

In this project, I implemented content-aware image resizing by seam carving. The gist of the approach is that we assign each pixel in the image an energy value, and then we iteratively remove the lowest energy "seam" from the image until we reach our desired size. A seam is simply an connected path of pixels through the image (can be horizontal or vertical) such that each row has one element of the path and each consecutive element is directly adjacent to its neighbors.
The choice of energy function is pretty important, and changes the results considerably. I stuck with a simple Sobel filter which has higher activations near edges. For computing the lowest energy seam, I used dynamic programming.
The approach is pretty straightforward, so here are some results.
Here we shrank the image vertically to remove most of the background and preserve the region of interest -- the mural.


Here we shrank the image horizontally to remove some of the sky background.


Here we shrank the image vertically to preserve the texture of the cliff.


Here we trim the image horizontally, which primarily removes empty ocean instead of the island which we probably care more about here.


Here we remove a bunch of empty space so we can focus on Keanu's headshot.


Here we get rid of most of the distracting sky so we can emphasize the wall.

Here's a failure case on the same image, where we see some artifacts from seam carving.
In this project, I implemented the paper "A Neural Algorithm of Artistic Style". By extracting learned style and content representations of images using CNNs, we can separate and recombine content and style of arbitrary images.
When we process an image using a CNN, the layer activations in the lower levels of the network capture the more fine-grained details within the image (e.g. exact pixel values) whereas the higher levels capture high-level content (e.g. the presence of objects and their arrangement). If we treat the pixel values of an image as our parameters and consider a pretrained CNN, we can attempt to reconstruct images by optimizing over our set of pixel values to match the layer activations of a target image that has been fed through the network. In practice, we can simply use the MSE to obtain a loss function. The layers from which we capture these activations will determine the coarseness of our reconstruction.
On the other hand, we also care about style construction. The paper uses a feature space originally designed for capturing texture information. It uses correlations between filter responses over the image, which allows us to keep information about the texture of the image without keeping the global arrangement. Specifically, we take the activations from a conv layer and flatten the vertical/horizontal dimensions (preserving the batch dimension). Then, we compute a Graham matrix which captures the correlations between each pairwise filter map. Just as in the content construction, we use this matrix as our target and compute the loss using MSE. The depth at which we choose to construct features will change the coarseness of those features.
The key finding of the paper is that we can separate the content/style representations and recombine them to create cool hybrid images. To do this, we combine the losses we'd use for both style and content constructions (with some re-weighting to prioritize either content or style reconstruction). Below is the architecture I used.
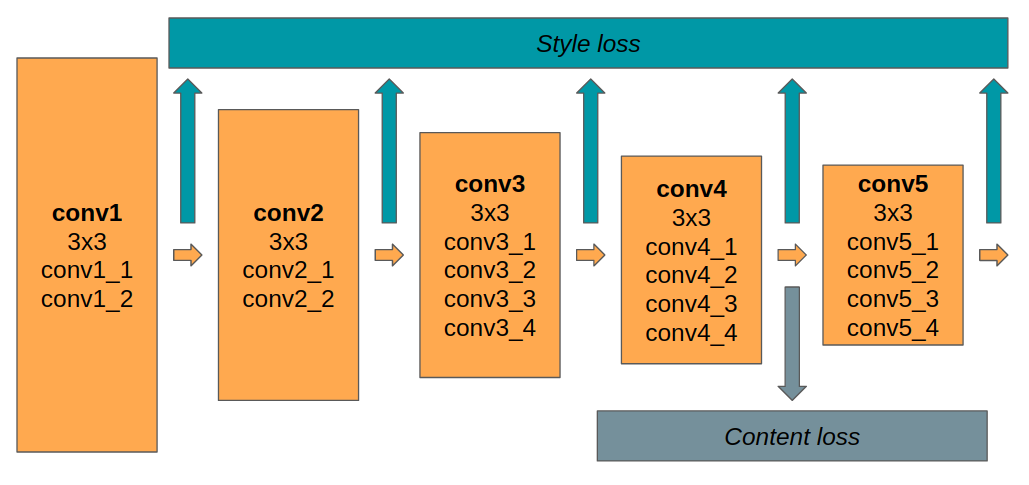
Borrowing from the paper, I started with a pretrained VGG-19 and used activations from conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1 for the style loss and activations from conv4_1 for the content loss. While the paper used SGD, I used Adam with a learning rate of .01. Another area where I differed from the original paper is in the reweighting between content and style loss. Whereas the paper used 1e-3 and 1e-4 as the ratio between content and style loss respectively, I found that those ratios were to large to allow for adequate minimization of style loss. Instead, I used 1e-5 throughout all of my experiments.
With all that, here are some of my results. This is the photograph of the Neckarfront used in the paper.

Here's the image stylized with some of the paintings used in the paper.






The images all seem to bear a much closer resemblance to the original content image compared to the results in the paper. Part of this is likely because in my case, I didn't normalize the images to the statistics of the style image, but instead to some other constant values.
I also stylized the Neckarfront with some other styles I thought might be interesting.






I also tried stylizing this photo of the Campanile I found online.



Here's some other combinations I tried that I thought looked cool.




I noticed that the approach generally didn't produce interesting results when trying to stylize a photograph with another photograph, particularly if the other photograph doesn't really have a cohesive theme or color scheme. The result mostly comes out looking sort of blurry and/or deep-fried.

Other times, training would simply collapse entirely if left training for too long. Here's an example from above when I stylized the Neckarfront as the inkwash painting.

In the first project, it was interesting to see how easy it is to manipulate images in non-obvious ways. In the second project, this was my first time training a network in PyTorch that wasn't particularly conventional, i.e. a feedforward network with cross-entropy loss at the end. Learning to embed losses in specific layers was interesting and taught me a lot about PyTorch and backprop.