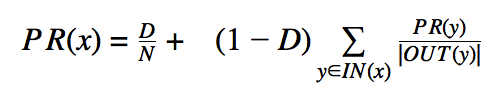
TA: Charles Reiss
Part 1 Due: Saturday 16 October 2010 23:59:59
Part 2 Due: Saturday 23 October 2010 23:59:59
Last update:
3:30PM 23 October (Changelog: ./pagerank-local.sh -> bash ./pagerank-local.sh for those with wrong executable bits.)
1:25PM 23 October (Changelog: Modify instructions to avoid hitting our S3 bucket limit.)
1:00PM 23 October (Changelog: M -> MiB)
1:10PM 22 October (Changelog: Add note about running “s3cmd mb s3://YOUR-USERNAME/” if s3cmd put returns an error about a bucket not existing.)
11:30AM 22 October (Changelog: Added note about read_value() reusing buffers, which necessitates copying the strings it returns in some cases.)
10:00PM 21 October (Changelog: Specify that throughput number should be in terms of the size of the original input; the size of the intermediate outputs need not be taken into account.)
10:45PM 20 October (Changelog: Add big input tester (appendix b).)
8:00PM 19 October (Changelog: Record runtimes, etc into part2.txt not part3.txt.)
10:15PM 17 October (Changelog: step1 through step10 is 10 things, not 11.)
[Remaining Changes in Appendix C]
PageRank is an algorithm for estimating the importance of a website based on how web sites link to it. Named after Larry Page, it is the principle algorithm that led to the initial high accuracy of the Google search engine when the company started, and Google has a patent on it.
The model is based on a hypothetical random web surfer: this random web surfer starts at an random web page and chooses a link to follow on that webpage at random. To deal with the issue of websites which do not link to other websites, the random web surfer also has a chance of choosing a new web page at random rather than following a link. PageRank attempts to approximate the probability that this random web browser would be at a web page at any particular step.
So if
then
A good strategy to approximate each PR(x) iteratively as follows:
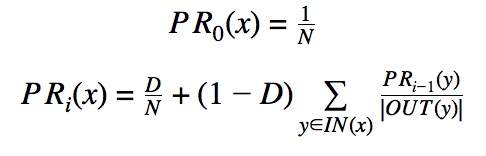
Assignment
You will write a MapReduce job that will compute the values for one of these iterations and produce intermediate values for the next. This is the equivalent of what Google does after a web crawl, to help decide how to rank the answers to a search query.
We will provide input files with key-value pairs of (URL of source page, URL of destination page) that describe all web links found in a corpus. These pairs will be the entire input to the MapReduce job for the first iteration, and the list of links combined with the output for the first iteration will be the input for the second iteration, and so on. The MapReduce job for the final iteration should output key-value pairs of (URL of page, PRi (page)), where is i is one less than the number of iterations (so if two MapReduce jobs are run the result will be PR1, not PR2).
(Added 10 Oct:) Since it is to be suitable for input for the next job, reducers running in intermediate jobs should output something different than reducers running in final jobs. (We provide a way for your reducer to know if it’s the last job in the chain.)
To simplify this task, we will assume that the number of pages is supplied externally (you will not need to compute and distribute it) and we will assume that there are no pages without outgoing links or with duplicate outgoing links.
We also will not require your implementation to renormalize the results: While your implementation should end up converging to some value for each page’s page rank, it is possible that the sum of the page ranks you compute will not be close to 1 due to accumulated rounding errors. In a real implementation, one could solve this problem by renormalizing the page ranks periodically. You don’t have to do that in this project.
(Added 10 Oct:) With these simplifications, a mapper function that emits the key-value pairs it is input is all that is necessary. The scripts we have provided will use a built-in mapper implementation that does this for each step, so you will not need to write a mapper function for this assignment.
NOTE (added 11 October): As a slight generalization of the model of reducers presented in lecture, reducers in Hadoop emit key-value pairs rather than just values for their input key. Thus, your reducer can choose to emit values for keys other than its input key. (With the interface presented in lecture, we could instead use a mapper that ignores the key and splits its value into a key-value pair to achieve the same effect.)
NOTE (added 16 October): Please count a page linking to itself as both an outgoing and incoming link to the page. Since this was specified late, we will not deduct points if you handle self-links in another way, but following this strategy will avoid our supplied inputs having pages with no outgoing links.
Copy the directory ~cs61c/proj/02:
cp -r ~cs61c/proj/02 proj2
You will find the following files in this directory:
Makefile lets you compile and link all the programs for this lab by typing “make”. You can use “make clean” to remove all compiled object files and programs.
Programs you will need to finish
pagerank-reducer.c contains an unfinished implementations for each step of page rank. We will change an environment variable before running pagerank-reducer for the last and first steps so it can behave differently on the last iterations than the prior ones.
pagerank-combiner.c contains a dummy implementation of a combiner for the PageRank job. A combiner is a reduce-like program run on partial map (or combiner) output to reduce the volume of data written to disk or sent over the network for reducers. Hadoop will sometimes run the combiner before it writes values to disk in the mapper and before it sends values over a network from mappers to reducers and at some other times.
Library functions we have provided
common.h and common.c contain utility functions for writing Hadoop Streaming jobs. common.h also includes some useful constants for this PageRank task:
Templates for using the functions in common.h are already provided in the project. The basic functions are:
Note (added 22 October): These functions use static arrays to store the keys and values they return. Consequently, the string returned by one call to read_value() will be overwritten by the next call to read_value(), so you will need to make a copy of the values you wish to keep past the next call to read_value(). (The same applies if you wish to keep a key past the next call to read_key().)
Scripts for running MapReduce jobs
pagerank-local.sh contains a shell script for running your compiled PageRank program on a lab machine. (That is, it runs Hadoop Streaming in local mode the appropriate number of times using the built-in Hadoop’s built-in IdentityMapper (passes through all key-value pairs), pagerank-combiner, and pagerank-reducer.) You should run it as follows:
bash ./pagerank-local.sh NUMBER-OF-STEPS NUMBER-OF-PAGES INPUT-FILE OUTPUT-DIRECTORY PREFIX
Where NUMBER-OF-STEPS is the number of steps to run (1 step should result in all PR0’s), NUMBER-OF-PAGES is the number of pages to assume, INPUT-FILE is a file of “link-source<tab>destination” lines, OUTPUT-DIRECTORY is a directory to put the results of all steps and the final output, and the optional PREFIX is the prefix to pass to grep-mapper to extract from the last iteration of the MapReduce job. (If none is supplied, the grep mapper will not run.)
pagerank-ec2.sh is a shell script suitable for running your compiled PageRank program on a cluster on EC2, similar to the script we used to run wordcount + sort in the EC2 lab
grep-mapper.c contains finished code for a mapper that pass through keys starting with a string specified by an environment variable. The shell scripts will use this to postprocess your output to extract the page rank of a particular set of websites.
Note on Environment Variables used by Templates
Our template code receives values like the number of pages and whether it is the first or last step through environment variables. It supplies the necessary values of these environment variables through local variables in the PageRank reducer and combiner templates. The environment variables are:
Testing your Reducer/Combiner Alone
To test your mapper or reducer or combiner program at the command-line, you can pass environment variables and supply input using something like:
PAGES=10 FIRST_STEP=true ./pagerank-reducer <test.reducer.in
(where test.reducer.in is your test input input file, with the key-value pairs for the same key placed next to each other.) As with the wordcount-mapper and wordcount-reducer program we used in lab, the PageRank mapper and reducer input is in the form “key\tvalue” (one per line) and output is in the form “key\tvalue” (one per line). (\t represents a literal tab character. Other types of whitespace will not work.)
Part 1: Intermediate Output Design DUE 16 OCTOBER
Write the answers to these questions in a file called “part1.txt”:
A B
B C
B A
C A
C D
D C
should be after the first iteration assuming there is another iteration afterwards.
Note that you will probably need to have both values that are URLs and values that are floating point numbers. We recommend using a leading “#” to mark the numbers (when mixed with URLs), which we guarantee we will never start a URL with. (When you write your C code, you can convert between strings and floats with atof and between floats and strings with sprintf.)
In your directory with part1.txt run:
submit proj2-1
Having answered the questions above, you should have some idea how to finish pagerank-reducer.c and pagerank-combiner.c. Do so.
Test your code locally by either running it manually or by running the ./pagerank-local.sh script we have provided.
One test case is:
A B
B A
B C
C B
C D
D E
E D
Make a file with that content (one key-value pair per line, with a tab (the C ‘\t’ character; other whitespace will not work) between key and value) and run your pagerank-reducer.c and pagerank-combiner.c on it with
bash ./pagerank-local.sh 10 5 INPUT-FILE OUTPUT-DIRECTORY
If your reducer, combiner and mapper didn’t crash, this should create the output directory, which should contain ten directores, step1 through step10. Each will contain a file called part-00000 with the output of that step. The output of your final step should be similar to:
A 0.095184
B 0.160703
C 0.095184
D 0.352470
E 0.296454
(Your exact values will probably differ due to floating point conversions and rounding, and you need not output to exactly this many digits.)
Now, test your results on a small crawl (9637 pages; 8.6MiB) of EECS webservers (with external links omitted) with:
bash ./pagerank-local.sh 5 9637 ~cs61c/data/eecs-crawl /tmp/YOUR-USERNAME-out
and from /tmp/YOUR-USERNAME-out/step5/part-00000 extract the values of PageRank for http://www.eecs.berkeley.edu/ and for http://www.eecs.berkeley.edu/~pattrsn/ . Put these values in a file called pagerank-eecs.txt.
Part 2b: Run On EC2
We have provided an input file from a larger web crawl on EC2 in s3://cs61c-data/uscs (315191 pages, 573MiB). This is from a 2004 crawl of US CS department websites made by Stanford’s WebBase Project in 2004. Run your program for 4 iterations over this data on a cluster of 2 c1.medium ($0.16/hr, 2 cores, 2GB of RAM) instances:
(Note: the following instructions assume you have setup your EC2 access as instructed the EC2 lab.)
First upload pagerank-combiner-linux-x86 and pagerank-reducer-linux-x86 and grep-mapper-linux-x86 to your S3: bucket:
s3cmd put pagerank-combiner-linux-x86 pagerank-reducer-linux-x86 grep-mapper-linux-x86 s3://cs61c/YOUR-USERNAME/
(Changed from s3://YOUR-USERNAME/ on 23 October)
Then start your cluster:
hadoop-ec2 launch-cluster --auto-shutdown=295 YOUR-USERNAME-medium 1 nn,snn,jt,dn,tt 1 dn,tt
Upload the script pagerank-ec2.sh that we have provided
hadoop-ec2 push YOUR-USERNAME-medium pagerank-ec2.sh
Now run the script as follows:
hadoop-ec2 exec YOUR-USERNAME-medium bash pagerank-ec2.sh cs61c/YOUR-USERNAME 8 4 315191 s3n://cs61c-data/uscs uscs-crawl-out http://www.cs.berkeley.edu
(Changed “YOUR-USERNAME”after “pagerank-ec2.sh” to cs61c/YOUR-USERNAME on 23 October.)
The arguments the script takes are as follows:
After it finished the several jobs (assuming they don’t fail), it will output the start and end times as well as the end time for the copy from S3. Record these into “part2.txt”. (Note (19 October): Due to an error, this previously said “part3.txt”.) It will also deposit the extracted output in your S3 bucket in the directory “uscs-crawl-out” in the S3 directory “s3://cs61c/YOUR-USERNAME/uscs-crawl-out/”. Download the part-00000 file and rename it to “pageranks-big.txt”.
Then shutdown your cluster with:
hadoop-ec2 terminate-cluster YOUR-USERNAME-medium
Now launch a larger (6 mediums) cluster with
hadoop-ec2 launch-cluster --auto-shutdown=295 YOUR-USERNAME-medium 1 nn,snn,jt,dn,tt 5 dn,tt
and get the timings again; this time specify a different S3 output name and 12 reducers. Terminate your cluster when you are done.
Answer to the following question in “part2.txt”:
Note (added 21 October): (This question previously just asked for the “average throughput of each iteration”.) You do not need to account for the size of the intermediate outputs in your throughput calculation. Also, it is fine to calculate this throughput based on the total time for all the pagerank iterations, ignoring any time spent waiting between iterations.
submit proj2-2
(If you created a “part3.txt” due to an earlier version of the part 2b instructions, please copy its contents into “part2.txt” for submission.)
Appendix A: Automated Testing Script
To assist students in testing their Project 2 solutions, we have made an automated testing script available. The script only tests the example given in Part 2a, but runs the reducer and combiner in ways that won’t be exercised by running Hadoop in local mode. For example:
Though we expect the autograder used for this project to be similar, we do not guarantee that no failures on the automatic testing script means a solution is correct, and it is possible that the script has some bugs that will cause it erroneously fail correct programs.
To run the automatic testing script, run ‘proj2-tester’ in the directory with your compiled pagerank-combiner and pagerank-reducer programs. The script also takes some options to give more details about the tests it is running, run ‘proj2-tester --help’ for a description of them.
Appendix B: Maximums Testing Script
To assist students whose code mysteriously fails on the larger dataset on EC2 and otherwise appears to work locally, we have also provided a testing script that runs the programs with very large inputs. Except for single-iteration runs, the numerical output is not checked. The tester attempts to test with URLs of 999 characters, with 10k outlinks from one page, and with more than 10k inlinks to one page.
This testing program can be run by running ‘proj2-tester-big’ in the directory with the pagerank-cominber and pagerank-reducer programs. Since the test cases are large (and the testing program not very optimized), this program may take a couple minutes to complete.
Appendix C: Earlier Assignment Changelog
1:00PM 16 October (Changelog: Make instructions for running pagerank-local.sh work regardless of whether it is set executable.)
11:30AM 16 October (Changelog: Specify that self-links should be treated like normal incoming/outgoing links.)
9:45PM 15 October (Changelog: Clarify input formats for manual testing instructions.)
11:30PM 13 October (Changelog: Added description of testing script.)
3:00PM 13 October (Changelog: Added note that not running the combiner should not affect answer and that the combiner cannot change keys.)
1:20PM 13 October (Changelog: Remove extraneous “N” from first (non-iterative) page-rank formula.)
11:40AM 13 October (Changelog: Correct numbers for test case in Part 2 (previous numbers were using wrong DELTA); correct read_key() description)
8:30PM 12 October (Changelog: Also noted value of D we use in “assignment” section in addition to “framework” section.)
5:20PM 11 October (Changelog: note that Hadoop generalizes reducers to emit key-value pairs and not just values.)
11:25AM 11 October (Changelog: noted that MAX_LINK_LENGTH accounts for nul terminators.)
5:30PM 10 October (Changelog: “will be output for the second” -> “will be input for the second”; noted that we want the result after one iteration to be PR0, after two to be PR1, etc.; noted explicitly that reducers should have different output for depending on whether the iteration is the last; emphasized that another iteration occurs later in the first question in Part 1a)
11:30 AM 10 October (Changelog: Use consistent S3 filenames for crawl file in Part 2b.)
9:00 AM 10 October (Changelog: Noted explicitly that only the identity mapper is necessary.)
9:00 PM 9 October (Changelog: reorganized framework section for greater clarity.)
8:50 PM 9 October (Changelog: removed bogus references to a mapper that we won’t be using; correct number of medium instances in part 2b; describe pagerank-ec2.sh in infrastructure overview; misc typos/formatting)