Image Classification and Segmentation
Sean Chen
Part 1: Image Classification
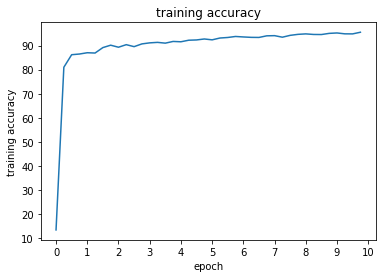
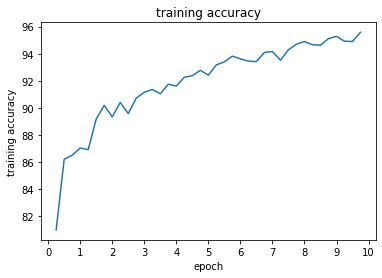
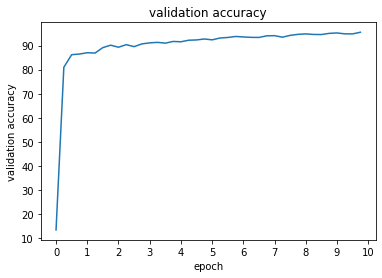
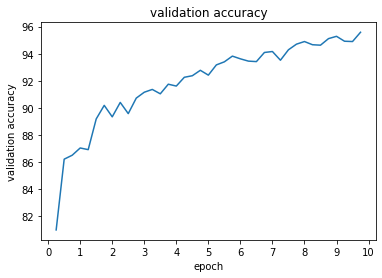
Val Accuracy of the network: 95 %
Test Accuracy of the network: 90 %
Accuracy of T-shirt/top : 84 %




Accuracy of Trouser : 97 %


Accuracy of Pullover : 89 %




Accuracy of Dress : 92 %



Accuracy of Coat : 88 %




Accuracy of Sandal : 97 %



Accuracy of Shirt : 67 %



Accuracy of Sneaker : 97 %



Accuracy of Bag : 97 %



Accuracy of Ankle boot : 95 %

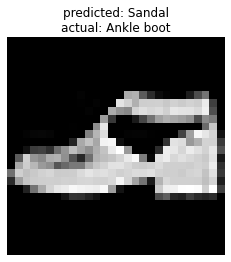


Part 2: Semantic Segmentation
Network architecture
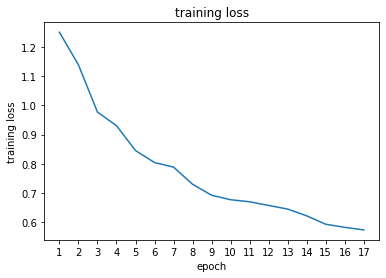
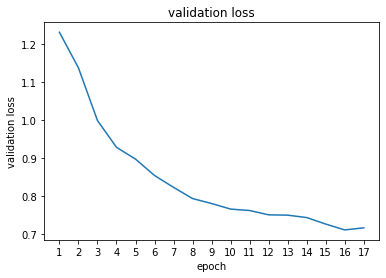
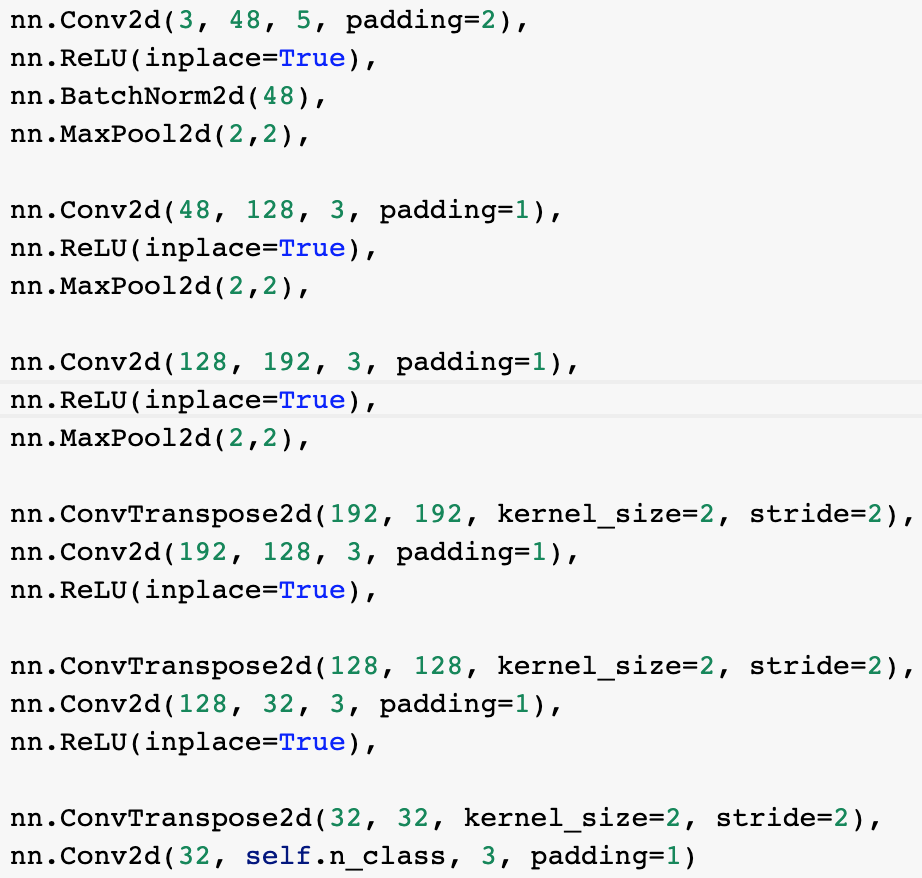
I used a deep convolutional neural net with 6 layers. The first 3 convolutional layers grow the number of channels from 48 to 128 to 192. After each convolution, the image shrinks by a factor of 2. There's also nonlinearities and a batch norm. Then, the last 3 layers are upscaling the network. The ConvTranspose2d upsamples the image by a factor of 2, while keeping the number of channels constant. Then we shrink the channels to eventually get to 5, which is our desired output.
| Loss | Cross entropy |
|---|---|
| Optomizer | Adam |
| Learning rate | 1e-3 |
| Weight decay | 1e-5 |
| Epochs | 17 |

| Class | Average percision on test set |
|---|---|
| others | 0.6794454505246241 |
| facade | 0.7672731673796042 |
| pillar | 0.15840029845440098 |
| window | 0.847716567883514 |
| balcony | 0.49730511712925923 |
Results



