CS 61C Lab 4b
Thread Level Parallelism with OpenMP
Background
Goals
This lab will give you a glimpse of Shared Memory Parallel Programming by using OpenMP. We will be using the lab machines in 200 Sutardja Dai, which feature:
- 2 x Quad-core 2.26 GHz Intel Xeon (8 physical cores)
- 12GB DDR3 RAM
Partners
Working with a partner is highly recommended. If you work with a partner, be sure both partners understand all aspects of your solution.
Setup
Copy the contents of ~cs61c/labs/04b to a suitable location in your home directory.
$ mkdir ~/lab $ cp -R ~cs61c/labs/04b/ ~/lab
Introduction to OpenMP
Basics
All semester we have been using the Macs in 200 Sutardja Dai, and in this lab we finally take advantage of their multiple cores. OpenMP is a parallel programming framework for C/C++ and Fortran. It has gained quite a bit of traction in recent years, primarily due to its simplicity while still providing good performance. In this lab we will be taking a quick peek at a small fraction of its features, but the links in the Additional Reference section can provide more information and tutorials for the interested.
There are many types of parallelism and patterns for exploiting it, and OpenMP chooses to use a nested fork-join model. By default, an OpenMP program is a normal sequential program, except for regions that the programmer explicitly declares to be executed in parallel. In the parallel region, the framework creates (fork) a set number of threads. Typically these threads all execute the same instructions, just on different portions of the data. At the end of the parallel region, the framework waits for all threads to complete (join) before it leaves that region and continues sequentially.
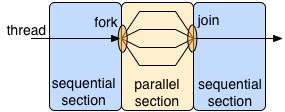
OpenMP uses shared memory, meaning all threads can access the same address space. The alternative to this is distributed memory, which is prevalent on clusters where data must be explicitly moved between address spaces. Many programmers find shared memory easier to program since they do not have to worry about moving their data, but it is usually harder to implement in hardware in a scalable way. Later in the lab we will declare some memory to be thread local (accessible only by the thread that created it) for performance reasons, but the programming framework provides the flexibility for threads to share memory without programmer effort.
Hello World Example
For this lab, we will use C to leverage our prior programming
experience with it. OpenMP is a framework with a C interface, and it is
not a built-in part of the language. Most OpenMP commands are actually
directives to the compiler. Consider the following implementation of
Hello World (hello.c):
int main() {
# pragma omp parallel
{
int thread_ID = omp_get_thread_num();
printf(" hello world %d\n", thread_ID);
}
}
This program will fork off the default number of threads and each
thread will print out "hello world" in addition to which thread number it
is. The # pragma tells the compiler that the rest of the line
is a directive, and in this case it is omp parallel.
omp declares that it is for OpenMP and parallel
says the following code block (what is contained in { }) can be executed
in parallel. Give it a try:
$ make hello $ ./hello
Notice how the numbers are not necessarily in numerical order and not
in the same order if you run hello multiple times. This is
because within a omp parallel region, the programmer
guarantees that the operations can be done in parallel, and there is no
ordering between the threads. It is also worth noting that the variable
thread_ID is local to each thread. In general with OpenMP,
variables declared outside a omp parallel block have only one
copy and are shared amongst all threads, while variables declared within a
omp parallel block have a private copy for each thread.
OpenMP Programming Exercises
Exercise 1: Vector Addition
Vector addition is a very parallel computation and it makes for a good
first exercise. The v_add function inside
v_add.c will return the array that is the cell-by-cell
addition of its inputs x and y. A first attempt
at this might look like:
void v_add(double* x, double* y, double* z) {
# pragma omp parallel
{
for(int i=0; i<ARRAY_SIZE; i++)
z[i] = x[i] + y[i];
}
}
You can run this (make v_add followed by
./v_add) and the testing framework will automatically time it
and vary the number of threads. You will see that this actually seems to
do worse as we increase the number of threads. The issue is that each
thread is executing all of the code within the omp parallel
block, meaning if we have 8 threads, we will actually be adding the
vectors 8 times. To get speedup when increasing the number of threads, we
need each thread to do less work, not the same amount as before.
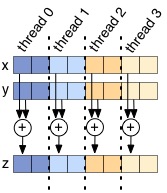
Your task is to modify v_add so there is some speedup (it
may plateau after 4). The best way to do this is to decrease the amount of
work each thread does. If there are N threads, we recommend breaking the
vectors into N contiguous chunks, and having each thread only add that
chunk (like the figure above). To aid you in this process, two useful
OpenMP functions are:
int omp_get_num_threads(); int omp_get_thread_num();
The function omp_get_num_threads() will return how many
threads there are in a omp parallel block, and
omp_get_thread_num() will return the thread ID.
For this exercise, we are asking you to manually split the work amongst
threads. Since this is such a common pattern for software, the designers
of OpenMP made the for directive to automatically split up
independent work. Here is the function rewritten using it:
void v_add(double* x, double* y, double* z) {
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<ARRAY_SIZE; i++)
z[i] = x[i] + y[i];
}
}
Checkoff
Show the TA your code for v_add that manually splits up
the work | |
| Run your code to show that it gets parallel speedup |
Exercise 2: Dot Product
The next interesting computation we want to compute is the dot product of two
vectors. At first glance, implementing this might seem not too dissimilar
from v_add, but the challenge is how to sum up all of the
products into the same variable (reduction). A naive implementation would
protect the sum with a critical section, like
(dotp.c):
double dotp(double* x, double* y) {
double global_sum = 0.0;
#pragma omp parallel
{
#pragma omp for
for(int i=0; i<ARRAY_SIZE; i++)
#pragma omp critical
global_sum += x[i] * y[i];
}
return global_sum;
}
Try out the code (make dotp and ./dotp).
Notice how the performance gets much worse as the number of
threads goes up? By putting the sum variable in a critical section, we have
flattenedthe parallelism and made it so only one thread can do useful work
at a time. This contention is problematic, and as the number of
threads goes up, so does the contention, and the performance pays the
price. Can you fix this performance bottleneck?
First, try fixing this code without using the OpenMP Reduction
keyword. Hint: Try reducing the number of times a thread must
add to the shared global_sum variable.
Now, fix the problem using the built-in Reduction keyword. Is your performance any better than in the case of the manual fix? Why?
Checkoff
Show the TA your manual fix todotp.c that gets speedup
over the single threaded case | |
Show the TA your Reduction keyword fix for dotp.c,
and explain the difference in performance. |
Exercise 3: Hello World Revisited
In this exercise, we will modify hello.c such that the
numbers print out in order. Each thread should only print out one line,
and all of the numbers should be consecutive. The number the thread prints out does
not necessarily need to be the thread ID. To accomplish this, you
will probably want to use a shared global counter (or two). Remember from
lecture the dangers of data races? We want a thread to be able to read the
counter and increment it atomically (without interference or interruption
by other threads). If this is not done atomically, two threads could end
up reading the same counter value or overwriting each other.
To help with this, OpenMP offers omp critical to provide
mutual exclusion. A critical block is placed within a
parallel block, and only one thread can execute the code
within the critical block at a time. If a thread reaches the
critical block and another thread has already entered it, it
will wait until the other thread exits before it enters.
To make this problem more challenging, we require that your solution not simply place the printf statements within a critical block.
Checkoff
Show the TA your hello.c that prints out "hello
world" in order |