Project 5 - Image Warping and Mosaicing¶
Part A¶
For the first part of this project, I recitifed images according to a calculated homography matrix. I define at least 4 points of correspondence between two separate images. These correspondences are used to calcaluate the transform required to map one image's pixels to a desired form. We can formulate this as a least squares problem, aH = b. We want to get H in the form of the 3x3 matrix on the right side of the equation below.
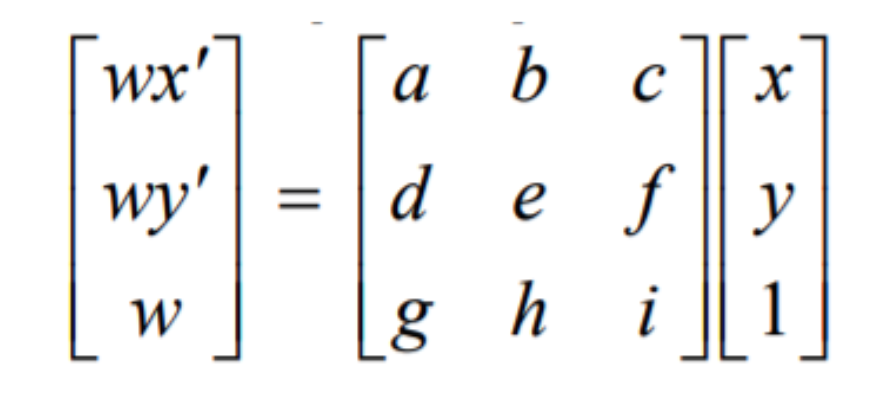
Here is the Least Squares formulation
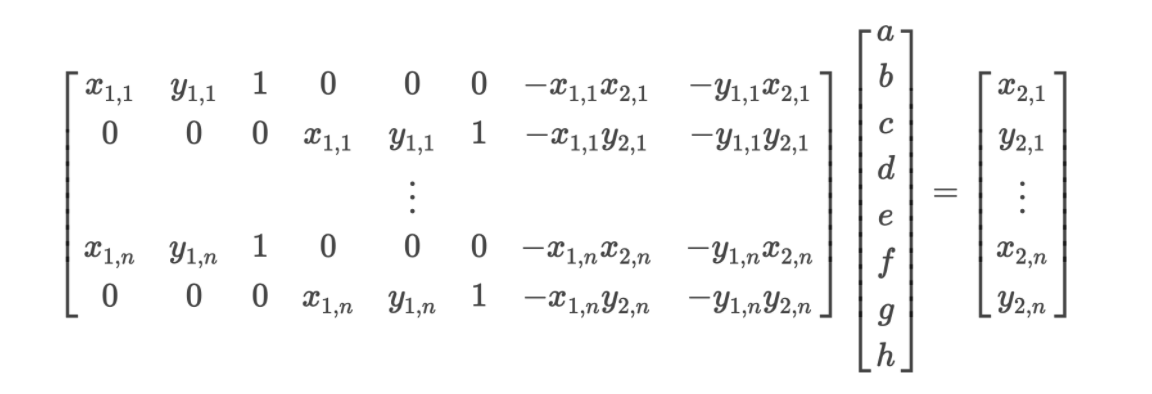
Image Rectification¶
Using a set of predefined rectangular points (the corners of the black and white rectangular image), the persepctive ipad photos are warped such that the ipad screen becomes frontal parallel. To do this, I calculated the homography matrix required to map the original corners points of my ipad to the corner points of the rectangle. Once I calculated H, I used it's inverse to transform my image to it's rectified form.
 |  |  |
 | |  |
2 Image Mosaics¶
Given two images that are taken from the same point of view but varied viewing angles, we can define correspondences between the overlapping regions of the photo to create a panorama. Similar to before, we choose one photo that will serve as the reference image, $\text{Image}_{r}$; the other image will be warped to this reference photo $\text{Image}_{w}$. Next, we manually define points of correspondence between the two images, calculate the homography transform matrix, and then warp $\text{Image}_{w}$ accordingly
 |  |
 |  |
Most of the difficulties that I encountered while making my mosaics were due to the fact that the lens on my phone camera causes a lot of warping/distortion near the edges of each photo. To combat this, when combining the two images in the overlapping regions, I gradually blended the left image into the right by a decreasing scaling factor $\alpha \in [0, 0.9]$. Once the highest $\alpha$ value of $0.9$ was attained, I only used the pixel values from the right, reference image.
Part B¶
Motivation¶
In part A of this project, we needed to manually define our points of correspondence. This, in many ways, can lead to the creation of suboptimal mosaics and panoramas: points that appear, to humans, as good points of correspondence might, in reality, be anything but. In part B, we explore methods that automatically define these correspondences. In this section, we implement the methods introduced in "Multi-Image Matching using Multi-Scaled Oriented Pathes" by Brown et al.
Harris Point Detector¶
The Harris Point Detector algorithm treats corners as the junction of two edges. Edges, in this algorithm, are regarded as areas with steep changes in image brightness. We display images with their Harris Corners overlaid.
 |  |
In the following images, we see the the same photos that were used in Part A to create mosaics with their harris corners overlaid.
 |  |
 |  |
Adaptive Non-Maximal Suppression¶
It is obvious to see that there are too many points of correspondence to be used efficiently and effectively. To handle this, we use Adaptive Non-Maximal Suppresion to limit the maximum number of near-uniformly distributed correspondence points extracted from each image. To ensure the aforementioned point property near-uniform distribution through the sorting of points via a non-maximal suppression radius. This, in effect, ensures that we sample intense harris corners (i.e. points with very marked edge junctions) across the image. The exact optimization problem looks as such
$$r_{i} = \min_{j} |x_{i} - x_{j}| s.t. f(x_{i}) < c_{\text{robust}} f(x_{j}), x_j \in \text{All interest points}$$$f(.)$ gives the harris corner intensity value for a given point. We used the tuned hyperparameter value of $c_{\text{robust}} = 0.9$ to ensure that a neighbor must have a significantly higher strength for suppresion to take place. Below are the same photos within 750 of the anms points chosen
 |  |
 |  |
Feature Extraction and Matching¶
With each of the identified feature points, we create feature patches which, ideally, are invariant and distinctive. As described in the paper, each of the feature points are selected as the center of a $40 \times 40$ grid of surrounding pixels. We then downsample this patch to an $8 \times 8$ grid which we then normalize. By normalizing, we negate the effect of any affine changes.
In order to find which of these feature patches match, we compute the squared distance between every feature pair and select probable matches based on David Lowe's similarity metric: if the ratio between the closest and next-closest match is less than 0.3-0.35, then, with a high degree of certainty, we can state we've found a match
RANSAC¶
Of all of our feature matches, which are the best? The RANdom SAmple Consensus method accomplished this work for us. The algorithm itself is a loop. During each iteration, it selects 4 feature pairs at random (4 features are needed in order to calculate the homography matrix). We then compute the homography and enumerate all inliers
$$ SSD(p_{i}^{'}, H p_i) \leq \epsilon$$In my implementation, I either stopped as soon as $\epsilon \times \text{num_features}$ were found or one million iterations were made
The results are included below (left) in comparison to the manually found panoramas from part A
 |  |
 |  |
As can be seen in the above results, the panoramas created by using RANSAC, unfortunately, did not turn out as nice as those created by myself. I believe this is largely due to the fact that my hyperparameter values for the algorithm weren't fine tuned enough. That said, RANSAC was able to find reasonable point of alignment that yielded passable panoramas
What I learned¶
Without a doubt, one of my least favorite parts of projects 3 and 5 was the process of manually selecting points of correspondence. Between cpselect always segfaulting on me to the lack of precision of the process, it was incredibly time-consuming and very very annoying. In this, I am very happy to see that a simple method like RANSAC is able to perform adequately with minimal tuning of my own. With better feature patches, high quality images (i.e. less lens distortion), I would expect RANSAC to perform much better. The most difficult part of this project was definitely finding good features; I could only find mediocre ones.