Final Projects: Seam Carving and Lightfield Camera
Steven Cao / cs194-26-adx / Final Project
Seam Carving
In this project, we'll be implementing the SIGGRAPH paper ``Seam Carving for Content-Aware Image Resizing'' by Avidan and Shamirsee. At a high level, the goal is to resize images by removing parts of the image that are not semantically important, rather than simply cropping the borders.
Methods
The method is simple: we can define an energy function that quantifies the importance of each pixel. Then, we can use dynamic programming to find the lowest energy seam, or path from one side to another, and remove the seam. Then, we can repeat until we reach the desired size. As our energy function, we will use the function $$ e(I) = \left| \frac{\partial}{\partial x} I \right| + \left| \frac{\partial}{\partial y} I \right|, $$ which represents the amount of change at the pixel.
Results
Below are some examples of resizing vertically or horizontally. First, let's look at some good results. The pictures are either my own, or from here or here.


















Next, let's look at a bad example, where I tried to resize a picture of me eating dim sum. The method cut away much of my face and hair, which is not desirable.



Conclusion
It's nice how such a simple method produces such nice results. It was interesting that the method worked worse for human faces, which suggests that the amount of change is not always the best measure of semantic importance.
Lightfield Camera
In this project, we'll be using lightfield camera images from the Stanford Light Field Archive to simulate refocusing and changing aperture. These images are taken over a grid perpendicular to the optical axis. By intelligently averaging and shifting, we can create cool effects.
Refocusing
When the imaging center moves, the nearby objects move a lot, while farwaway objects move less. Therefore, if we average all of the lightfield images, we will produce an image that is focused on faraway objects, while nearby objects will be blurry. Instead, if we shift the images around before averaging, we can focus on different points on the image.
Specifically, in our \(17\times 17\) grid of images, we can pick the image at \(8,8\) to be our center. Let its real-world coordinates be represented by \(x_c\). Then, for each of the other images, we can compute the displacement \(x - x_c\) and then shift the image by some multiple \(K * (x - x_c)\) of this displacement. By varying \(K\) from \(-1\) to \(1\), we can simulate different focuses. Below is the result:
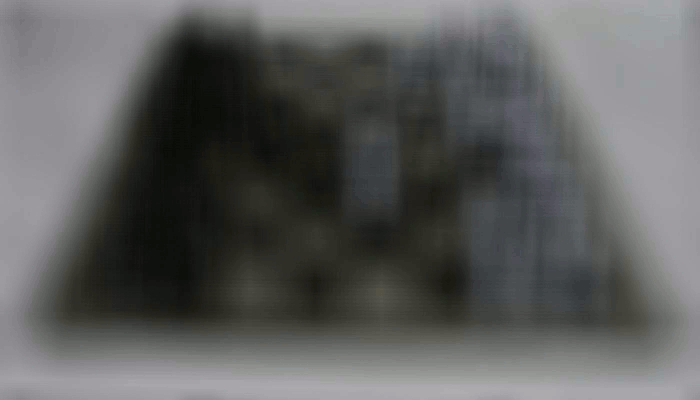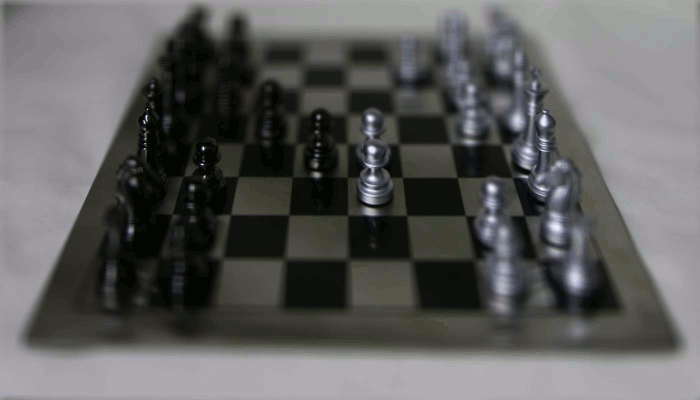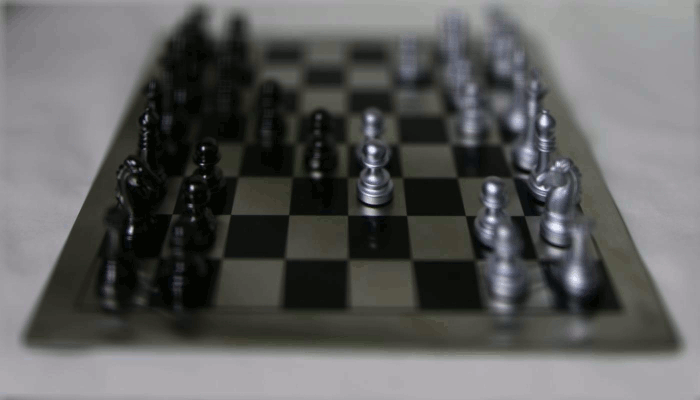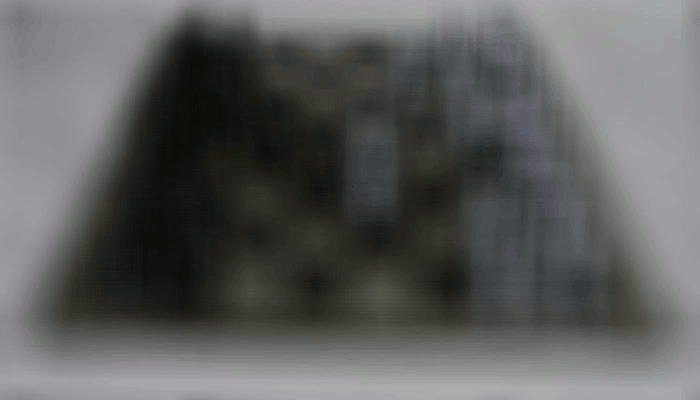
Aperture
We can also average intelligently to simulate smaller or larger apertures. Specifically, instead of averaging all of the images, we can average only those within some radius of the center image. By varying this radius between \(0\) and \(75\), we can simulate different apertures. Below is the result:

Conclusion
It was cool to see how we can use lightfield cameras to produce cool visual effects! This project also helped me understand cameras a little bit better.