

This project utilizes deep neural networks for image classification on the Fashion-MNIST dataset and semantic segmentation on the mini Facade dataset. The models were trained using PyTorch on Google Colab.
I used the suggested CNN architecture for this part. This starts with 2 convolutional layers, 32 channels each, where each conv layer is followed by a ReLU followed by a maxpool. This is followed by two fully connected layers with a ReLU function applied after the first connected layer. The labels span from 0-9 and their meanings are below:
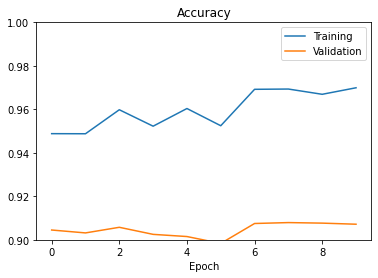
I used an 80/20 split on the original training set of images get training/validation sets. The model was trained using the suggested cross entropy loss and Adam optimization method with a modified .0008 learning rate over 10 epochs. The plot of training/validation accuracy across each epoch is below:
The model achieved an accuracy of 90% on the test set and the test/validation accuracies per class are below:
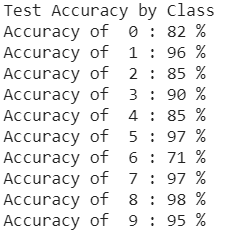
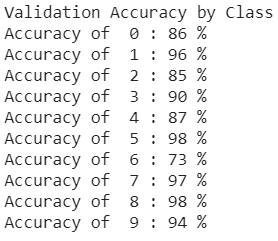
The hardest to classify were classes 0 and 6, corresponding to T-Shirt and Shirt. This makes sense since these articles are similar to each other and other articles like Pullover and Dress. Some examples of correctly prediced images are below:
T-Shirt
Trouser


Pullover


Dress


Coat


Sandal

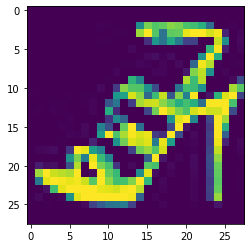
Shirt


Sneaker

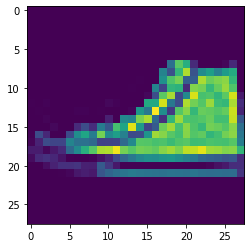
Bag


Ankle Boot

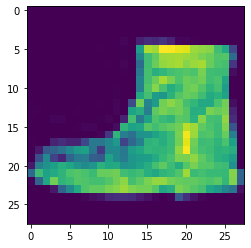
Next, some examples of incorrectly classified images presented below:
T-Shirts prediced as a pullover and shirt, respectively:


Trousers prediced as dresses:


Pullovers prediced as shirts:

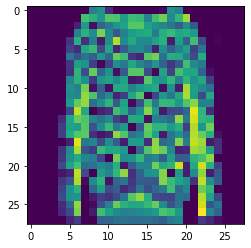
Dresses prediced as a t-shirt and coat, respectively:


Coats prediced as shirts:


Sandals prediced as a sneakers and ankle boot, respectively:

Shirts prediced as a t-shirt and dress, respectively:


Sneakers prediced as sandals:


Bags prediced as a coat and shirt, respectively:

Ankle Boots prediced as sneakers:
Next, a visual of the first convolutional filter is presented below. Note that the differences in each channel of the filter help the model learn different features of the image for accurate classification.
In this part, I used a deep neural network for semantic segmentation on the mini Facade dataset. Each pixel of an image is classified as one of the five labels below:
I utilized a CNN architecture with five convolutional layers, upsampling with nn.ConvTranspose2d to format the outputs when needed. The exact network I used is shown below:

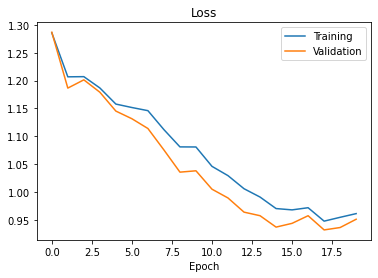
For training, I used the suggested cross entropy loss with the Adam optimizer with 1e-3 learning rate and 1e-5 weight decay across 20 epochs. I also split the training set into training/validation by an 80/20 split. The plot of training/validation loss over the epochs in training is below:
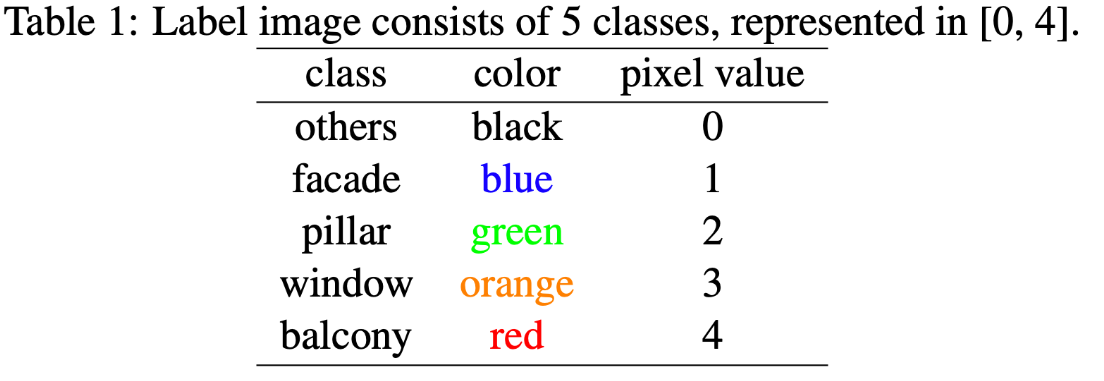
The Average Precision on the test set and splits across classes are as follows:
others: .4970
facade: .6535
pillar: .0693
window: .4285
balcony: .3732
mean Average Precision: .4043
An example image and the output of the model classifying pixels is below:


The model predicted a significant of the image correctly, but was wrong in majority. Most of the window pixels were correct, but there were some areas that were wrongly predicted as windows. Also, the facade elements were correctly predicted, but the pillars were not predicted correctly. The sky was also incorrectly predicted as a facade instead of other.