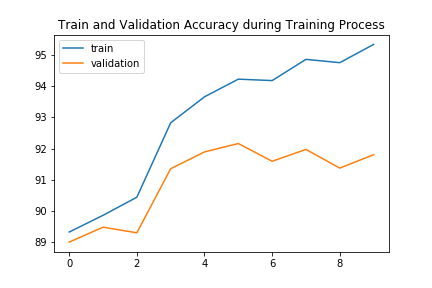
This part solves image classification in the Fasion MNIST dataset using Deep Nets. My Convolutional Neural Network has 2 convolutional layer (torch.nn.Conv2d), where each conv layer will be followed by a ReLU(torch.nn.ReLU) followed by a maxpool(torch.nn.MaxPool2d), then followed by 2 fully connected networks(torch.nn.Linear).
|
| Class Label | Accuracy on Validation Dataset(%) | Accuracy on Test Dataset (%) |
| T-shirt/top | 84.6 | 84.7 |
| Trouser | 99.2 | 98.8 |
| Pullover | 85.0 | 85.1 |
| Dress | 93.3 | 93.6 |
| Coat | 84.9 | 82.1 |
| Sandal | 98.3 | 98.3 |
| Shirt | 80.5 | 77.0 |
| Sneaker | 98.4 | 98.0 |
| Bag | 97.0 | 97.3 |
| Ankle boot | 96.0 | 94.6 |
Shirt is the hardest to classify, with an accuracy of 80.5% on Validation dataset and 77.0% on Test dataset. My classifier achieves greatest accuracy in Trouser class with a 99.2% accuracy on Validation dataset and 98.8% on Test dataset.
| Class Label | Correct Classification | Incorrect Classification |
| T-shirt/top |   |
  Classified as Shirt(L/R) |
| Trouser |   |
  Classified as Dress(L)/Coat(R) |
| Pullover |   |
  Classified as Shirt(L)/Dress(R) |
| Dress |   |
  Classified as Shirt(L)/Coat(R) |
| Coat |   |
  Classified as Shirt(L)/Pullover(R) |
| Sandal |   |
  Classified as Sneaker(L)/Ankle Boot(R) |
| Shirt |   |
  Classified as T-Shirt(L)/Pullover(R) |
| Sneaker |   |
  Classified as Ankle Boot(L/R) |
| Bag |   |
  Classified as T-Shirt(L/R) |
| Ankle Boot |   |
  Classified as Sandle(L)/Sneaker(R) |
 32 filters of the first convolutional layer |
Semantic Segmentation refers to labeling each pixel in the image to its correct object class. This part solves semantic segmentation of the Mini Facade dataset by training a network that converts images of different cities and architectural styles to the labels in 5 classes: balcony, window, pillar, facade, and others.
| Layer | Input Channel | Output Channel | kernel | padding | stride |
| Conv2d | 3 | 64 | 3 | 1 | - |
| Conv2d | 64 | 128 | 3 | 1 | - |
| MaxPool2d | 128 | 128 | 2 | - | 2 |
| Conv2d | 128 | 256 | 3 | 1 | - |
| Conv2d | 3 | 256 | 512 | 1 | - |
| MaxPool2d | 512 | 512 | 2 | - | 2 |
| Conv2d | 512 | 512 | 1 | 0 | - |
| Conv2d | 512 | 5 | 1 | 0 | - |
| ConvTranspose2d | 5 | 5 | 8 | 2 | 4 |
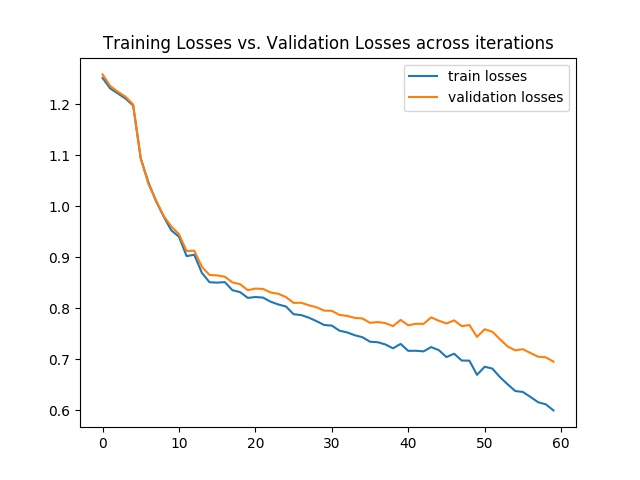 |
| Class Label | Average Precision |
| Balcony | 0.626 |
| Window | 0.699 |
| Pillar | 0.101 |
| Facade | 0.794 |
| Others | 0.360 |
| Averaged | 0.516 |
 My Photo taken in Mexico City |
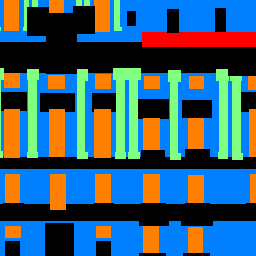 Semantic Segmentation Result |
The result shows great precision in windows, facade and others, but less ideal in pillars and balcony.