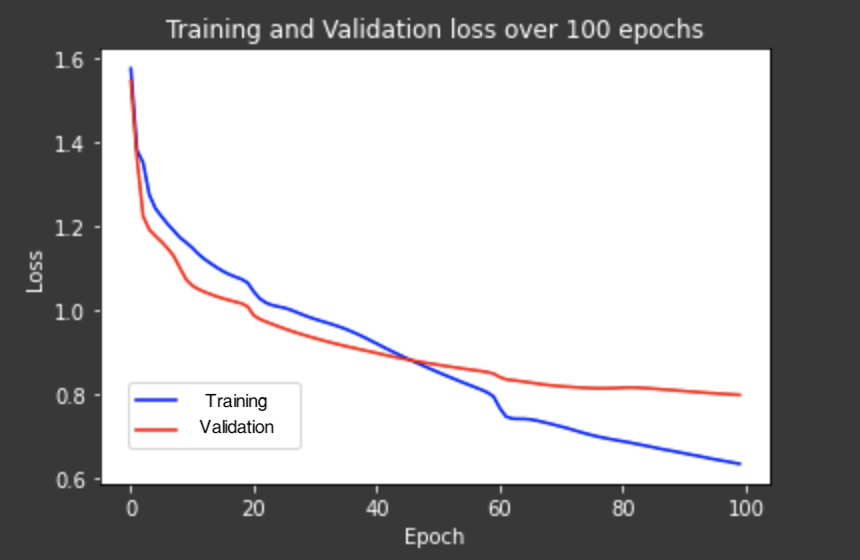
My segmentation seemed to capture the windows and ledges well, however, it obviously didn't know what a wall was (it had a very low AP for this as well) and wasn't very good at railings either.