For this part of the project, we trained a convolutional neural network on Fashion MNIST.
Most of the following images and charts were collected using the wonderful Weights and Biases API!
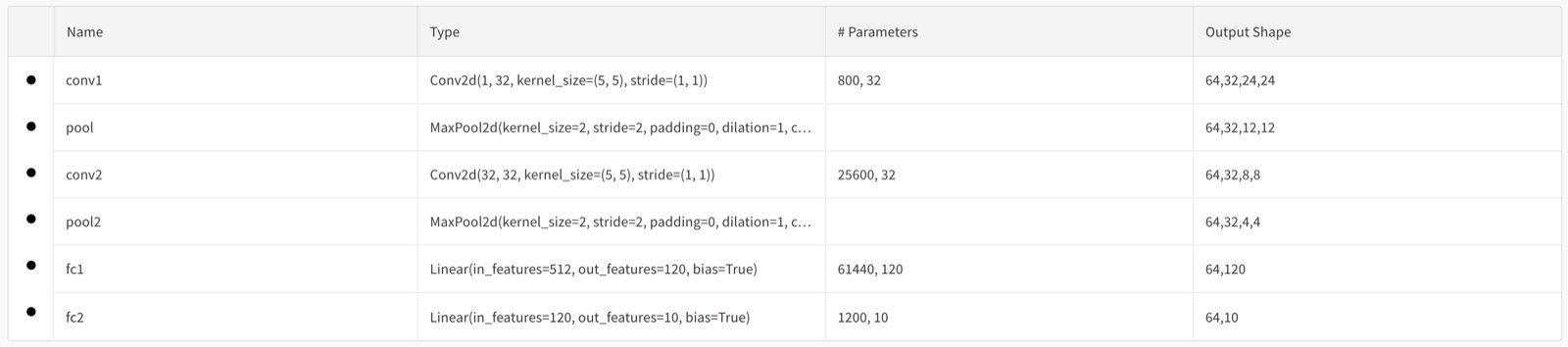
I used the following model:
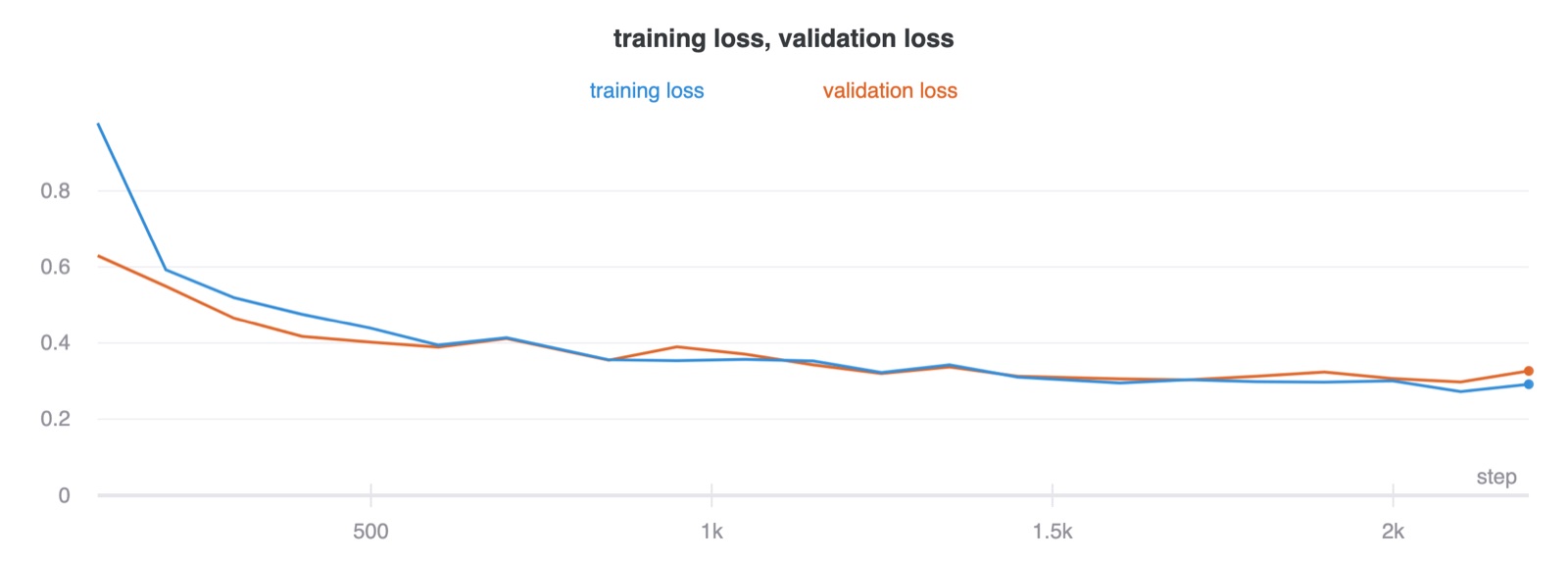
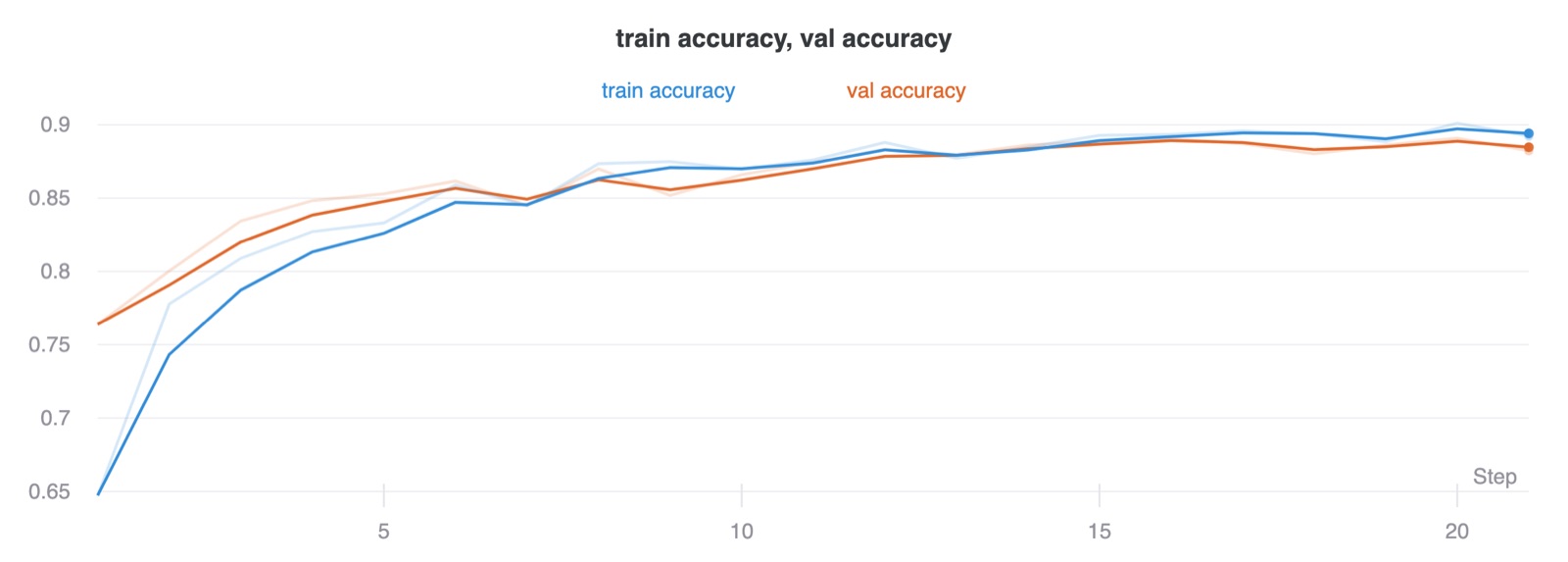
I first trained a few models with a hundred epochs to find a good set of hyperparameters. I ended up using an Adam optimizer with a learning rate of \(0.001\) and \(3\) epochs with a batch size of \(64\). Training it longer than that casued the model to overfit. I trained this on an Azure virtual machine with a P100 that I had access too. Here is the loss and accuracy curves plotted every one hundred iterations.
Here are the learned first layer filters:

And here are some images from the validation and test set that it classified correctly and incorrectly:




The test accuracies are: [0.831,0.967,0.797,0.875,0.919,0.975,0.62,0.936,0.954,0.969] The validation accuracies are: [0.842,0.967,0.797,0.882,0.924,0.96,0.64,0.93,0.953,0.97]
It seems like the hardest class for teh flassifier is shirt and the easiest is sandal. This makes sense because the shirt can easily be mistaken for a pullover or a dress but a sandal seems to be very visually distinct from the other filters.
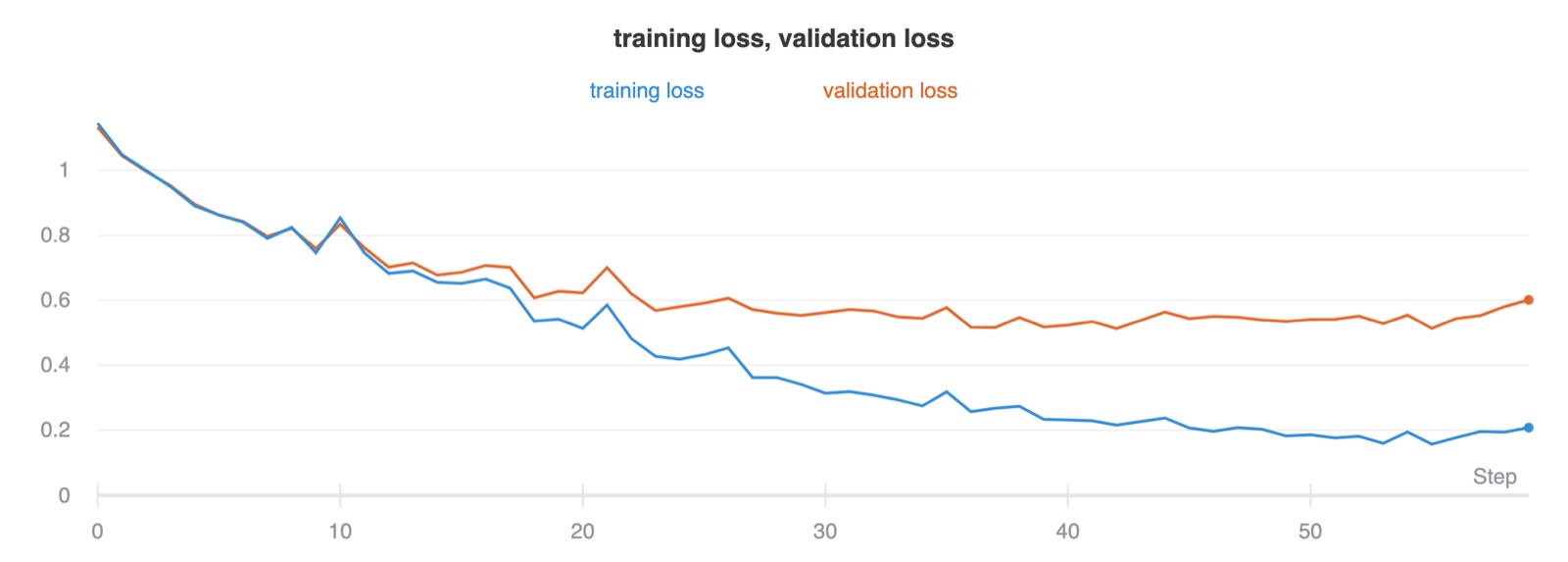
For this part of the project, I used a convolutional neural network. I used 6 layers. The first layer had 64 filters, the second had 128 filters, the third had 256, the fourth and fifth 512 and the last five. Each convolution layer had a filter size of 5 except for the last with size 3. Every convolution layer had a padding of 2 except for the last with size 1. This was so the convolution layers do not change the size of the image. Each convolution layer is followed by a relu. The first and second RELU’s are followed by a maxpool of size 2 an the fourth and fifth relus are followed by an upsample layer of size 2 with bilinear upsampling mode. Finally, to improve training and decrease covariant shift, I used a batchnorm layer before every convolution layer after the fist. I trained using a batch size of 16. I found that using smaller batch sizes performed worse. I wanted to try larger batch sizes, but I ran out of GPU memory on computer. I suspect larger batch sizes would perform better. I tried serveral experiments varying the learning rate and teh weight decay. With a decreased learning rate the model seemed to overfit quicker and with a larger learning rate the model did not fit as well. A lowered weight decay also caused some overfitting.
Here is the training and validation loss:
The average precisions for the different classes are as follows
AP = 0.6959684177146221
AP = 0.780966213029083
AP = 0.25493724558067876
AP = 0.8621367653405938
AP = 0.619522272527737
Here are examples of an input, output and ground truth images:



This model is good at windows and really not much else