Part 1: Image Classification¶
Below are a few sample images from the training and test sets of Fashion-MNIST.
Training set:

Test set:

I split the default training set into 90% training, 10% validation. I trained each model for 200 epochs, and then evaluated the model with the highest validation accuracy on the test set.
For the runs with the Adam optimizer (baseline, trials 1-3), the validation accuracy rises quickly, then fluctuates largely. The validation loss also rises as training loss decreases, indicative of overfitting.
In trials 4-7, when switching to SGD with an inital learning rate of 0.01 and decaying by a factor of 10 every 60 epochs, the training curves are noticeably more stable. The performace also improves. Further experimenting with various batch sizes, I find that batch size 64 works best, giving a test accuracy of 92.07%.
Baseline:
Batch size 128
Learning rate 0.01
conv(32 output channels)
conv(32 output channels)
fc(256 output features)
fc(10 output features)
Test Accuracy: 87.88%
Trial 1:
Batch size 128
Learning rate 0.01
conv(32 output channels)
conv(64 output channels)
fc(128 output features)
fc(10 output features)
Test Accuracy: 88.85%
Trial 2:
Batch size 128
Learning rate 0.1
Same architecture as Trial 1
Test Accuracy: a terrible 10%
Trial 3:
Batch size 256
Learning rate 0.01
Same architecture as Trial 1
Test Accuracy: 89.79%
Trial 4:
Batch size 256
Learning rate 0.01
Same architecture as Trial 1
SGD optimizer, LR decay by factor of 10 every 60 epochs
Test Accuracy: 90.99%
Trial 5:
Batch size 512
Rest same as Trial 4
Test Accuracy: 89.39%
Trial 6:
Batch size 128
Rest same as Trial 4
Test Accuracy: 91.84%
Trial 7:
Batch size 64
Rest same as Trial 4
Test Accuracy: 92.07%
The curves for train loss, validation loss, and validation accuracy for all trials are below. I used Weights & Biases to track the runs. Interestingly, the best trial (trial 7) did not have the lowest validation loss, but had the highest validation accuracy.
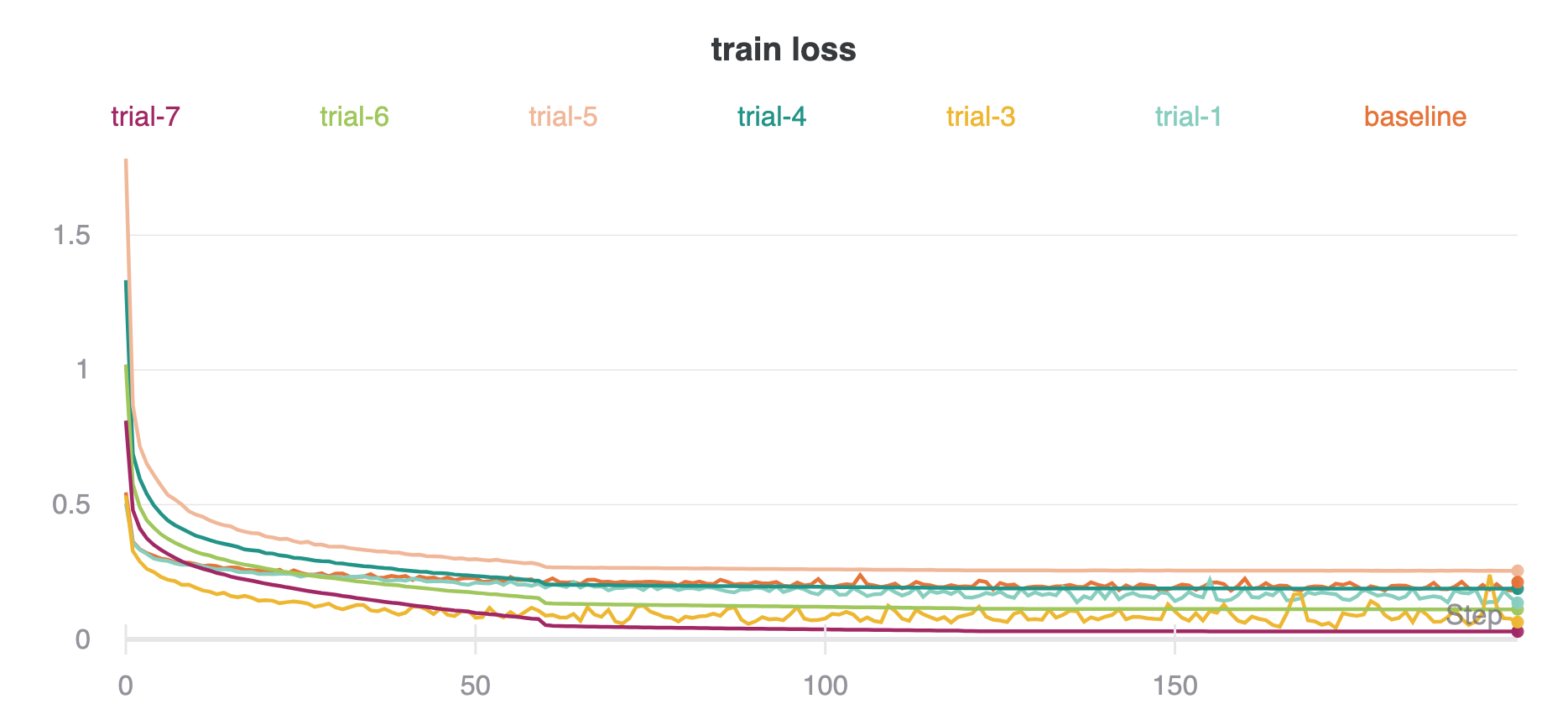
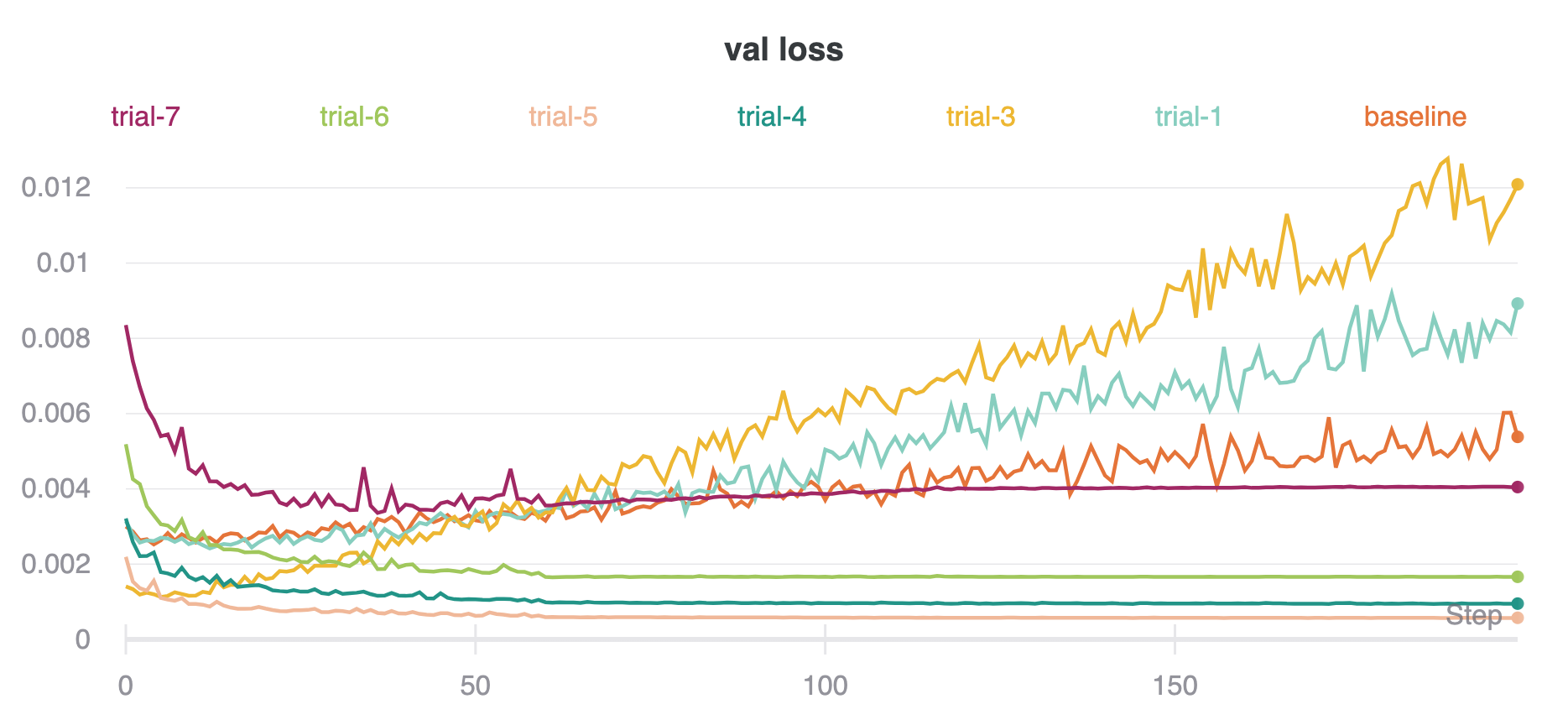
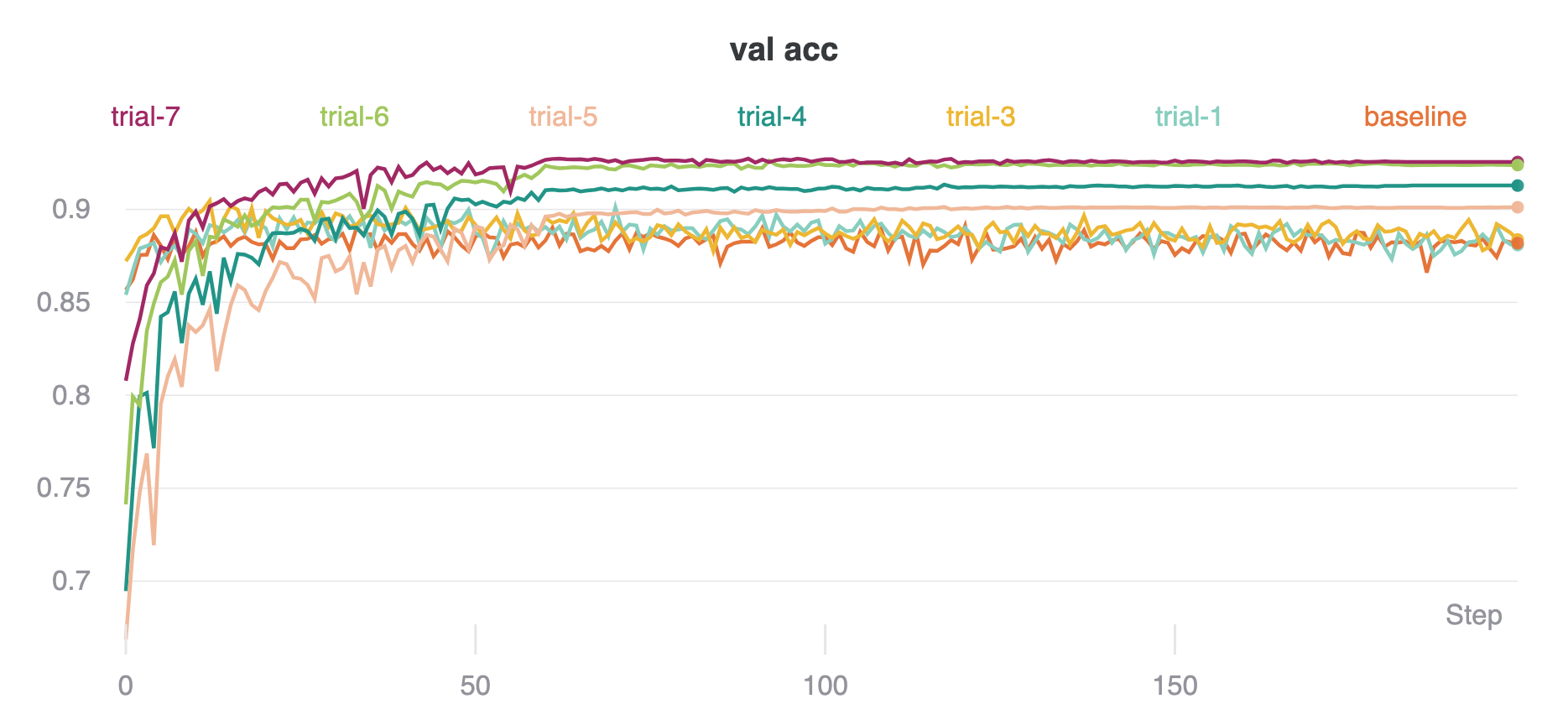
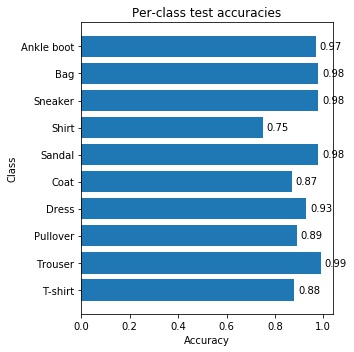
Going off the net in Trial 7, the per-class accuracies are:
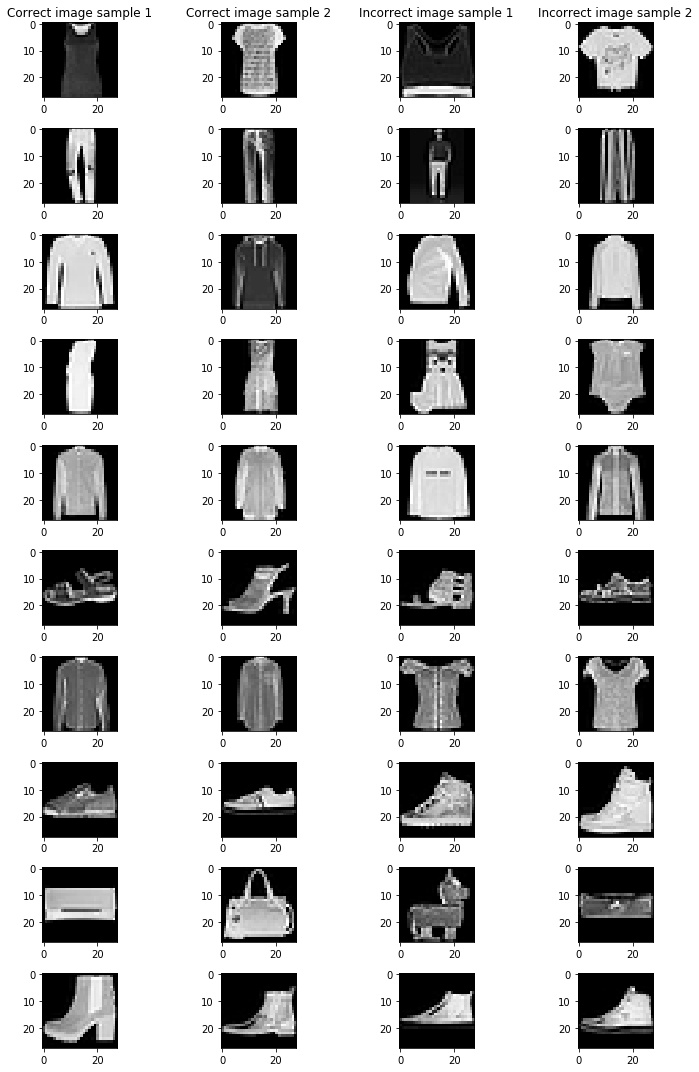
Samples of correct and incorrectly classified examples per class (each row is one class):
The 32 3x3 filters from the first convolutional layer of the trained NN are:

Part 2: Semantic Segmentation¶
The architecture of the model is as follows, with a ReLU after each Conv layer:
- Conv2d(out channels=32, kernel size=5, padding=2)
- Batch Norm
- Conv2d(out channels=64, kernel size=3, padding=1)
- MaxPool2d(window size=2)
- Batch Norm
- Conv2d(out channels=64, kernel size=3, padding=1)
- Batch Norm
- Conv2d(out channels=80, kernel size=3, padding=1)
- Upsample by factor of 2
- Conv2d(out channels=128, kernel size=3, padding=1)
- Conv2d(out channels=10, kernel size=3, padding=1)
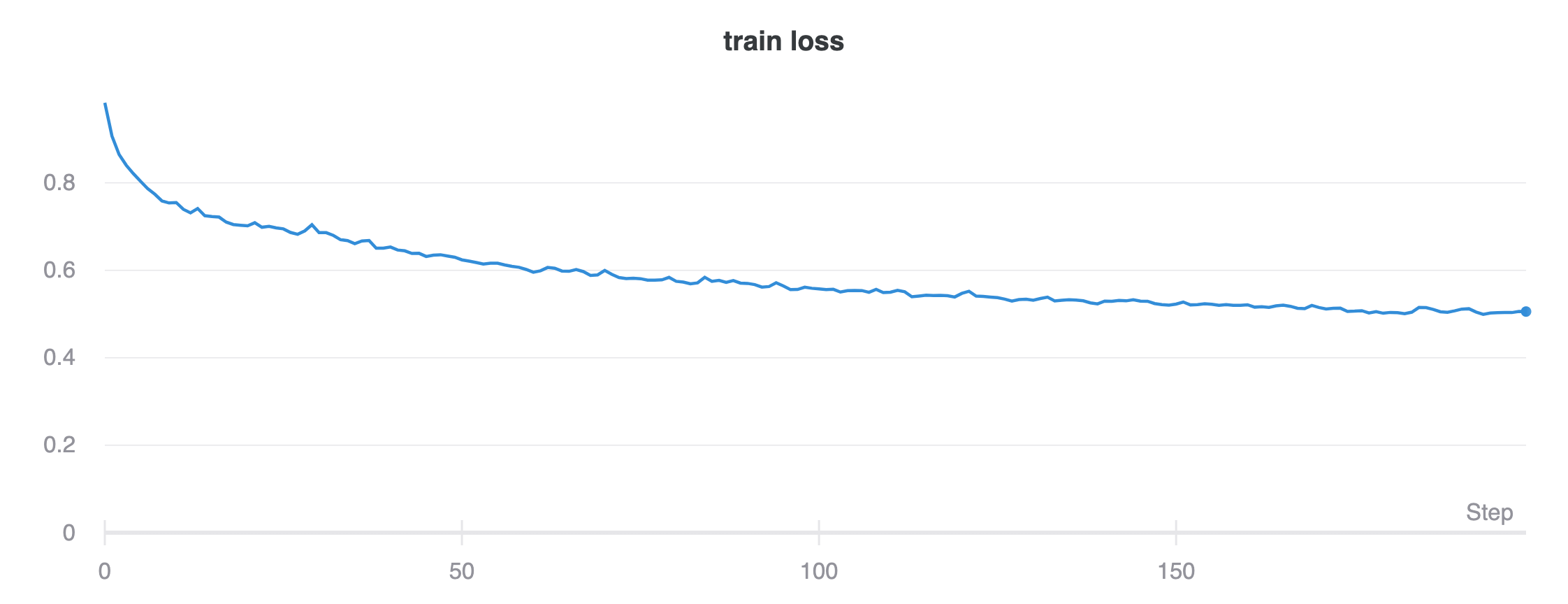
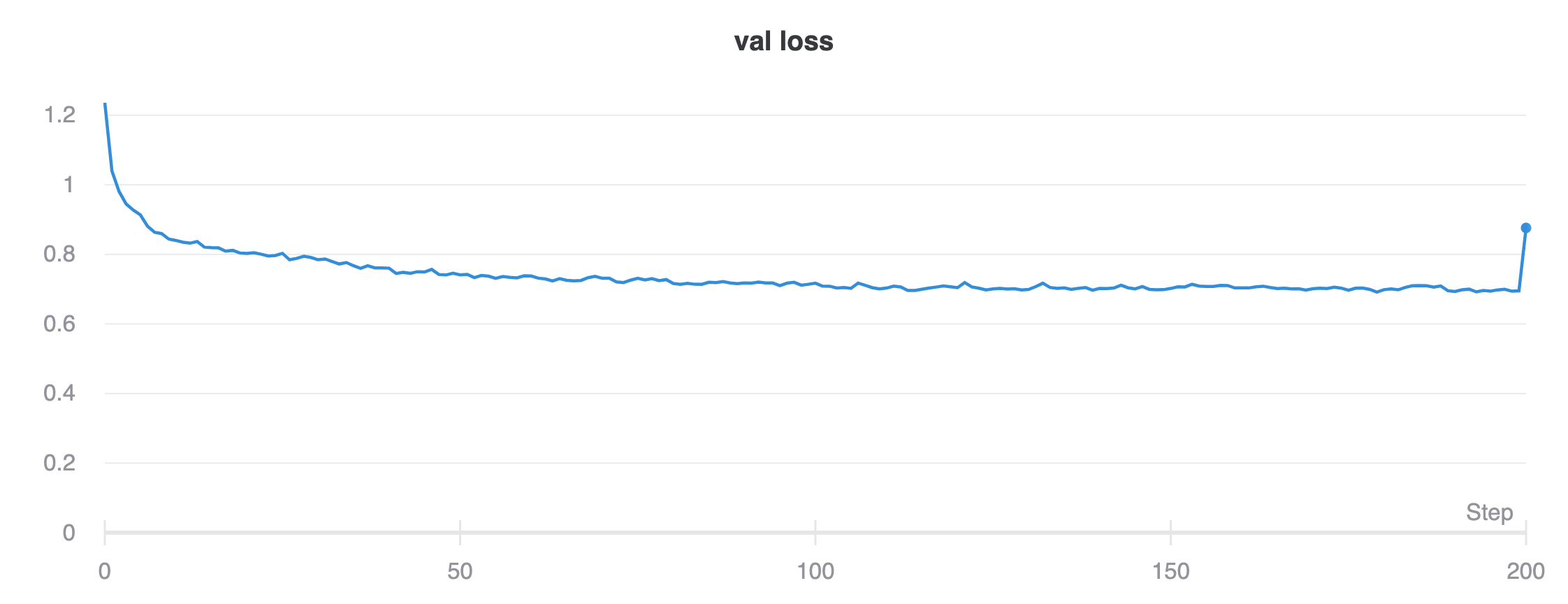
I used the Adam optimizer with a learning rate of 0.001, batch size of 32, and trained for 200 epochs.
Training and validation loss curves are:
AP = 0.49699350462504494
AP = 0.614942294102087
AP = 0.09630091868918697
AP = 0.7210920720646165
AP = 0.2792445698628527
mAP: 0.4417
A sample image (from the Old Town of Warszawa, the capital of Poland, taken from here: https://www.recommend.com/news-tools/warsaw-five-highlights/ ) with its prediction is:

