Part 1: Image Classification
I used code largely adapted from the tutorials linked in the spec to create a CNN with 2 convolution layers and 2 fully connected layers for the classification task, trained using Cross-Entropy Loss. My first convolution layer used a kernel size of 5 and had 128 output channels. My second convolution layer used a kernel of size 5 and had 512 output channels. After lots of experimentation, I found that using LeakyReLU nonlinearities and an Adam optimizer with learning rate 0.003 and L2 regularization term of 0.00008 worked best for my network. Each convolution layer was followed by a LeakyReLU and a 2x2 Maxpool. I used an 80-20 train/validation split, and after training on all 50,000 training images for 14 epochs with batchsize 32, I got an overall test and validation accuracy of 89.45%. Below are my per class accuracies:
- Class 0 (t-shirt): 89.1%
- Class 1 (trousers): 97.9%
- Class 2 (pullover): 87.0%
- Class 3 (dress): 94.1%
- Class 4 (coat): 75.0%
- Class 5 (sandal): 98.7%
- Class 6 (shirt): 63.2%
- Class 7 (sneaker): 95.7%
- Class 8 (bag): 97.6%
- Class 9 (ankle boot): 96.2%
The accuracies above clearly show that the shirt and coat classes were hardest to correctly classify (lots of false negatives that were instead classified as t-shirt, coat, etc...).
In order are my plots of training and validation loss during training, training and validation accuracy during training, examples of successfully and unsuccessfully classified images of each class, and visualizations of the filters from the first convolution layer.
Training and Validation Loss:
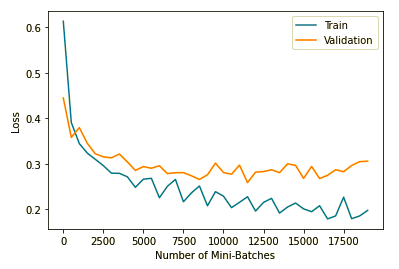
Training and Validation Accuracy:
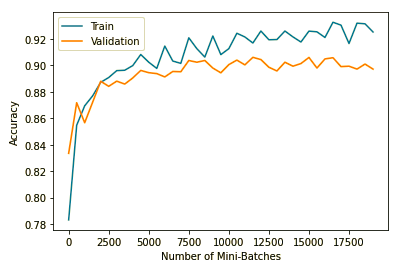
Successes and Failures:




Filter Visualizations


Part 2: Semantic Segmentation
This part involved semantcally segmenting images of buildings to find which pixels depicted "other", facades, pillars, windows, and balconies. I used the provided code to set up my dataloaders, calculate AP scores, and get results. To actually create my model, I used U-Net (a famous segmentation model you can read about here) as an inspiration. I first pass my data through a convolution layer with 64 output channels and a LeakyReLU nonlinearity. I save this result as "skip connection 1," then use 2x2 Maxpool to spatially shrink my image before passing it through another convolution layer (with 256 output channels) and another LeakyReLU. I save this result as skip connection 2 before using another 2x2 Maxpool to spatially shrink the data. Then I pass it through another convolution layer and LeakyReLU with 256 output channels. I then spatially upsample this result (with a scale factor of 2), concatenate (stack along the channels dimension) skip connection 2, and pass this result through a fourth convolution layer and LeakyReLU with 64 output channels. I then re-spatially upsample this data to get back to the original resolution, and concatenate (stack along the channels dimension) skip connection 1. I pass this through a fifth convolution layer and LeakyReLU with 32 output channels. Finally I pass this through a sixth convolution layer with 5 output channels (1 per class). All convolutions has enough padding to ensure outputs have the same resolution as the input. I calll this arcitecture SmolUNet, and use Cross-Entropy Loss and an Adam optimizer (with learning rate 0.00003 and L2 regularization parameter 0.000001). I used an 85-15 split on the training data to get by train and validation loaders. I trained for 100 epochs to get an average AP score of 52.32. My per-class AP Scores are:
- Class 0 (other): 63.44
- Class 1 (facade): 70.37
- Class 2 (pillar): 8.37
- Class 3 (window): 80.30
- Class 4 (balcony): 39.11
From these results it's clear the model is not good at segmenting pillars, but is good at segmenting windows. This can be clearly seen in the examples below, where there are lots of false positives for pillars, but the windows look good.
In order are: the plot of my training and validation loss, the colormap, then some example images and their corresponding segmentations.
Training and Validation Loss:
Segmentation Colormap:

Segmentation Examples (Original then Segmented)







