Logic Programming
Logic programming: our last programming paradigm. Rather than telling the computer what to do, here we just tell the computer things that are true, then ask it questions. It does this using a very unintelligent algorithm called unification, which takes two pair structures, possibly with variables in them, and figures out what the variables have to be to make the two patterns the same.
Our query system often trips people up because it's not like Scheme—you don't "call functions", and rule-matching doesn't nest. On the other hand, it still uses lists (and pairs, and dotted-tail notation). But all it does is pattern matching.
In our query system, you use assert! to tell the system new facts, whether they're just plain assertions like (brian likes potstickers) or rules like (rule (same ?x ?x)). Anything else is a query.
-
Before we really get into things, you should understand the basics. How can you write a query system rule for
car? How many "inputs" should it have?(I don't want to call them "arguments" because they're not. We're not writing functions, we're writing relations. Remember, the only thing the query system knows how to do is unification.)
(rule (car (?the-car . ?the-cdr) ?the-car))
This example shows the power of the query system. Without using a single Scheme function, without even using a condition, we've described a relation between two things. "The car of this pair
(?the-car . ?the-cdr)is?the-car". Pretty straightforward once you're used to it!
Unification
At the core of the query system is an algorithm called unification. Unification is the act of taking in two patterns (pair structures that may or may not have variables) and assigning bindings to the variables so that the structures are equivalent. What you get back is either a list of bindings (variable-value pairs), or some placeholder saying it's impossible to unify these two. The basic algorithm is something like this:
- If both items are words, see if they're equal.
- If both items are pairs, unify the cars, then unify the cdrs.
- If one item is a pair and the other is a word, the unification fails.
There's also plenty of code to handle variables, but the basic idea is here.
The best way to think about unification is as the query system taking two box-and-pointer diagrams, placing them on top of each other, and seeing where things match up.
In this example, we end up with the following bindings:
?a <=> jordy ?b <=> (jay) ?c <=> brian
Unification can fail whenever we'd try to do something inconsistent. Sometimes that's because we get a pair in one case but a word in another. Other times it's because we get variables that would need two different bindings. Still other times we get two words that don't match.
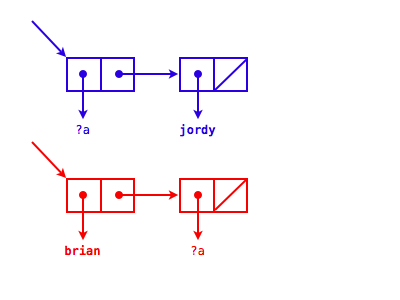
The algorithm starts by matching the cars, so ?a gets set to brian. When we get to the cadrs, we have a problem...so the unification fails.
Can you unify (find bindings for) the following pairs of query system patterns?
-
(brian . ?a)and(?b jordy jay)Starting with the cars, we learn that
?bmust bebrian. When we move to the cdr, we're trying to unify a variable and a pair. There's no problem here either, so the value of?ais the list(jordy jay).You can check your answers; if you
consbrianand(jordy jay), you get(brian jordy jay). And if you replace?bwithbrian, you also get(brian jordy jay). So these bindings do indeed make the two patterns equivalent. -
(?a brian ?b)and(?b ?c (?c))Starting with the cars doesn't tell us much this time, only that
?aand?bare the same. When we get to the cadrs, however, we learn something useful:?cmust bebrian. It's when we get to the caddrs that things become interesting.Like the example above, we're matching the variable
?bwith a one-element list. This time, that list has a variable in it:?c. But we know what?cis; it'sbrian. So?bis the list(brian).From there, we get that
?ais also the list(brian), and the unified patterns come out to((brian) brian (brian)).It's worth noting that not all variables have to get a value. If we were unifying
(?a brian ?b)and(?a brian (?c)), our answer would have an?astill in it at the end. This means you can put anything in that slot and the unification will still work; for the query system, it means the relation will still be true no matter what that variable is. -
(?a brian ?b)and(jordy ?c . jay)Hm. We can get the car and cadr pretty easily, but then we get into trouble. Let's take a look at the box-and-pointer diagrams for these two patterns.
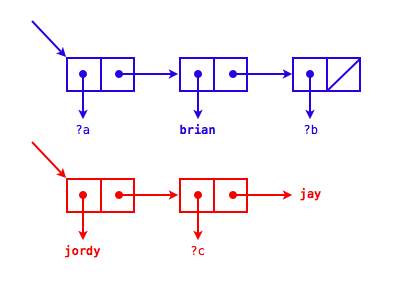
If we look at it this way, it's pretty easy to tell what's going wrong! If we take the
cddrof the first input, we get to a pair (the one whose car is?b). But thecddrof the second input is a word—not a variable, just a plain old word. A pair and a word are definitely not the same, so the unification fails.
Writing Query System Rules
If you wanted to ask for the third element of a list, you can't do this:
(car (cdr (cdr ?lst))) ; bad!
Instead, remember that a query system rule is more like a predicate, checking whether or not a relation holds. To see if ?three is the third element of ?lst, you'd have to do something like this:
(rule (caddr ?lst ?three)
(and (cdr ?lst ?cdr)
(cdr ?cdr ?cddr)
(car ?cddr ?three) ))
This is a lot like a hypothetical Scheme predicate function caddr?:
(define (caddr? lst three) (let ((the-cdr (cdr lst))) (let ((the-cddr (cdr cdr))) (equal? (car the-cddr) three) )))
Note that instead of returning #t or #f, a query system rule just says what has to be true in the correct case. The query system also has much more compact ways of representing relations between pair structures; we could write the caddr rule like this:
(rule (caddr (?car ?cadr ?caddr . ?rest) ?caddr))
In this rule, there are no conditions, but the rule itself will only match if the first "input" is a list that's at least three elements long. There's no need to actually "chain" the operations like we do in the Scheme-predicate-based version.
-
Using this knowledge, can you write the
memberrelation?> (member ?x (1 2 3)) (member 1 (1 2 3)) (member 2 (1 2 3)) (member 3 (1 2 3))
(rule (member ?item (?item . ?rest))) (rule (member ?item (?first . ?rest)) (member ?item ?rest) )This is a pretty straightforward relation. To understand what it's saying, we can translate the rules into pseudo-English:
- "It is a
rulethat any?itemis amemberof (a list whose car is that?item)" - "It is a
rulethat any?itemis amemberof (a list whose car is?firstand whose cdr is?rest) if that?itemis amemberof the?rest"
Both of these are true statements, and it turns out they tell us everything about the
memberrelation.Some people might be worried that we're missing a case for when we've "reached" the end of the list, and the item is not there. But in that case the query system will just not find a match and not print an answer, which is what we'd want to do anyway.
- "It is a
-
Harder: write a query system version of
map. Remember that the query system doesn't apply functions...it just does unification. Use that to your advantage!> (login jordy ?what) (login jordy cs61a-tg) > (map login (aditi jordy) ?who) (map login (aditi jordy) (cs61a-th cs61a-tg)) > (map login ?who (cs61a-th cs61a-tg)) (map login (aditi jordy) (cs61a-th cs61a-tg))
(rule (map ?relation () ()) (rule (map ?relation (?l-car . ?l-cdr) (?r-car . ?r-cdr)) (and (?relation ?l-car ?r-car) (map ?relation ?l-cdr ?r-cdr) ))The trick for this one was in the second rule: realizing that you can use a variable for a relation. Remember, the query system only does pattern-matching, and that applies to all parts of an input, including the first item! In fact, we know this: in lecture, we had facts like
(brian likes potstickers)with the relation in the middle.The other part here was remembering how to break the two lists into cars and cdrs, and dealing with each half separately.
The really cool thing this does is you can give it two things and have the system figure out how they're related. Using our Simpsons example again:
> (?how marge bart) (parent marge bart) > (map ?what (abe marge) (homer bart)) (map parent (abe marge) (homer bart))
There's one last thing to note: not.
The query system treats not specially. For a normal query, and for the or special form, the query system will try to come up with any possible bindings that satisfy the query. For and, it will first come up with bindings, then use the remaining queries to throw out any answers that don't match. It's a lot like using filter (and indeed, it uses stream-filter in the implementation).
not is special because theoretically there are an infinite number of possible matches. If I ask (brian likes ?what), the query system only knows (brian likes potstickers) and (brian likes (ice cream)). But if I say (not (brian likes ?what)), I can't really get everything Brian doesn't like. All three of these would be possible answers:
(not (brian likes cheese)) (not (brian likes (the beatles))) (not (brian likes (1 2 3 4 5 6 7 8 9 10)))
Which are true, false, and somewhat nonsensical, in that order.
Consequently, the query system uses what's called an open-world assumption (you don't have to know that term), which means that it won't say anything it isn't sure about. That means that if you just ask a query with not, you won't get any results back! The same goes for an and with a not as the first clause.
Actually the same thing applies to lisp-value, since the query system has no idea what Scheme procedure you're going to use. But we don't use that very much.
Back to Jordy's home page | Course home page