


CS194-26: Image Manipulation and Computational Photography Spring 2020
Here are some photographs that I took from the view of my hotel room in Oahu.



I chose these shots because the scenery is sufficiently far away that I can comfortably move the handheld camera while keeping it stationary enough.
I also used pictures of my sister’s closet, and my vacation photos from the top of Le’ahi, a famous hiking spot in Hawai’i.





For rectification, I took a picture of my bathroom, and used the provided facade image:


I implemented the function \(H\) as desired using matplotlib’s ginput. This allowed me to select correspondence points between two images like so:


We then use least-squares via the method described in lecture to solve for \(H\). See the bCourses code for implementation details.
We apply the solved-for homography to put the two images into the same perspective. This is done using inverse mapping. Each output pixel has its input location on the original image calculated, and then we sample appropriately to produce the final image:


(Of course, the top image is identical since we used it to define the transform that all other images transform into.)
We can also apply the above procedure to rectify images. We select correspondence points like so:

And then, we can compute the homography against a fixed grid to produce a rectified image:

Repeated with the facade input:

As an added touch, I implemented some anti-aliasing in the form of bilinear sampling. Here is a close-up comparison with (left) and without (right) anti-aliasing:


We can use the technique described in lecture (distance from edge + feathered masking) to produce a clean blend between the warped Oahu images to produce a final mosaic. (Here I use all 3 images:)

The most interesting thing I learned was this new way to conceptualized photographs. Photographs are 2D projections of pieces cut out of a “pencil of rays” centered around the camera’s optic center. For this reason, we can actually recompute new camera angles or combine multiple photos together as in a mosaic. This technique is incredibly powerful, and demonstrates the general usefulness of a full homography transform in image processing.
I used the sample Harris code with a threshold of \(t=0.02\) as described in the provided paper. This is the result applied to the oahu image:

To cull out low-interest points, I implement AMNS as described in the provided paper. I use \(c_{robust} = 0.9\) and \(n_{ip}=100\) for good results:
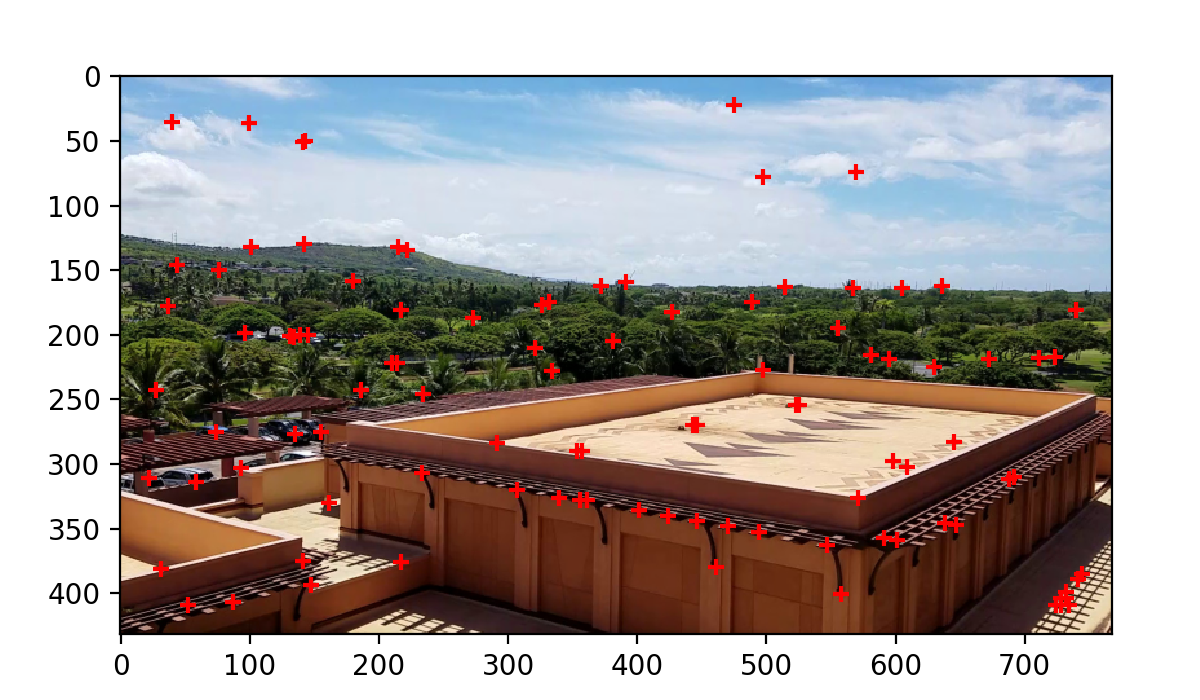
Following the spec, I extract 8x8x3-dimensional features from each of the interest points. This is done by sampling in a regular 8x8 grid over a 40x40 pixel area. These are the resulting features from the AMNS-filtered Harris points from the previous section:

(I found that including color improved match performance.)
To match between two images, I compute the \(e_{NN1}/e_{NN2}\) measure, and reject nearest-neighbor matches with a measure greater than \(0.5\), as described in the paper. Here are some visualized matches:
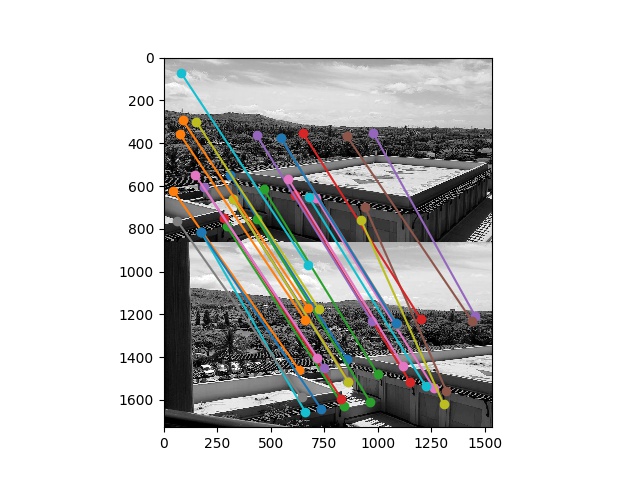
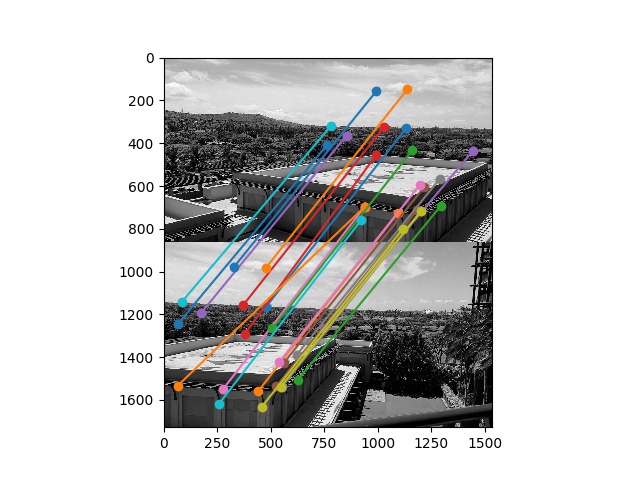
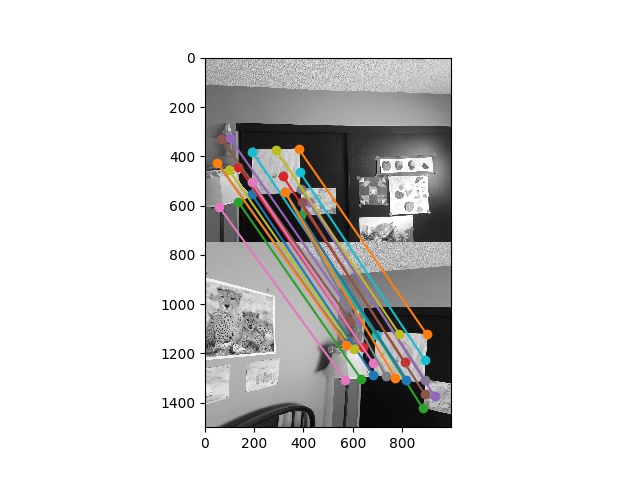
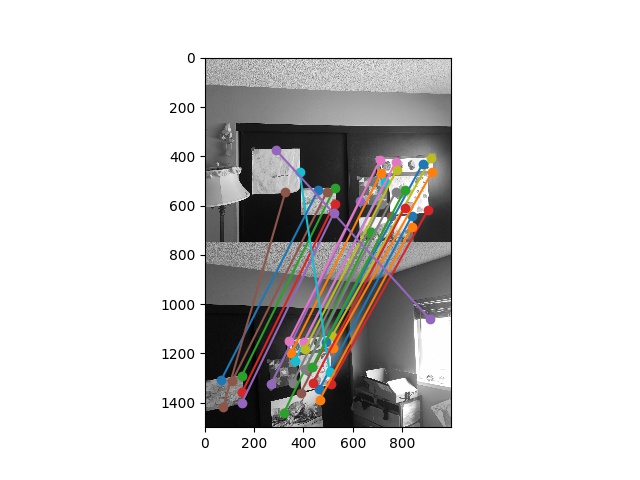
I implemented RANSAC as described in lecture. Inliers are defined as points that lie within \(10\) pixels of each other after the homography is applied. RANSAC runs for \(n=1000\) iterations.
Here are the same matches from before, but now with inliers in green and outliers in red:
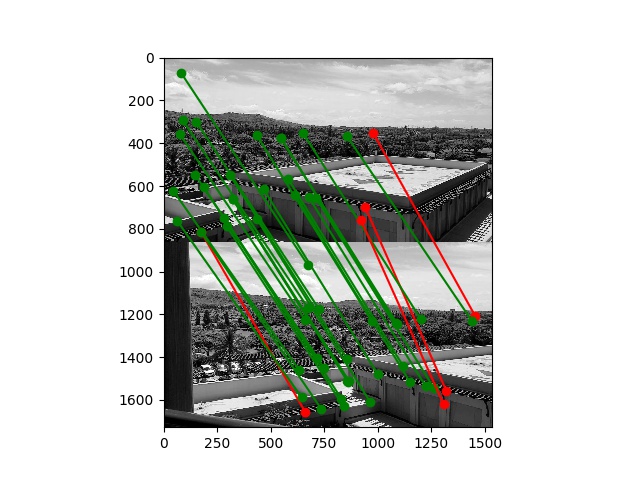
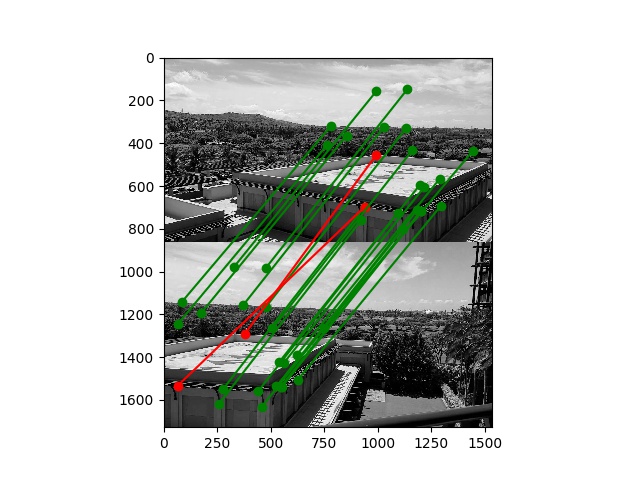
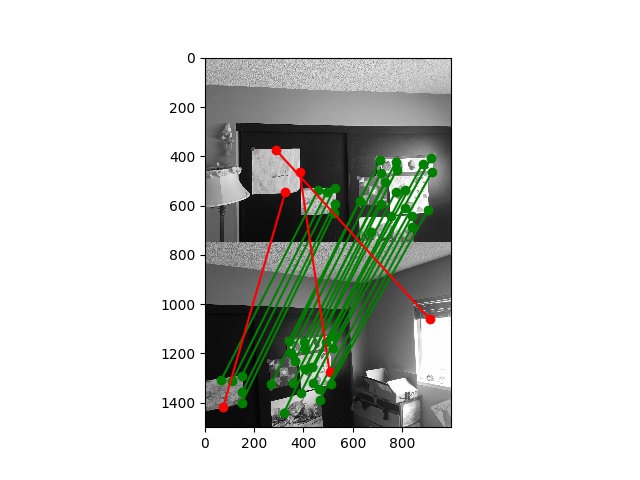
Here is a gallery of the final results using RANSAC and AMNS-filtered Harris correspondence points:

For comparison, here are the results from my hand-picked correspondences. Interestingly, the two do not agree exactly but both are reasonable panoramas. Top is hand-picked, bottom is the output of my algorithm:


I found the section on RANSAC to be particularly interesting. In some sense, it is a direct translation of what a human would attempt to do given the same task, and so its application is packed full of heuristics with few theoretical guarantees. However, it works surprisingly well in practice. I plan on using similar techniques for an ongoing research project I am a part of which stitches together images of the retina.
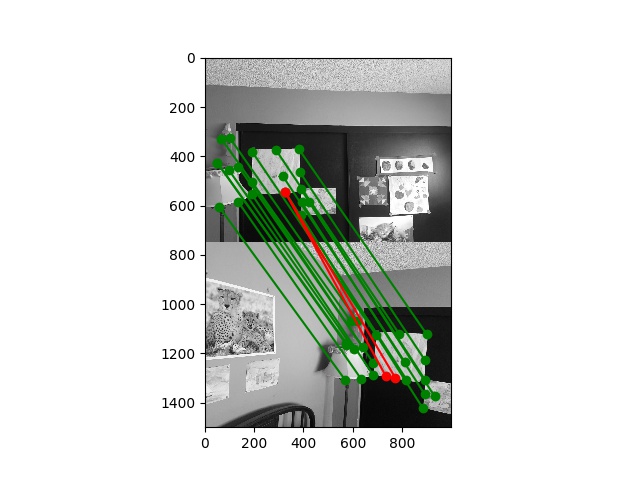
For fun, I also ran my algorithm on the staff-provided example images:

HTML theme for pandoc found here: https://gist.github.com/killercup/5917178