Final project: A Neural Transformation of Sketches


Zhi Chen cs194-26-afa
Abstract
In our work, we addressed a completely new task that combines generative modeling of sketches and the interaction between text and sketches. We intend to explore language descriptions that correlate and translate between sketches and build an ML system that transforms sketched objects based on stylistic and content text descriptions, such as ‘Make the branch of a tree taller’. We developed four methods with different neural network architectures: latent vector transformation, sketch to sketch transformation using CNN encoder - CNN decoder, CNN encoder - RNN decoder, and RNN encoder - RNN decoder. With all models manually evaluated by volunteers and an inception model, we conclude the second version of RNN encoder - RNN decoder achieves the best result.
Data collection
We created an application to conduct sketch comparison tasks. In each comparison, we displayed a randomly sampled tree sketch pair to a participant. All sketches were scaled individually to have relatively the same size during display. Then we ask the participant to give instructions needed to transform the sketch on the left to the sketch on the right in English (eg. “Make the trunk of the tree taller and leaves rounder”). We put the application on Amazon Mechanical Turk and collected 20023 responses in total.
Data filter
Since we could not easily monitor the user inputs on Amazon Mechanical Turk, the raw dataset is really noisy. Here are some examples that are not suitable to fit in our model.

Some samples that are not suitable to fit in our models.
We designed a filter in order to clean the dataset. We filtered out the descriptions that are too short, the descriptions that contain word that is highly repeated and descriptions that are repeated too many times in all responses.

Methodology - latent vector transformation
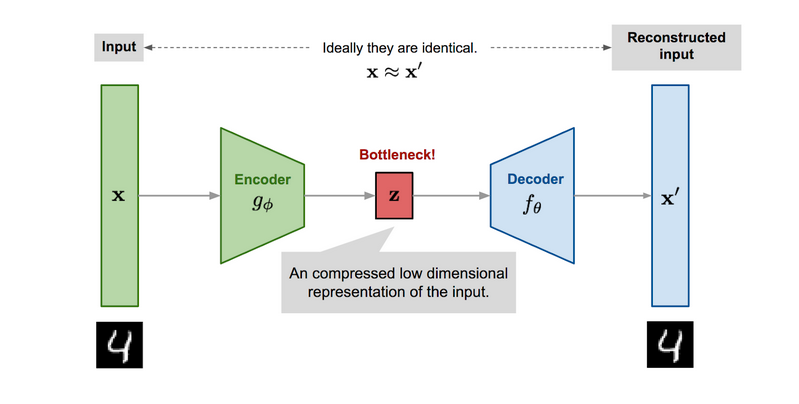
In previous research, a network named Sketch-RNN has been mentioned. This picture shows the architecture of Sketch-RNN. It can transform a sketch to another sketch which can be classified under the same label. The advantage of this network is that it can project a sketch into its latent vector z one to one and the latent vector z has much smaller size than the original input. So if we use the latent vector, the speed of training will increase. Also, in the transformation process in latent space, there will be less noise.
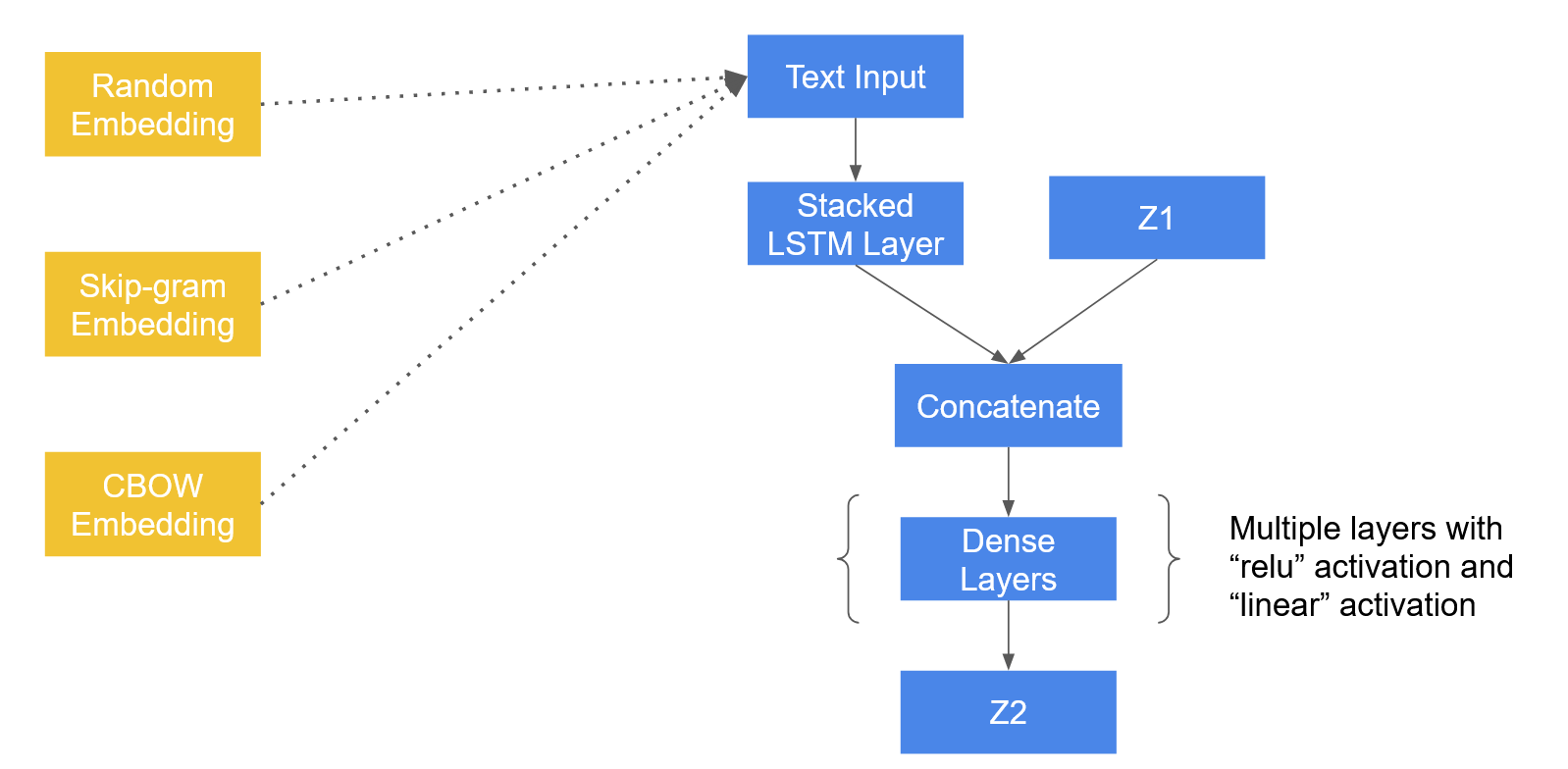
Here is the architecture of latent vector transformation model.
We decided to use LSTM layers to help our model to learn the sequential relationship in the text input. Since we do not know if there is sequential relationship in the latent space, we directly concatenate the latent vector with the output of LSTM layers.
Result
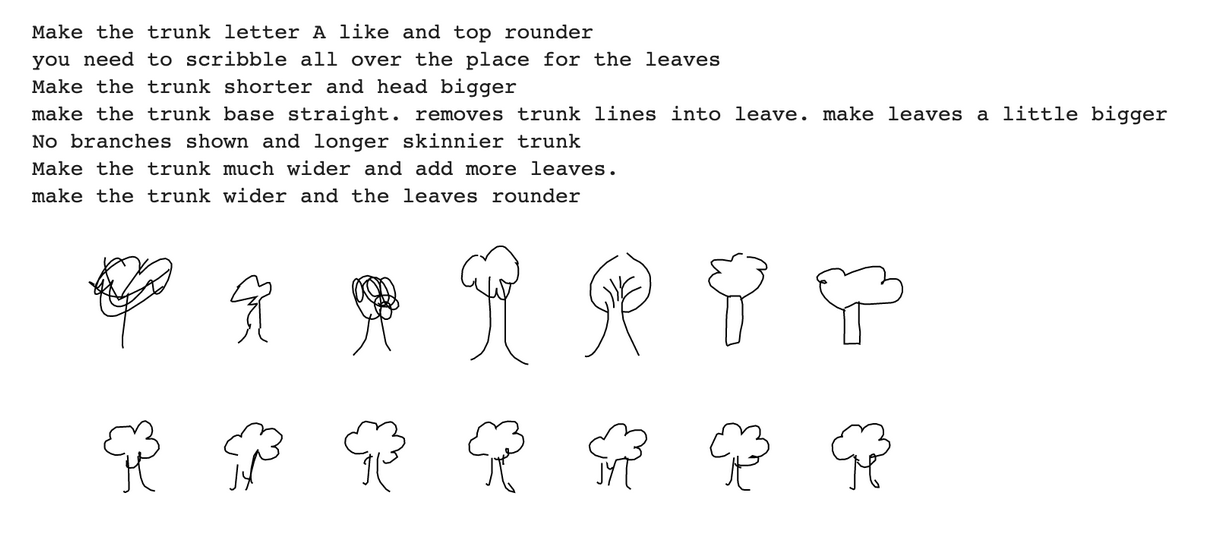
Above are some examples generated by the model. (The first sentence corresponds to the first colunm of trees. Top tree is the original sketch and the bottom tree is the predicted one.)
First, we figure out different word embeddings lead to almost same loss and result.
Second, the result of the model are really similar and some of them shows the effect of description.
Methodology - CNN to CNN model
Here is the architecture of CNN to CNN model.
We use CNN model as the encoder and also use CNN model as decoder. To make use of CNN model, we first transform the strokes of sketches into pixels of sketches and then fit into this model.
Result
Above are some examples generated by the model.
First, the result of the model are really similar and some of them shows the effect of description.
Second, with close comparison, we found that pattern in deep color and pattern in light color may be the most valuable things that this model learned. If add a certain threshold, the result should be better.
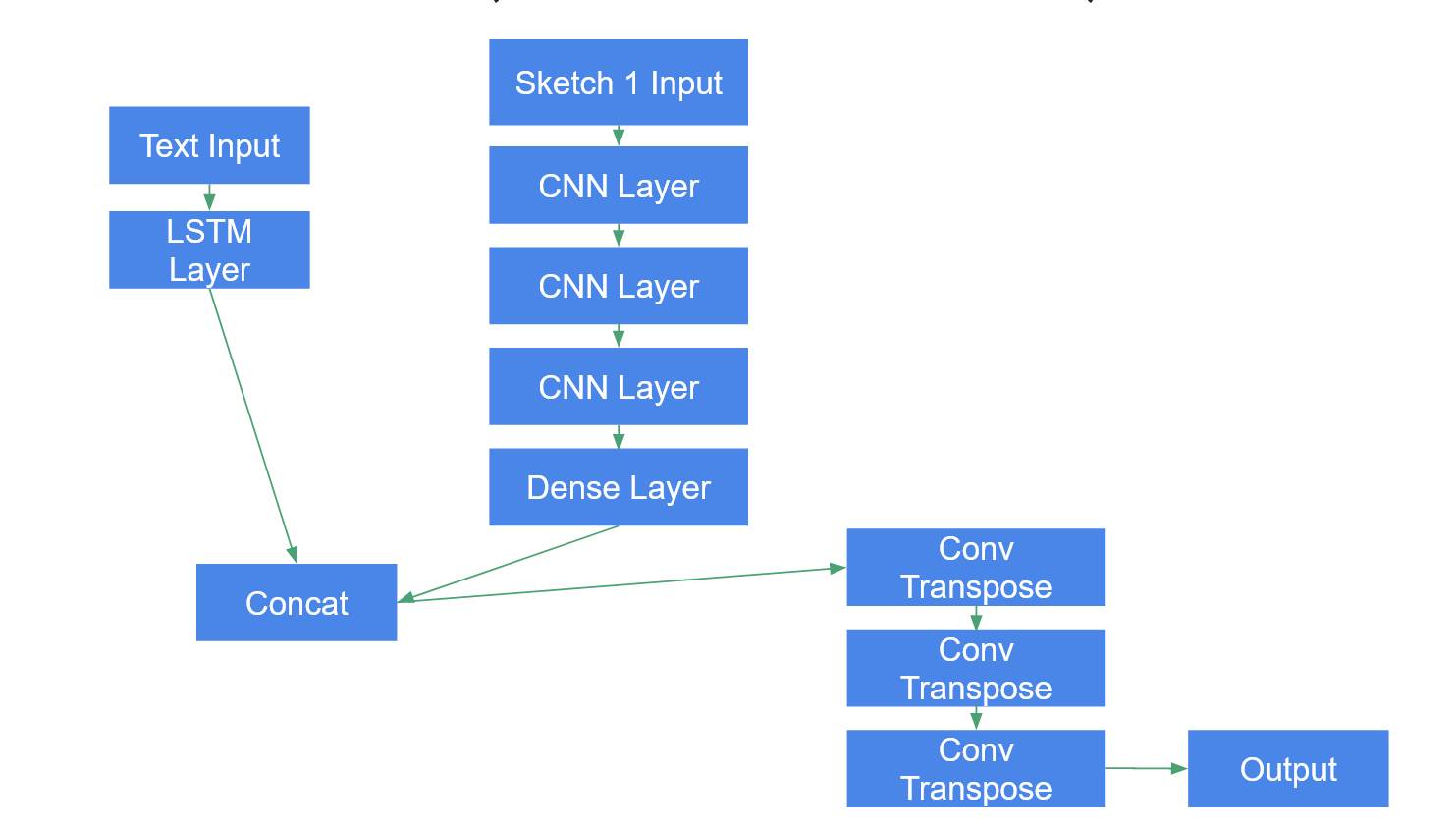

Methodology - CNN to RNN model
Here is the architecture of CNN to RNN model.
We use CNN model as the encoder and also use RNN model as decoder. We use the hidden state from text LSTM layers to concatenate with the output of CNN encoder.
Result
Above are some examples generated by the model.
First, the outputs contain many strokes that make the prediction really messy and many of them cannot be classified as trees.
Second, in some cases, it really shows that the model tries to predict according to the descriptions.
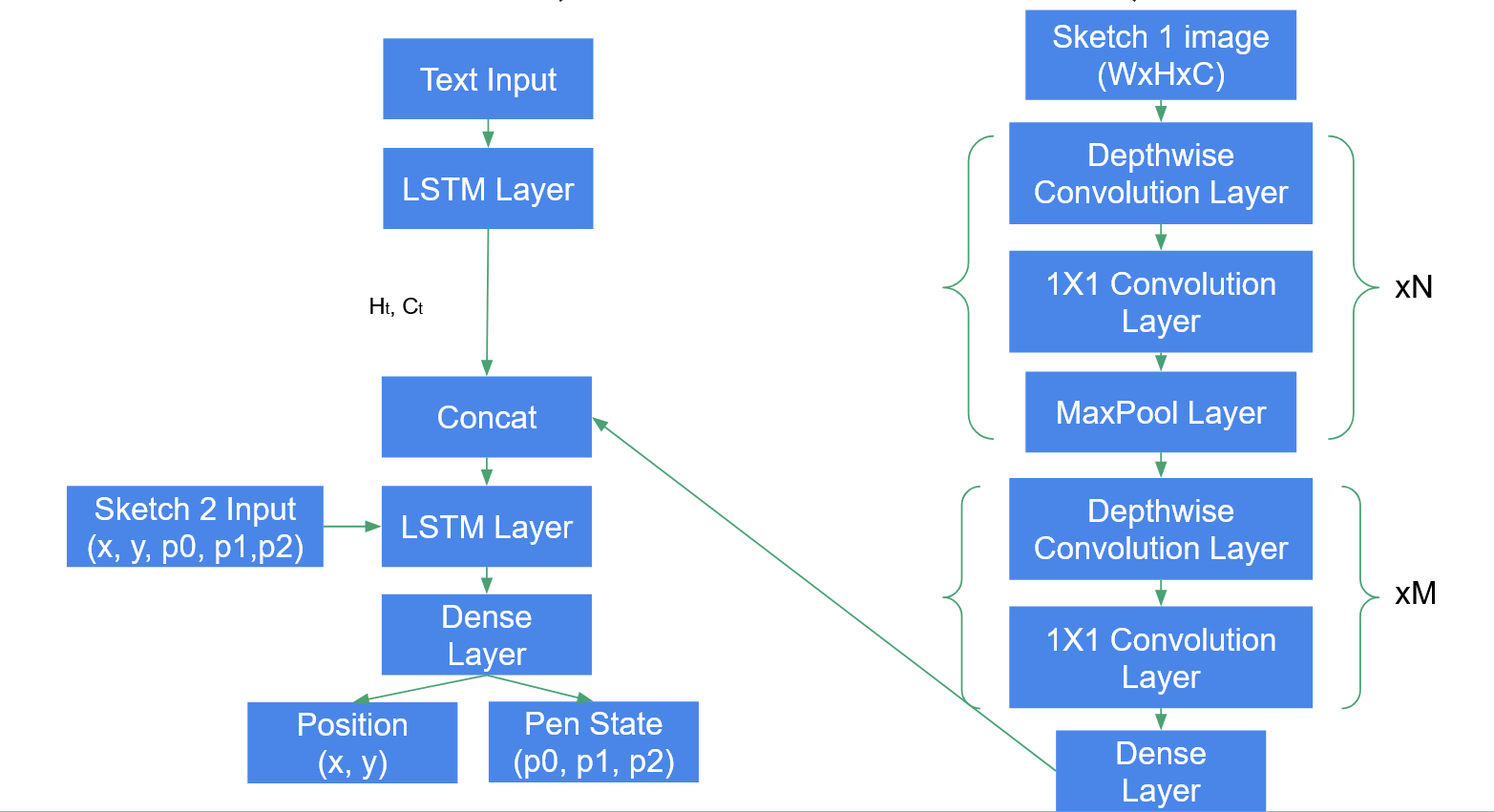
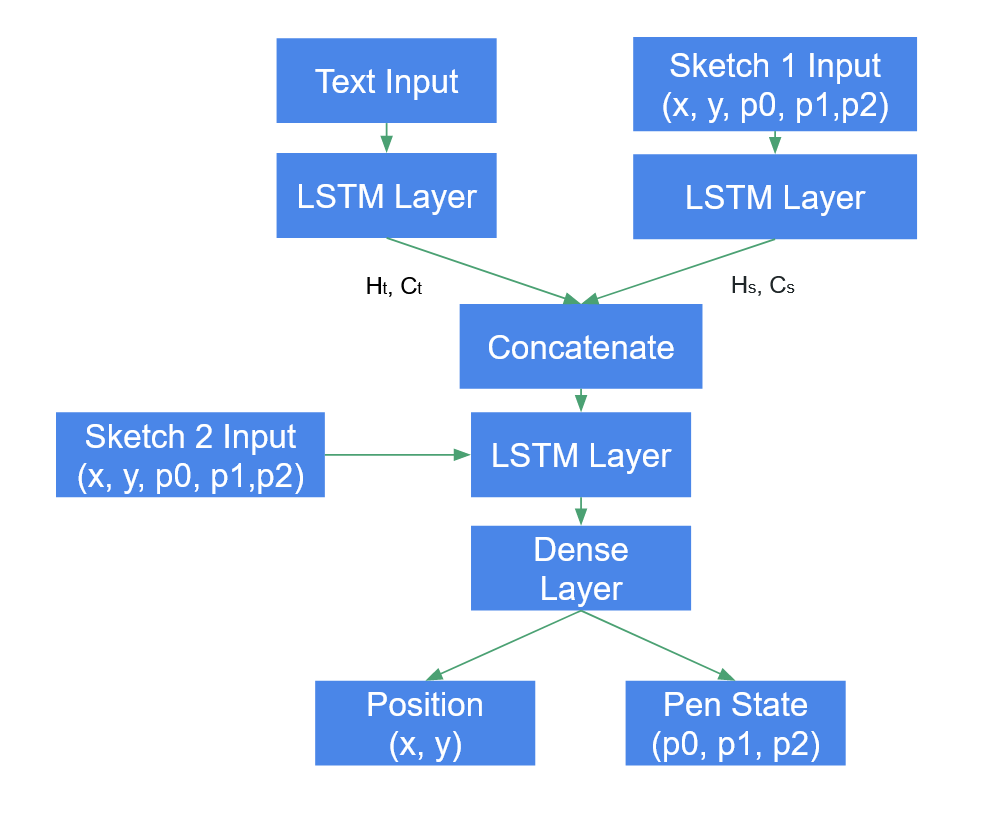
Methodology - RNN to RNN model
Here is the architecture of RNN to RNN model.
We use RNN model as the encoder and also use RNN model as decoder. We use the hidden state from both text LSTM layers and stroke LSTM layers to concatenate with the input stroke of target sketches.
Result
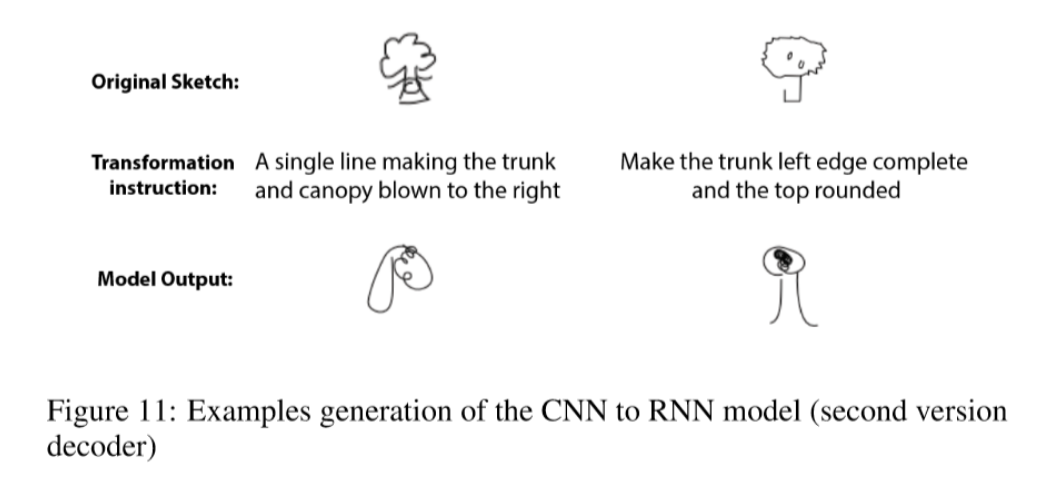
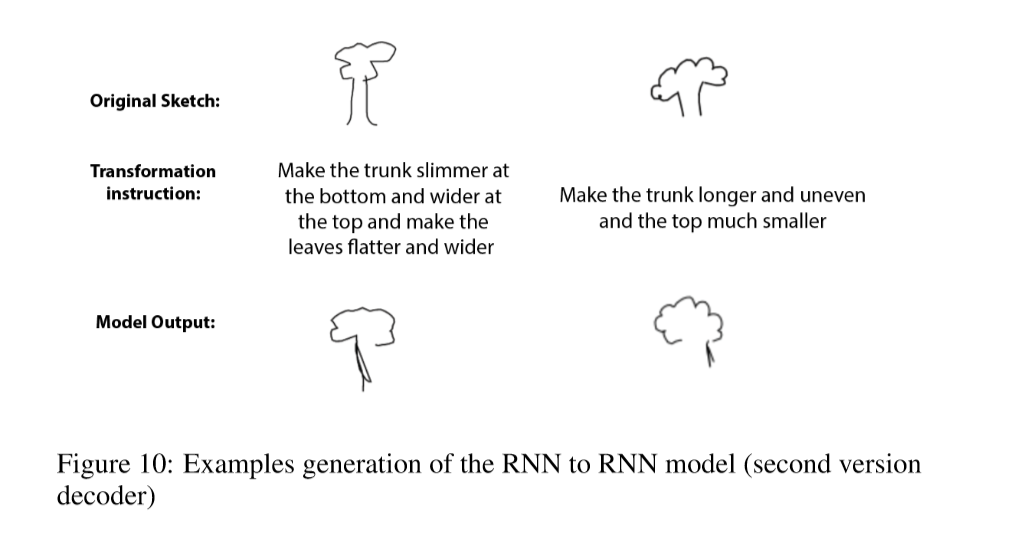
Above are some examples generated by the model.
This is the best model we produced. Although it sometimes cannot draw a full tree like human, it really tries to generate new sketches according to the descriptions.
User evaluation
It's really hard to evaluate our models because machines cannot tell you whether or not a newly generated sketch is good or not.
So we randomly sampled 52 sketch and text pairs from our testing data and ran them using the following four models: CNN-CNN model without dense layer, CNN-RNN model, RNN-RNN model version 1 & 2. In total, we generated 208 sketches. 17 users in total were asked to evaluate the 208 generated sketches by answering the following questions: From a score of 1 - 5, how well do you think the transformation did? This question is used to evaluate how well our model transforms the sketch under human perception.
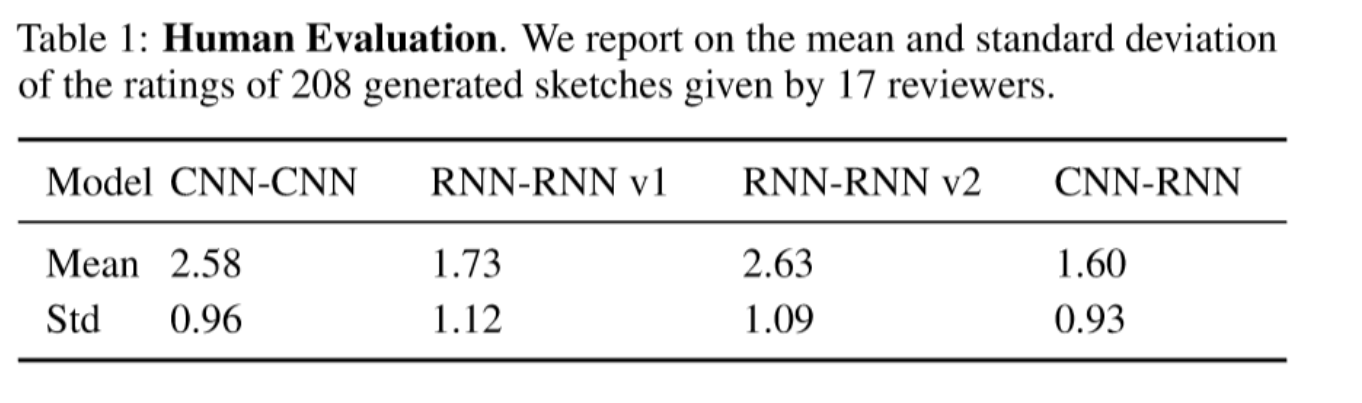
The second version of the RNN-RNN model and the CNN-CNN model received the highest score, though scores received by all models are not high. All of our models also have relatively large standard deviation, which implies the output quality is not consistent.
Conclusion
In this work, we explored different methods to transform one sketch to another sketch given text description that guides the transformation. We used two evaluation methods to assess our model. User evaluation mainly shows whether the generated sketch is tailored to the textual description, and inception model evaluation mainly shows whether the generated sketch looks like an object (in our experiment, the object is a tree). Given both user and inception model evaluation results, we concluded that the model using both RNN as encoder and decoder, and predicts the transformed sketch at a single time step, achieves the best performance. However, the average scores overall are not very high and the standard deviations are a bit large, which implies that there is still much room for improvement. The architectures of our models are relatively simple, and therefore may not capture all features of the sketch and text. A more complex model architecture will probably do better. By using different approaches to solve this unexplored task, we hope to encourage people to explore further on this new idea, and thus develop better methods to solve it.

Above are some examples we collected. (The first sentence corresponds to the first colunm of trees. Top tree is the original sketch and the bottom tree is the target tree)