Part 1: Seam Carving
Have you ever seen an image on the internet that you wanted to resize? I, for one, have come across several photos that I'd like to be my wallpaper, but they're too small! So they come up really grainy when they get blown up to fit the higher resolution. Or, what if you had a rectangular picture that you wanted to be square? Well, your computer will probably squeeze it and make it end up looking really weird.
In 2007, Shai Avidan and Ariel Shamir came up with a cool idea: what if, when resizing an image, you just remove certain parts of it until you get the size you want? Their key idea was their choice in parts that they removed: they chose to remove parts that were the least noticeable if removed, or as they put it, had the lowest energy. To ensure that things still looked ok they, they ensured that only a connected line of pixels could be removed; they referred to this as a "seam". Thus, their method became known as seam carving, and became immortalized in their seminal paper.
1.1 Seam Removal
In order to remove the seams, we first need to decide how to give "energy" to each pixel. The simplest choice is to simply use a Derivative filter on the image to grab the sharp edges, then take the magnitude of the resulting gradient. This is what they chose to use in the paper as a baseline. It is defined mathematically as:
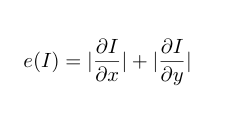
To figure out which seam to remove, we can utilize the following Dynamic Programming approach, where e(.,.) refers to the energy image, and E[i,j] holds the lowest seam energy (so far) that we can use to reach pixel (i,j) from the top:
- For the first row, E[i,j] = e[i,j]
- For all subsequent rows, E[i,j] = e[i,j] + min{E[i-1,j-1], E[i-1,j], E[i-1,j+1]}
- Once at the bottom, find the minimum value of E for the bottom row, this represents the ending point of the lowest energy seam.
- Backtrack in your path until you recover the seam.
Below, you can see an example of two different energy functions I used: the standard Derivative filter, and also the smoothed Derivative of Gaussians filter. Interestingly, you can see that the non-smoothed filter did better. Why? I think it's because removing seams creates unnatural edges, and smoothing allows us to ignore these. (Note the top of the left tower).
| Orignal Image | Derivative Filter | DoG Filter |
|---|---|---|

|

|

|
Below, you can see more results for other images.
| Orignal Image | Seam Carved |
|---|---|
|
|
|

|

|

|

|

|

|
|
|

|

|

|

|
1.2 Failures
Not all of the examples worked too well, If there's too much content along a certain direction and we choose to carve that way, it is forced to remove some important information, leaving us with weird looking pictures.
| Orignal Image | Seam Carved |
|---|---|

|

|
|
|
|

|

|
1.3 Seam Insertion
What if we want to increase the resolution? Well, we can just reverse the process of carving. Say we want to increase the resolution by n. All we have to do is find the first n seams we would normally remove, and instead of removing them, add them back to the image. But this would create stretches of repetitive pixels, so instead, we place a new seam in the place of the supposed-to-be-removed one, shift the pixels it overrides to the right, then set its value to be the average of the seams on either side of it.
Below, you can see an example of where I extended some images:
| Orignal Image | Seam Inserted |
|---|---|
|
|

|
|
|

|
|
|

|
1.4 Deleting Objects
We can actually leverage these two tools now to delete objects from a photo! To do this, we now take in a mask over the part of the image we wish to delete. Then, we aritifically drive the energy values for that area to negative infinity, and then do seam carving for the width of the mask number of iterations. The artifically negative values will force seam carving to delete what we want. Then, to get it back to normal, we just do seam insertion back to the original resolution!
Here are some examples of deletion. As you can see, for something small like the man, it works nicely, but for large parts of the image, it doesn't work as nice as it creates harsh edges
| Man Removed | Flower Removed |
|---|---|

|

|






















