
We use a network that has two convolution layer, the first conv layer has 12 channels and the second conv layer has 24 channels. Each of them has kernel size of 3 and is follow the ReLU nonlinearity and a max-pooling layer of size 2 and stride 2.
At the very end we have two fully-connected layers of size 84 and 10 respectively. We use the cross-entropy loss and the network is trained with Adam with a learning rate of 0.001. 1/6 of the training set is used as validation set and the rest is used for training.
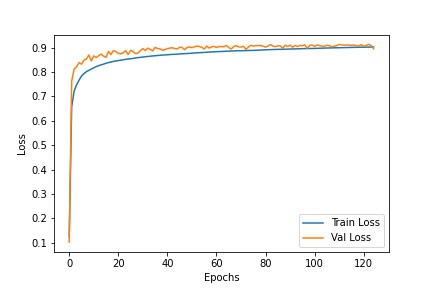
We plot the training accuracy and validation accuracy during training. As training progresses, the network seems to overfit to the training set since the accuracy on the validation set no longer increases.
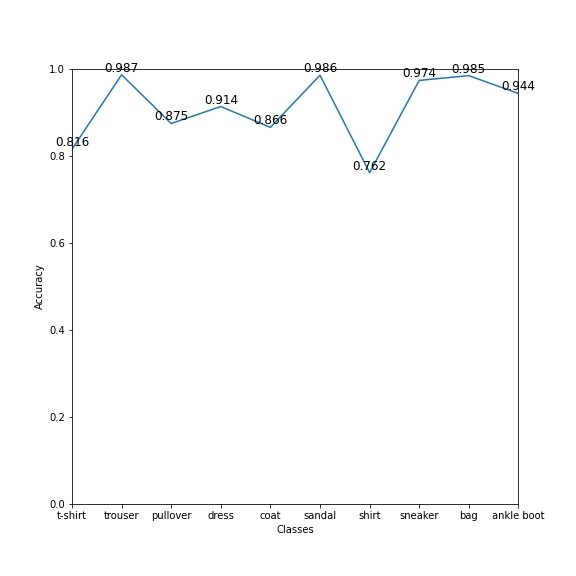
As we can see in the figure, our model performs well in 5 classes, the accuracies of which are more than 90%. However, its performance on shirt is no so good, which is 76.2%.

Here I visualize two conv layers.


Besides, I also visualize two feature maps of the two layers


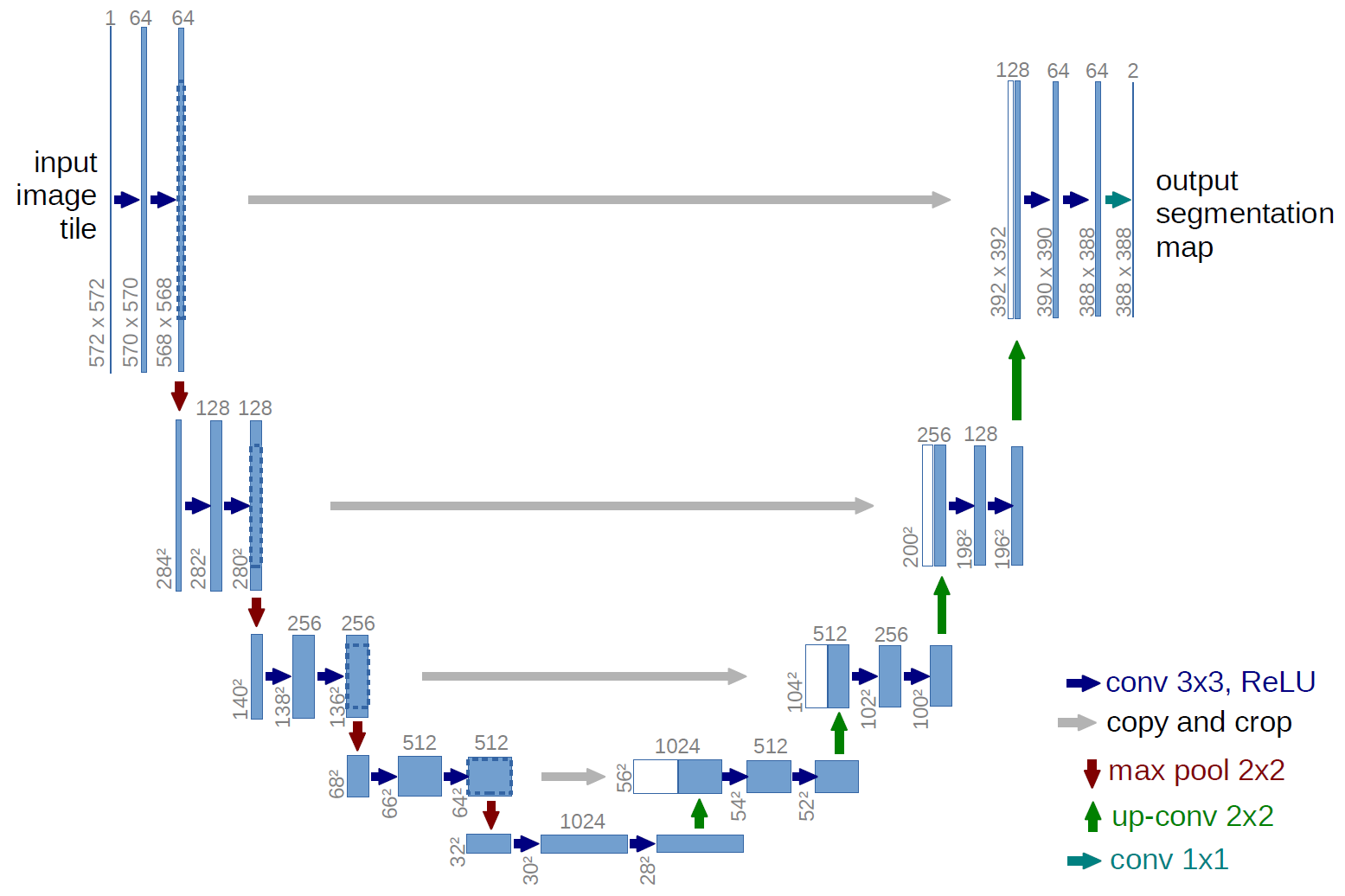
For the network structure, we use UNet to complete segmentation. The structure is below.
Besides, I use Adam and SGD as two optimizers and compare their performance with the learning rate=0.0001. And the weight decay is 0.00001 and momentum is 0.9. The training epoch is 50.
Adam
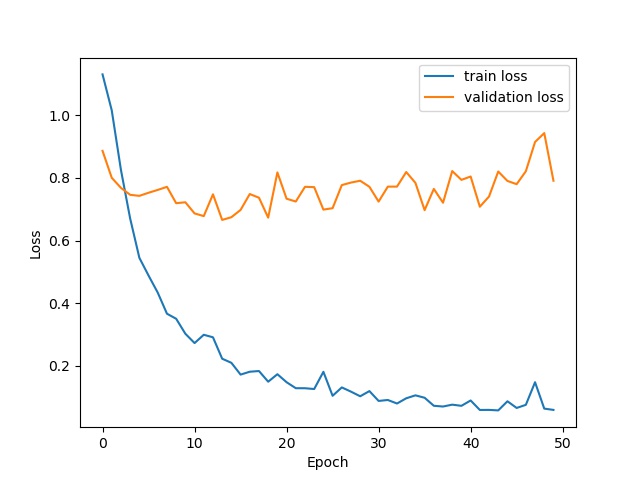
SGD
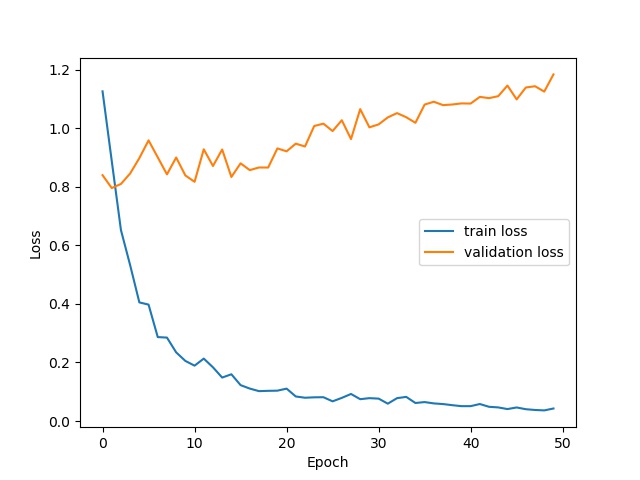
Adam
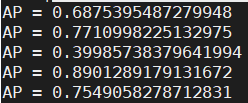
SGD
As we can see, the average AP of Adam model is 0.70 and that of SGD model is 0.62. Thus, the Adam model performs better than SGD model.
Below is some buildings from San Francisco. We can see that it got fight on walls and windows but performs bad on pillars.
| Image | Segmentation |
|---|---|

|
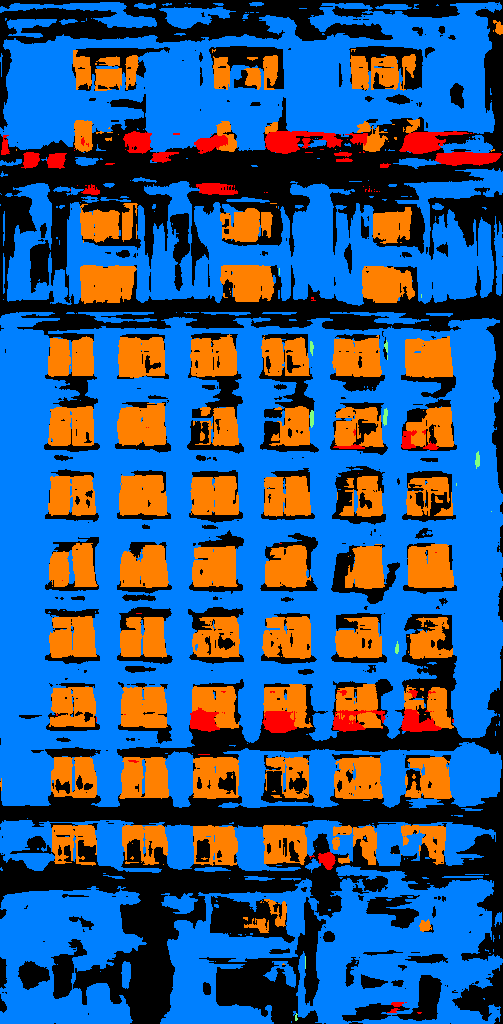
|

|

|

|
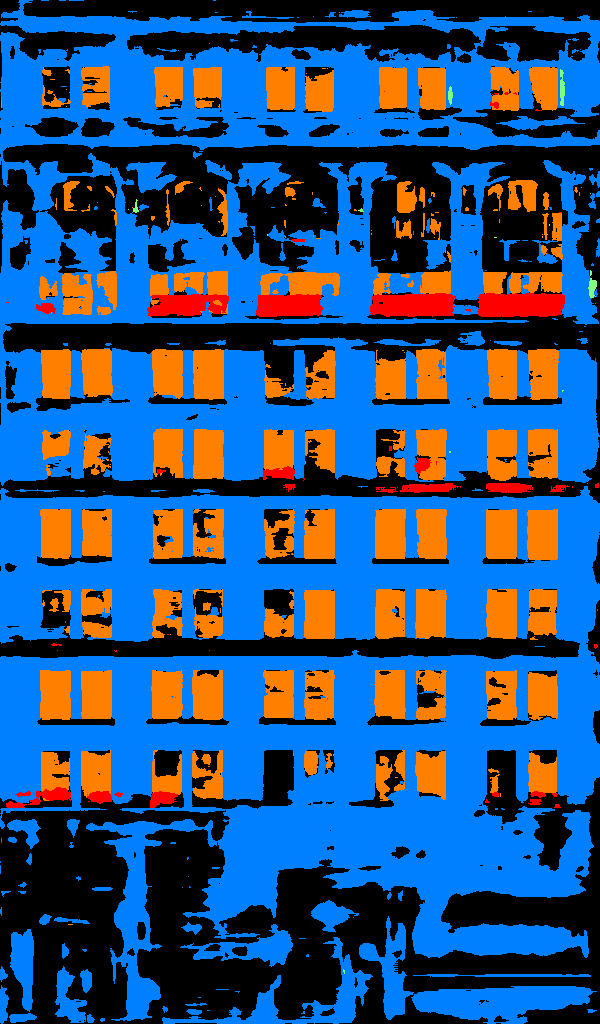
|