CS61C Project 3: Optimize Matrix Multiply
TA: Andrew Gearhart
- You should work in groups of two for this project
- All performance data must be obtained from the machines in 200SD!!!
- Background
A researcher in the UCB Parlab has been working on a video processing application that separates foreground and background information from video data. Unfortunately, he has little background in high-performance computing and needs your domain expertise to optimize the computational bottleneck of his code: a matrix multiply. Recall that matrix multiply is of this form:
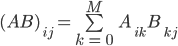
Unfortunately for the researcher, his matrix multiply has certain characteristics that makes it unsuitable for a canned library application. In particular, his matrix is single precision of dimension M = O(100000) rows and N=O(100) columns. Each of the columns represents a single video frame in grayscale, and the algorithm attempts to detect the background as pixels that do not change greatly from frame to frame. Furthermore, the matrix multiply is of the form A’*A where A’ is the transpose of A (ie. 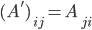 ). Thus, the matrix multiply is of this form:
). Thus, the matrix multiply is of this form:
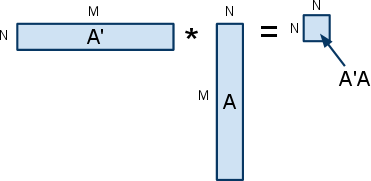
The above diagram labels the matrices with their number of rows and columns, and represents a good way to visualize the problem.
Your objective is to parallelize and optimize the matrix multiply operation described above. You will be allowed to work with partners, and submit a joint assignment. In fact, working with a partner is strongly encouraged due to the amount of work required for this project!
- Given
- Download the project materials in: ~cs61c/proj/03/matmulProject.tar.gz
- You will be provided with several codes to help you with the optimization process:
- benchmark.cpp: benchmarking and timing code
- sgemm-naive.cpp: naive matrix multiply
- sgemm-blocked.cpp: matrix multiply with one level of blocking
- sgemm-blas.cpp: GoTo BLAS implementation
- Use “export GOTO_NUM_THREADS=2” to run the Goto matrix multiply with 2 threads.
- Makefile
- Assignment
- Coding Components
- Implement a single precision (ie. using the 32-bit float type) matrix multiply with three levels of cache blocking. To do this, you may expand upon the code provided in sgemm-blocked.cpp. It is beneficial to think of the third level of blocking as occurring at the register level: i.e. you are implementing a “register blocking” that uses very small blocks in the hope of increasing the amount of register reuse accomplished by the algorithm. In this instance a “small block” will be around size 8-by-2 or 4-by-4, for example. Of course, the optimal register block dimensions are not obvious to determine. Also, you must unroll the register block multiply and place values into local variables to obtain significant performance. This so that the compiler knows that the memory accesses will not be aliased...and can place these local variables into registers.
- Once you believe you have chosen a suitable register block size (try a few sizes to see which gets the best performance), use SSE compiler intrinsics to apply SIMD parallelism to the calculation of your loop unrolled register block. Remember that in single precision you can do 4 arithmetic operations in parallel!
- Use OpenMP pragmas to parallelize your matrix multiply implementation. This should be fairly straight-forward, you should try to reorder loops and play with the “schedule” directive to try and improve scaling and overall performance.
- Deliverables
- Code: Should compile and run with given Makefile/benchmark.cpp!
- sgemm-regblock.cpp
- sgemm-sse.cpp
- sgemm-openmp.cpp
The first line of these code files should be of form:
// username1 username2 Component# Gflop
where Component# is either 1,2 or 3 and Gflop is the code performance for a matrix of size 100000x500 (and 8 threads for OpenMP). This is in case the autograder is unable to run your code, so it is critical.
- Report:
- For coding components 1 and 2, submit a 1-2 page report (called “Coding Component X”) that includes a plot of speedup (or slowdown!) of your code vs. a run of sgemm-blocked.cpp with a blocksize of 41 (Note: This blocksize only applies to sgemm-blocked.cpp. You may use your optimized block sizes in your code). Include a brief (1-2 paragraph) description of any interesting results or problems. Only submit code that implements the specific optimizations detailed above!!!!
- For coding component 3 (OpenMP), submit a 1-2 page report that includes 2 plots:
- Strong scaling: Fixed problem size of 100000x500 for 1,2,4,6,8,10,12,14,16 threads
- Weak scaling: Problem size scaled appropriately for 1,2,4,6,8,10,12,14,16 threads
Also include a brief (1-2 paragraph) description of any interesting results or problems.
- All performance results should utilize the best set of block sizes that have been determined during testing.
- Include the usernames of the group members as the first line of report submissions!!!!
- Reports should be in pdf or word format (i.e. codingComp1.pdf)
- Part 1 (Due 11/6)
- Implement the first coding component, and submit a working code and report as described in the “Deliverables” section
- Part 2 (Due 11/13)
- Implement the final two coding components, submit the code files and reports.
- Grading
- You will be graded according to three parameters:
- Correctness (1/3 of grade): Does the code implement the optimization in a way to accurately calculate the matrix multiplication?
- Performance (1/6 of grade): Graded on a curve based upon all of the class submissions.
- Analysis (1/2 of grade): Have you successfully submitted the required deliverables, and does your report demonstrate adequate understanding of the material?
- Extra Credit (Due 11/30)
- Once the performance results from Part 2 have been submitted and analyzed, top performance results for various optimizations will be posted.
- As an extra credit assignment, we will have a class competition to determine which groups can code the fastest serial and parallel matrix multiply algorithms in the class!
- Do not just resubmit your Part 2 submission to the extra credit contest! You need to implement at least one non-trivial optimization.
- Other optimizations to consider:
- further levels of cache blocking
- copies of cache/register blocks into contiguous buffers
- aligned loads for SSE
- autotuning of cache/register blocking parameters
- optimizations specific to the fact that the multiply is of form A’A
- optimize the OpenMP schedule directive
- handle fringe cases of loop unrolling
- Cache-oblivious
- Space-filling curve layout in memory
- Strassen’s algorithm
- You will be given several extra weeks for this task, and winners will achieve everlasting fame by having their performance results publicly posted during one of the final class lectures.
- Submission:
- sgemm-ec-serial.cpp AND/OR sgemm-ec-parallel.cpp
- 1-2 page report detailing the optimizations implemented and performance data similar to the Part 1/2 submissions.
- The extra credit will be provided to the following groups:
- Top 3 serial implementations (based upon GFlop values as problem size is scaled)
- Top 3 parallel implementations (based upon weak scaling values for 1,2,4,8 cores)
- References
- Goto, K., and van de Geijn, R. A. 2008. Anatomy of High-Performance Matrix Multiplication, ACM Transactions on Mathematical Software 34, 3, Article 12.
- Chellappa, S., Franchetti, F., and Püschel, M. 2008. How To Write Fast Numerical Code: A Small Introduction, Lecture Notes in Computer Science 5235, 196–259.
- Bilmes, et al. The PHiPAC (Portable High Performance ANSI C) Page for BLAS3 Compatible Fast Matrix Matrix Multiply.
- Lam, M. S., Rothberg, E. E, and Wolf, M. E. 1991. The Cache Performance and Optimization of Blocked Algorithms, ASPLOS'91, 63–74.
- Single precision SSE reference: <http://msdn.microsoft.com/en-us/library/yc6byew8%28v=VS.80%29.aspx>
- OpenMP reference sheet: <http://www.plutospin.com/files/OpenMP_reference.pdf>
- OpenMP Reference Page from LLNL:
<https://computing.llnl.gov/tutorials/openMP>