Part 1: Classification

Objective
Our first objective was to classify images of clothing using our predictor, a convolutional neural network (CNN). For this project, we worked with the Fashion MNIST dataset, which consists of 10 classes and 60000 train + validation images and 10000 test images.
Convolutional Neural Network Architecture
My CNN's architecture consisted of two convolutional layers each separated by a ReLU and a max pooling layer, followed by 3 fully connected layers. Given our CNN, the next step was to define a loss function and optimizer to train our predictor.After trying different optimizers, learning rates, and values of weight decay, I found that I got the best results using an AdamOptimizer with a learning rate of lr=0.001. For the loss, I used CrossEntropyLoss. The batch size was 50 and I ran the network for 10 epochs. I also did an 80/20 split for the training and validation set, and used the validation set to select hyperparameters. A more detailed architecture description is below:
| Layer type | Parameters |
|---|---|
conv2d |
in_channels=3, out_channels=32, kernel_size=3 |
relu |
|
max_pool2d |
filter_size=2 |
conv2d |
in_channels=32, out_channels=32, kernel_size=3 |
relu |
|
max_pool2d |
filter_size=2 |
linear |
in_features=32*5*5, out_features=120 |
linear |
in_features=120, out_features=84 |
linear |
in_features=84, out_features=10 |
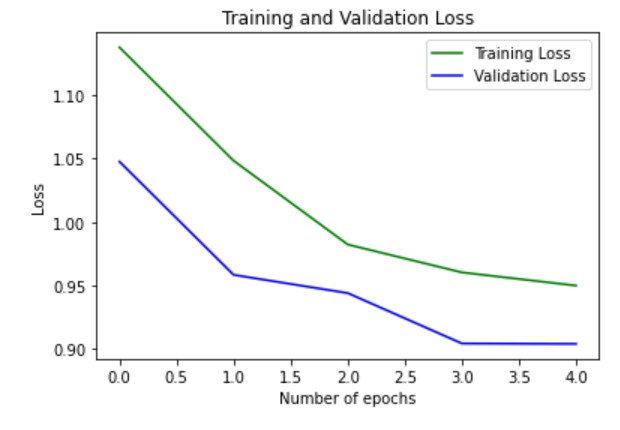
The training and validation accuracy graphed with respect to the number of epochs is below. We see that the training accuracy becomes larger than the validation accuracy after a certain number of epochs, indicating that we are overfitting on the train set.
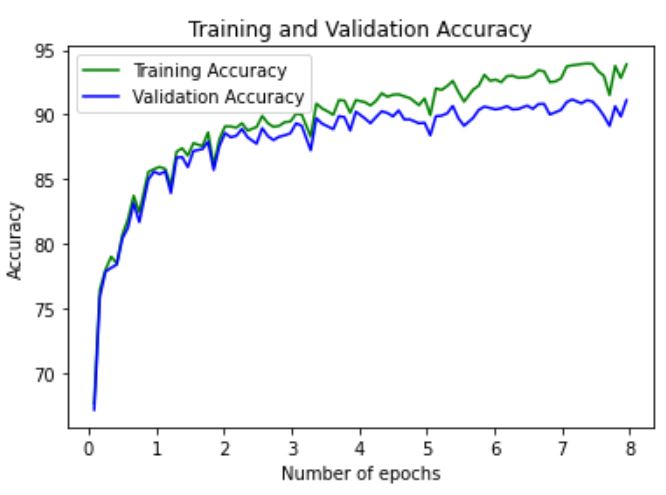
Below is a more detailed breakdown of the accuracy between classes, for both the training and validation sets. The results of training give an overall accuracy of 90%. I found that class 4 (coat) and class 6 (shirt) had the lowest rates of accuracy.
| Class number | Class name | Training accuracy | Validation accuracy |
|---|---|---|---|
0 |
t-shirt |
90% |
93% |
1 |
trouser |
97% |
98% |
2 |
pullover |
88% |
91% |
3 |
dress |
92% |
95% |
4 |
coat |
81% |
84% |
5 |
sandal |
97% |
99% |
6 |
shirt |
72% |
78% |
7 |
sneaker |
94% |
95% |
8 |
bag |
98% |
98% |
9 |
ankle boot |
97% |
98% |
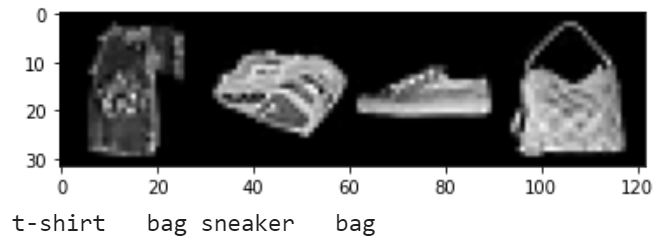
Below, we can see some examples from each class where the item was classified correctly and incorrectly. Some classes, such as the shirt and coat classes, seem to be incorrectly classified since they tend to have more ambiguous shapes.
| Class name | Correctly classified | Incorrectly classified |
|---|---|---|
t-shirt |


|


|
trouser |


|


|
pullover |


|


|
dress |


|


|
coat |


|


|
sandal |


|


|
shirt |


|


|
sneaker |


|


|
bag |


|


|
ankle boot |


|


|
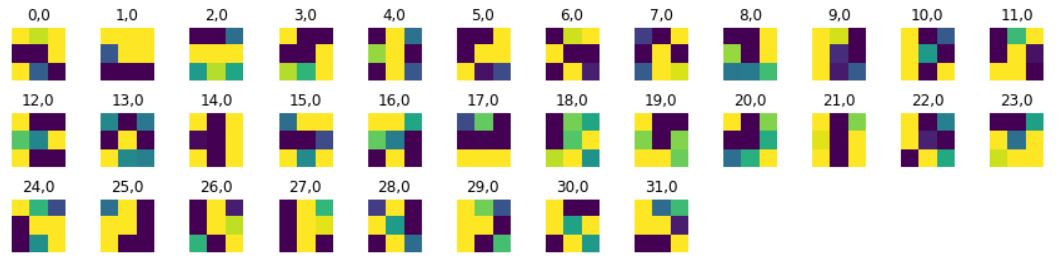
Finally, the learned filters of the first layer can be seen as follows: