Lab 5: Python Lists, Trees
Due by 11:59pm on Friday, July 10.
Starter Files
Download lab05.zip. Inside the archive, you will find starter files for the questions in this lab, along with a copy of the Ok autograder.
Submission
By the end of this lab, you should have submitted the lab with
python3 ok --submit. You may submit more than once before the
deadline; only the final submission will be graded.
Check that you have successfully submitted your code on
okpy.org.
Topics
Consult this section if you need a refresher on the material for this lab. It's okay to skip directly to the questions and refer back here should you get stuck.
List Comprehensions
List comprehensions are a compact and powerful way of creating new lists out of sequences. The general syntax for a list comprehension is the following:
[<expression> for <element> in <sequence> if <conditional>]The syntax is designed to read like English: "Compute the expression for each element in the sequence if the conditional is true for that element."
Let's see it in action:
>>> [i**2 for i in [1, 2, 3, 4] if i % 2 == 0]
[4, 16]Here, for each element i in [1, 2, 3, 4] that satisfies i % 2 == 0, we
evaluate the expression i**2 and insert the resulting values into a new list.
In other words, this list comprehension will create a new list that contains
the square of each of the even elements of the original list.
If we were to write this using a for statement, it would look like this:
>>> lst = []
>>> for i in [1, 2, 3, 4]:
... if i % 2 == 0:
... lst = lst + [i**2]
>>> lst
[4, 16]Note: The
ifclause in a list comprehension is optional. For example, you can just say:>>> [i**2 for i in [1, 2, 3, 4]] [1, 4, 9, 16]
Trees
A tree is a data structure that represents a hierarchy of information. A file system is a good example of a tree structure. For example, within your cs61a folder, you have folders separating your projects, lab assignments, and homework. The next level is folders that separate different assignments, hw01, lab01, hog, etc., and inside those are the files themselves, including the starter files and ok. Below is an incomplete diagram of what your cs61a directory might look like.
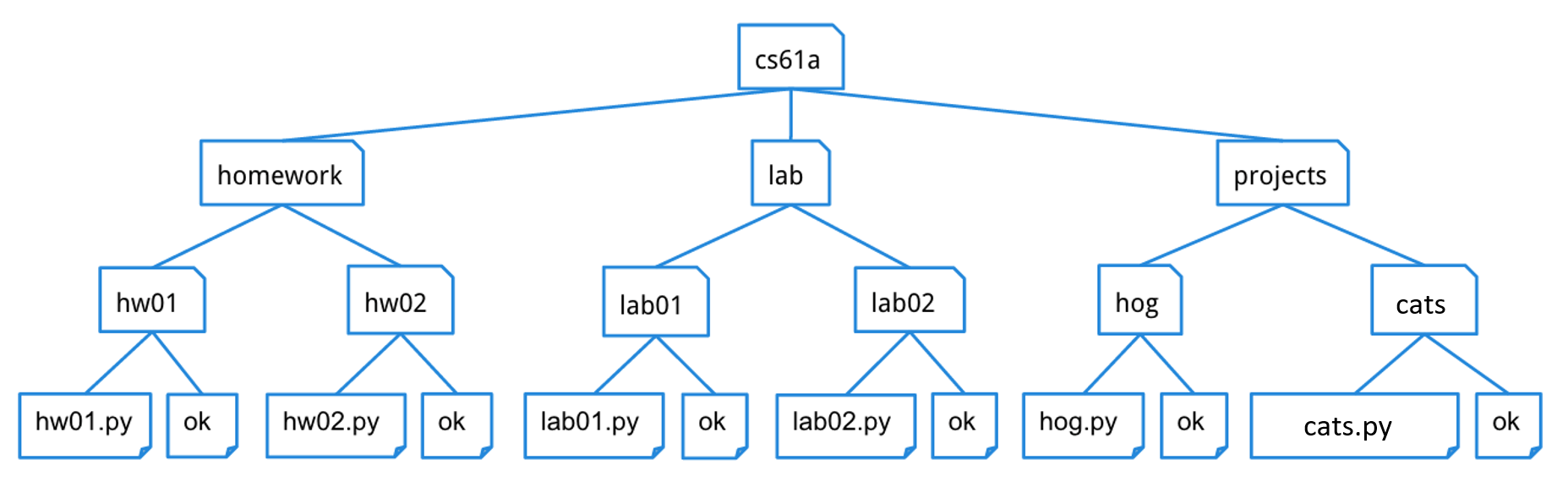
As you can see, unlike trees in nature, the tree abstract data type is drawn with the root at the top and the leaves at the bottom.
Some tree terminology:
- root: the node at the top of the tree
- label: the value in a node, selected by the
labelfunction - branches: a list of trees directly under the tree's root, selected by the
branchesfunction - leaf: a tree with zero branches
- node: any location within the tree (e.g., root node, leaf nodes, etc.)
Our tree abstract data type consists of a root and a list of its
branches. To create a tree and access its root value and branches, use the
following constructor and selectors:
Constructor
tree(label, branches=[]): creates a tree object with the givenlabelvalue at its root node and list ofbranches. Notice that the second argument to this constructor,branches, is optional - if you want to make a tree with no branches, leave this argument empty.
Selectors
label(tree): returns the value in the root node oftree.branches(tree): returns the list of branches of the giventree.
Convenience function
is_leaf(tree): returnsTrueiftree's list ofbranchesis empty, andFalseotherwise.
For example, the tree generated by
number_tree = tree(1,
[tree(2),
tree(3,
[tree(4),
tree(5)]),
tree(6,
[tree(7)])])would look like this:
1
/ | \
2 3 6
/ \ \
4 5 7To extract the number 3 from this tree, which is the label of the root of its second branch, we would do this:
label(branches(number_tree)[1])The print_tree function prints out a tree in a
human-readable form. The exact form follows the pattern illustrated
above, where the root is unindented, and each of its branches is
indented one level further.
def print_tree(t, indent=0):
"""Print a representation of this tree in which each node is
indented by two spaces times its depth from the root.
>>> print_tree(tree(1))
1
>>> print_tree(tree(1, [tree(2)]))
1
2
>>> numbers = tree(1, [tree(2), tree(3, [tree(4), tree(5)]), tree(6, [tree(7)])])
>>> print_tree(numbers)
1
2
3
4
5
6
7
"""
print(' ' * indent + str(label(t)))
for b in branches(t):
print_tree(b, indent + 1)Required Questions
Lists
Q1: Coordinates
Implement a function coords that takes a function fn, a sequence seq,
and a lower and upper bound on the output of the function. coords then
returns a list of coordinate pairs (lists) such that:
- Each (x, y) pair is represented as
[x, fn(x)] - The x-coordinates are elements in the sequence
- The result contains only pairs whose y-coordinate is within the upper and lower bounds (inclusive)
See the doctest for examples.
Note: your answer can only be one line long. You should make use of list comprehensions!
def coords(fn, seq, lower, upper):
"""
>>> seq = [-4, -2, 0, 1, 3]
>>> fn = lambda x: x**2
>>> coords(fn, seq, 1, 9)
[[-2, 4], [1, 1], [3, 9]]
"""
"*** YOUR CODE HERE ***"
return ______
Use Ok to test your code:
python3 ok -q coordsQ2: Riffle Shuffle
The familiar riffle shuffle of a deck of cards (or in our case, of a sequence of things) results in a new configuration of cards in which the top card is followed by the middle card, then by the second card, then the card after the middle, and so forth. Assuming the deck (sequence) contains an even number of cards, write a list comprehension that produces the shuffled sequence.
{kind=link}
Hint: To write this as a single comprehension, you may find the expression
k%2, which evaluates to 0 on even numbers and 1 on odd numbers, to be useful.
Consider how you can use the 0 or 1 returned by k%2 to alternatively access the
beginning and the middle of the list.
def riffle(deck):
"""Produces a single, perfect riffle shuffle of DECK, consisting of
DECK[0], DECK[M], DECK[1], DECK[M+1], ... where M is position of the
second half of the deck. Assume that len(DECK) is even.
>>> riffle([3, 4, 5, 6])
[3, 5, 4, 6]
>>> riffle(range(20))
[0, 10, 1, 11, 2, 12, 3, 13, 4, 14, 5, 15, 6, 16, 7, 17, 8, 18, 9, 19]
"""
"*** YOUR CODE HERE ***"
return _______
Use Ok to test your code:
python3 ok -q riffleTrees
Q3: Finding Berries!
The squirrels on campus need your help! There are a lot of trees on campus and
the squirrels would like to know which ones contain berries. Define the function
berry_finder, which takes in a tree and returns True if the tree contains a
node with the value 'berry' and False otherwise.
Hint: Considering using a for loop to iterate through each of the branches recursively!
def berry_finder(t):
"""Returns True if t contains a node with the value 'berry' and
False otherwise.
>>> scrat = tree('berry')
>>> berry_finder(scrat)
True
>>> sproul = tree('roots', [tree('branch1', [tree('leaf'), tree('berry')]), tree('branch2')])
>>> berry_finder(sproul)
True
>>> numbers = tree(1, [tree(2), tree(3, [tree(4), tree(5)]), tree(6, [tree(7)])])
>>> berry_finder(numbers)
False
>>> t = tree(1, [tree('berry',[tree('not berry')])])
>>> berry_finder(t)
True
"""
"*** YOUR CODE HERE ***"
Use Ok to test your code:
python3 ok -q berry_finderQ4: Sprout leaves
Define a function sprout_leaves that takes in a tree, t, and a list of
leaves, leaves. It produces a new tree that is identical to t, but where each
old leaf node has new branches, one for each leaf in leaves.
For example, say we have the tree t = tree(1, [tree(2), tree(3, [tree(4)])]):
1
/ \
2 3
|
4If we call sprout_leaves(t, [5, 6]), the result is the following tree:
1
/ \
2 3
/ \ |
5 6 4
/ \
5 6def sprout_leaves(t, leaves):
"""Sprout new leaves containing the data in leaves at each leaf in
the original tree t and return the resulting tree.
>>> t1 = tree(1, [tree(2), tree(3)])
>>> print_tree(t1)
1
2
3
>>> new1 = sprout_leaves(t1, [4, 5])
>>> print_tree(new1)
1
2
4
5
3
4
5
>>> t2 = tree(1, [tree(2, [tree(3)])])
>>> print_tree(t2)
1
2
3
>>> new2 = sprout_leaves(t2, [6, 1, 2])
>>> print_tree(new2)
1
2
3
6
1
2
"""
"*** YOUR CODE HERE ***"
Use Ok to test your code:
python3 ok -q sprout_leavesQ5: Don't violate the abstraction barrier!
Note: this question has no code-writing component (if you implemented
berry_finderandsprout_leavescorrectly!)
When writing functions that use an ADT, we should use the constructor(s) and selector(s) whenever possible instead of assuming the ADT's implementation. Relying on a data abstraction's underlying implementation is known as violating the abstraction barrier, and we never want to do this!
It's possible that you passed the doctests for berry_finder and sprout_leaves
even if you violated the abstraction barrier. To check whether or not you
did so, run the following command:
Use Ok to test your code:
python3 ok -q check_abstractionThe check_abstraction function exists only for the doctest, which swaps
out the implementations of the tree abstraction with something else, runs
the tests from the previous two parts, then restores the original abstraction.
The nature of the abstraction barrier guarantees that changing the implementation of an ADT shouldn't affect the functionality of any programs that use that ADT, as long as the constructors and selectors were used properly.
If you passed the Ok tests for the previous questions but not this one, the fix is simple! Just replace any code that violates the abstraction barrier, i.e. creating a tree with a new list object or indexing into a tree, with the appropriate constructor or selector.
Make sure that your functions pass the tests with both the first and the second implementations of the Tree ADT and that you understand why they should work for both before moving on.
Submit
Make sure to submit this assignment by running:
python3 ok --submitOptional Questions
Q6: Add trees
Define the function add_trees, which takes in two trees and returns a new
tree where each corresponding node from the first tree is added with the node
from the second tree. If a node at any particular position is present in one
tree but not the other, it should be present in the new tree as well.
Hint: You may want to use the built-in zip function to iterate over multiple sequences at once.
Note: If you feel that this one's a lot harder than the previous tree problems, that's totally fine! This is a pretty difficult problem, but you can do it! Talk about it with other students, and come back to it if you need to.
def add_trees(t1, t2):
"""
>>> numbers = tree(1,
... [tree(2,
... [tree(3),
... tree(4)]),
... tree(5,
... [tree(6,
... [tree(7)]),
... tree(8)])])
>>> print_tree(add_trees(numbers, numbers))
2
4
6
8
10
12
14
16
>>> print_tree(add_trees(tree(2), tree(3, [tree(4), tree(5)])))
5
4
5
>>> print_tree(add_trees(tree(2, [tree(3)]), tree(2, [tree(3), tree(4)])))
4
6
4
>>> print_tree(add_trees(tree(2, [tree(3, [tree(4), tree(5)])]), \
tree(2, [tree(3, [tree(4)]), tree(5)])))
4
6
8
5
5
"""
"*** YOUR CODE HERE ***"
Use Ok to test your code:
python3 ok -q add_treesFun Question!
Shakespeare and Dictionaries
We will use dictionaries to approximate the entire works of Shakespeare! We're going to use a bigram language model. Here's the idea: We start with some word -- we'll use "The" as an example. Then we look through all of the texts of Shakespeare and for every instance of "The" we record the word that follows "The" and add it to a list, known as the successors of "The". Now suppose we've done this for every word Shakespeare has used, ever.
Let's go back to "The". Now, we randomly choose a word from this list, say "cat". Then we look up the successors of "cat" and randomly choose a word from that list, and we continue this process. This eventually will terminate in a period (".") and we will have generated a Shakespearean sentence!
The object that we'll be looking things up in is called a "successor table", although really it's just a dictionary. The keys in this dictionary are words, and the values are lists of successors to those words.
Q7: Successor Tables
Here's an incomplete definition of thebuild_successors_table
function. The input is a list of words (corresponding to a
Shakespearean text), and the output is a successors table. (By default,
the first word is a successor to "."). See the example below.
Note: there are two places where you need to write code, denoted by the two
"*** YOUR CODE HERE ***"
def build_successors_table(tokens):
"""Return a dictionary: keys are words; values are lists of successors.
>>> text = ['We', 'came', 'to', 'investigate', ',', 'catch', 'bad', 'guys', 'and', 'to', 'eat', 'pie', '.']
>>> table = build_successors_table(text)
>>> sorted(table)
[',', '.', 'We', 'and', 'bad', 'came', 'catch', 'eat', 'guys', 'investigate', 'pie', 'to']
>>> table['to']
['investigate', 'eat']
>>> table['pie']
['.']
>>> table['.']
['We']
"""
table = {}
prev = '.'
for word in tokens:
if prev not in table:
"*** YOUR CODE HERE ***"
"*** YOUR CODE HERE ***"
prev = word
return tableUse Ok to test your code:
python3 ok -q build_successors_tableQ8: Construct the Sentence
Let's generate some sentences! Suppose we're given a starting word. We can look up this word in our table to find its list of successors, and then randomly select a word from this list to be the next word in the sentence. Then we just repeat until we reach some ending punctuation.
Hint: to randomly select from a list, import the Python random library with
import randomand use the expressionrandom.choice(my_list)
This might not be a bad time to play around with adding strings
together as well. Let's fill in the construct_sent function!
def construct_sent(word, table):
"""Prints a random sentence starting with word, sampling from
table.
>>> table = {'Wow': ['!'], 'Sentences': ['are'], 'are': ['cool'], 'cool': ['.']}
>>> construct_sent('Wow', table)
'Wow!'
>>> construct_sent('Sentences', table)
'Sentences are cool.'
"""
import random
result = ''
while word not in ['.', '!', '?']:
"*** YOUR CODE HERE ***"
return result.strip() + wordUse Ok to test your code:
python3 ok -q construct_sentPutting it all together
Great! Now let's try to run our functions with some actual data. The following snippet included in the skeleton code will return a list containing the words in all of the works of Shakespeare.
Warning: Do NOT try to print the return result of this function.
def shakespeare_tokens(path='shakespeare.txt', url='http://composingprograms.com/shakespeare.txt'):
"""Return the words of Shakespeare's plays as a list."""
import os
from urllib.request import urlopen
if os.path.exists(path):
return open('shakespeare.txt', encoding='ascii').read().split()
else:
shakespeare = urlopen(url)
return shakespeare.read().decode(encoding='ascii').split()Uncomment the following two lines to run the above function and build the successors table from those tokens.
# Uncomment the following two lines
# tokens = shakespeare_tokens()
# table = build_successors_table(tokens)Next, let's define a utility function that constructs sentences from this successors table:
>>> def sent():
... return construct_sent('The', table)
>>> sent()
" The plebeians have done us must be news-cramm'd."
>>> sent()
" The ravish'd thee , with the mercy of beauty!"
>>> sent()
" The bird of Tunis , or two white and plucker down with better ; that's God's sake."Notice that all the sentences start with the word "The". With a few
modifications, we can make our sentences start with a random word. The
following random_sent function (defined in your starter file) will
do the trick:
def random_sent():
import random
return construct_sent(random.choice(table['.']), table)Go ahead and load your file into Python (be sure to use the -i flag).
You can now call the random_sent function to generate random
Shakespearean sentences!
>>> random_sent()
' Long live by thy name , then , Dost thou more angel , good Master Deep-vow , And tak'st more ado but following her , my sight Of speaking false!'
>>> random_sent()
' Yes , why blame him , as is as I shall find a case , That plays at the public weal or the ghost.'