Project 4: Classification and Segmentation
Part 1:
For this part, I implemented a simple 2-layer cnn that classifies the Fashion-MNIST dataset. The network is composed of two 32-channel convolution layers of 3x3 filters, each followed by a ReLU activation function and a size 2 max pooling. The end of the network are two fully connected layers, first with 100 output channels and the second with 10 output channels, representing likelihood of the image being in each of 10 classes. We take the argmax to be the predicted label. Training is conducted with Cross Entropy loss, Adam optimizer, and learning rate of 0.01 for 15 epochs.
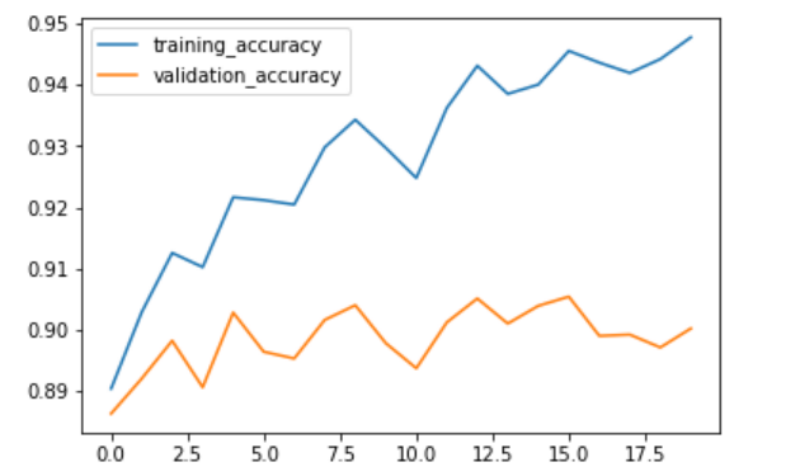
Training and validation accuracy is plotted against number of epochs below.
Below is the visualized filters of the first and second convolution layer.


Below shows the classification accuracy on validation set and test set by class.
Shirt is the hardest class to get, since it easily gets mixed up with T-Shirt and Pullover.
Classes | T-Shirt | T-Shirt | Pullover | Dress | Coat | Sandal | Shirt | Sneaker | Bag | Ankle Boot |
Validation | 0.879 | 0.989 | 0.858 | 0.890 | 0.824 | 0.976 | 0.697 | 0.941 | 0.971 | 0.973 |
Test | 0.872 | 0.983 | 0.870 | 0.853 | 0.806 | 0.975 | 0.687 | 0.946 | 0.974 | 0.973 |
Below shows sample images and classification results.
(Every row has two correctly classified images on the left and two incorrectly classified images on the right.)



Part 2:
For this part, I built a slightly more complex architecture for semantics segmentation. I used 6 convolution layers, each with channels 1*48, 2*48, 4*48, 8*48, 8*48, and 5. Each except the last convolution layer is followed by a ReLU activation. Training is conducted with Cross Entropy loss, Adam optimizer, learning rate of 1e-3 and weight decay of 1e-5 for 40 epochs.
Final result is 0.54 average AP, with 0.66, 0.76, 0.09, 0.79, 0.41 AP for the 5 classes respectively.
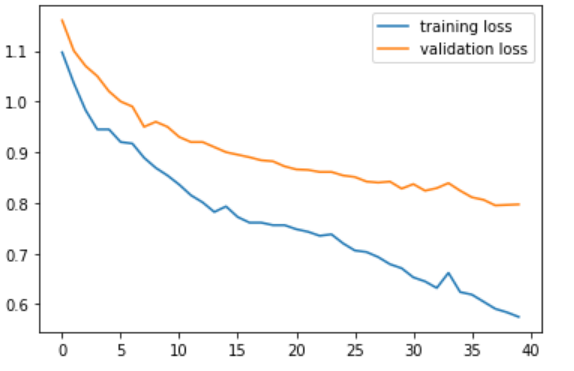
Below shows training and validation loss against number of epochs.
Below shows an example
Photo Ground Truth Predicted

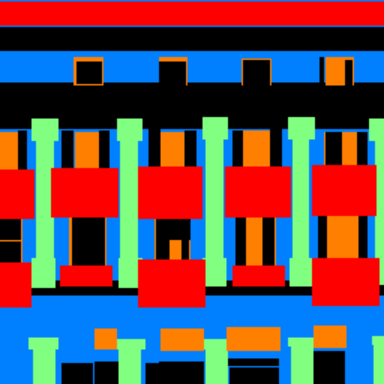

Its result on one of my pictures is shown below. It’s relatively good at detecting windows, but since the building is very different from those in the training set in style, it performs worse in stylistic elements like balcony and pillar.

